&|-^l = [1,1,2,2,1,3]
s = set(l)
print(list(s)) #[1,2,3]
sets={
1,2,3,4,4,4,4,4,4,4,'a'}
# The operation behind it is
s=set({
1,2,3,4,'a'})
# If the elements repeat , Only one will be taken
print(type(s),s)
#<class 'set'> {1, 2, 3, 4, 'a'}
# Add variable type error
s={
[1,2,3],'aa'} # Report errors
# A disorderly
s = {
1,2,"b",4,"a",6,7}
print(s) #{1, 2, 4, 6, 7, 'b', 'a'}
ps : Define empty sets And Define an empty dictionary
# Define empty sets
s = set()
print(s,type(s))
#set() <class 'set'>
# Define an empty dictionary
dic = {
}
print(dic,type(dic))
#{} <class 'dict'>
# integer ---> aggregate
# res = set({1, 2, 3, 4})
res = {
1, 2, 3, 4}
print(res, type(res))
# {1, 2, 3, 4} <class 'set'>
# floating-point ---> aggregate
# res1 = set({1.1, 2.2, 3.3, 4.4})
res = {
1.1, 2.2, 3.3, 4.4}
print(res, type(res))
# {1.1, 2.2, 3.3, 4.4} <class 'set'>
# character string ---> aggregate
res = set('shawn')
print(res, type(res))
# {'a', 'h', 'n', 'w', 's'} <class 'set'>
# Tuples ---> aggregate
res = set((1, 2, 3, (1, 2, 3)))
print(res, type(res))
# {1, 2, 3, (1, 2, 3)} <class 'set'>
# Dictionaries ---> aggregate
What's in the dictionary is the collection key ( immutable )
res = set({
'name':'shawn','age':22})
print(res, type(res))
# {'name', 'age'} <class 'set'>
# integer 、 floating-point 、 character string 、 Tuples 、 comprehensive ---> aggregate
res = set((2, 1.1,"song", (111, 222)))
print(res, type(res))
#{1.1, 2, (111, 222), 'song'} <class 'set'>
When there is a dictionary in the synthesis ( Variable type ) You can't convert , And report an error
res = set((2, 1.1,"song", (111, 222),{
'name': 'shawn', 'age': 22}))
print(res, type(res)) # Report errors
# After that, we will explain it with the following example
linux=["song","hai","xing","shawn","shang"] # learn Linux Of the students
python=["shang","hai","qing","pu","qu","hi"] # learn Python Of the students
# Use "for" Loop out two students who have learned both
linux_python=[]
for s in linux:
if s in python: # Two students who study both
linux_python.append(s) # Add it to the list
print(linux_python) #["shang","hai"]
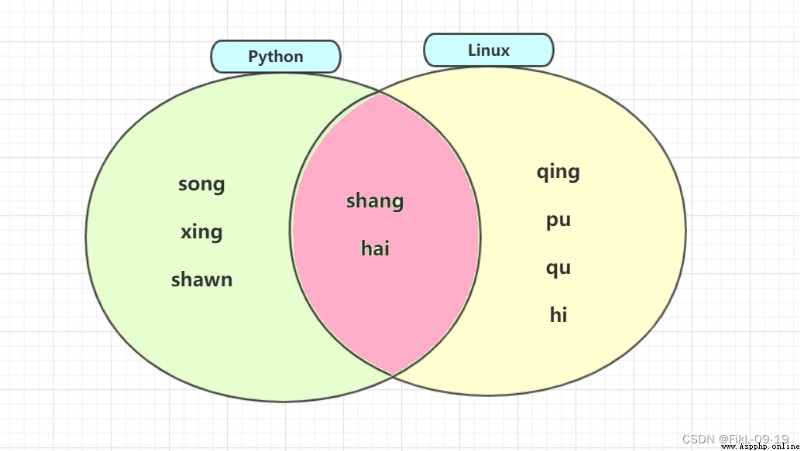
&, .intersection()# Take out the students who study both courses
linux={
"song","hai","xing","shawn","shang",}
python={
"shang","hai","qing","pu","qu","hi"}
print(linux & python) #["shang","hai"]
print(linux.intersection(python)) #["shang","hai"]
|, .union()# Take out all the students
print(linux | python)
#{'shawn', 'qing', 'hai', 'song', 'hi', 'qu', 'xing', 'shang', 'pu'}
print(linux.union(python))
#{'shawn', 'qing', 'hai', 'song', 'hi', 'qu', 'xing', 'shang', 'pu'}
-, .difference()# Just learn "linux" Of , No learning "python" Of ( stay "linux" Look in the class )
print(linux - python) #{'song', 'xing', 'shawn'}
print(linux.difference(python)) #{'song', 'xing', 'shawn'}
# Just learn "python" Of , No learning "linux" Of ( stay "python" Look in the class )
print(python - linux) #{'qing', 'qu', 'hi', 'pu'}
print(python.difference(linux)) #{'qing', 'qu', 'hi', 'pu'}
^, .symmetric_difference()# The two classes add up to look at the students who have only studied one course
print(stus_linux ^ stus_python)
# {'pu', 'qing', 'shawn', 'xing', 'song', 'qu', 'hi'}
print(stus_linux.symmetric_difference(stus_python))
# {'pu', 'qing', 'shawn', 'xing', 'song', 'qu', 'hi'}
>=, .issuperset() s1={
1,2,3,4,5}
s2={
3,2,1}
print(s1 >= s2) #True
print(s1.issuperset(s2)) #True
<=, .issubset()print(s2 <= s1)
print(s2.issubset(s1))
ps : If two are the same , Then they are father-child sets
s1=set('hello')
print(s1) #{'l','h','o','e'}
# Duplicate a list
l=['a','b',1,'a','a']
print(list(set(l))) # First of all, it becomes a collection to remove the weight , Again list Become a list
#[1,'a','b'] There is no guarantee of order
l = ['a', 'b', 1, 'a', 'a']
l2=[]
s=set()
# adopt "for" Loop one by one take , Add... One by one
for item in l:
if item not in s:
l2.append(item) #l2=['a','b',1] Add in one by one
print(l2) #['a','b','1']
s1={
1,'a','b','c','d'}
print(len(s1)) #5
s1={
1,'a','b','c','d'}
print(len(s1))
s1={
1,'a','b','c','d'}
print("c" in s1) #True
print("c" not in s1) #False
s1={
1,'a','b','c','d'}
for i in s1:
print(i)
# d
# 1
# c
# b
# a
s1={
'a','b','c'}
s1.update({
"a",3,4,5})
print(s1) # {'a','b','c',3,4,5}
s1={
'a','b','c'}
s1.add(4)
print(s1) #{'c', 'b', 'a', 4}
s={
"aaa",22,3,"bbb"}
res=s.pop()
print(s) #{3, 'aaa', 22}
print(res) #bbb
s1={
'a','b','c'}
# "remove" Delete
s1.remove(4) # Report errors
# "discard" Delete
s1.discard(4) # Don't complain
# No intersection experiment
s1={
1,2,3}
s2={
4,5,6}
print(s1.isdisjoint(s2)) #T
print(s2.isdisjoint(s1)) #T
# There's an intersection experiment
s1={
1,2,3}
s2={
4,5,6,3}
print(s1.isdisjoint(s2)) #T
print(s2.isdisjoint(s1)) #T
ps : The values in the set must be immutable
print(s1.isdisjoint(s2)) #T
print(s2.isdisjoint(s1)) #T
## Operations that don't need to know much (***)
### 1..difference_update( )
### 2..intersection_ update( )
### 3..symmetric_ difference_ update( )
## 6、 ... and . summary
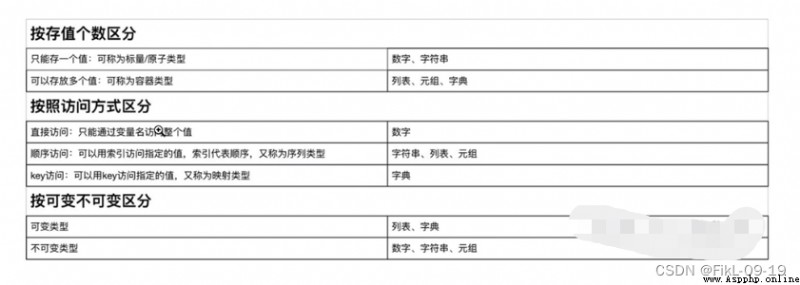
- ### You can store multiple values
- #### disorder
- #### Variable type ---> must not hash type
[ Outside the chain picture transfer in ...(img-2rHa53oA-1656084132890)]
ps : The values in the set must be immutable