簡單來說,爬蟲就是從網頁上提取信息並保存的自動化程序。
爬蟲程序的工作:
獲取網頁: 爬蟲需要先獲取網頁信息,即網頁源代碼進行後續分析。通過Python的urllib,requests等庫可以實現。
分析網頁,提取目標信息: 獲得網頁源代碼後,爬蟲會對網頁進行解析,進而提取出目標信息。
保存數據:將提取出的目標信息進行保存,以便以後使用。
當我們進入某一網站時,可能需要輸入登錄名和密碼。當我們關閉登錄過的網站後,再次進入該網頁時,並不需要再次輸入登錄信息(登錄名和密碼等),這就是Session和Cookie配合作用的結果。
先介紹一些前置概念:
- 靜態網頁和動態網頁:
什麼是靜態網頁? 在網站設計中,使用純粹的HTML格式編寫的網頁通常被稱為“靜態網頁”。還有另外一種定義:靜態網頁是相對於動態網頁而言,是指沒有後台數據庫、不含程序和不可交互的網頁。
靜態網頁的優缺點:
優點:加載速度快,編寫簡單。
缺點:可維護性差,不能根據URL靈活變換顯示的內容。
- 什麼是動態網頁?是指跟靜態網頁相對的一種網頁編程技術。其與靜態網頁的主要區別是:允許用戶與服務後台之間進行數據交互。
- 動態網頁的優缺點:
優點:靈活性更強,功能更豐富。(可以動態解析URL中參數的變化,進而呈現不同的內容。)
缺點:①在訪問速度上不占優勢。②在搜索引擎收錄方面不占優勢。
注意: 區分一個網頁是“動態”還是“靜態”,並不是根據其呈現的內容是否具有動感(輪播圖,滾動字幕等),而是根據網頁是否能與後台數據庫進行交互進行數據傳遞來判斷。
無狀態HTTP:
HTTP的無狀態是指:HTTP協議對事物處理沒有記憶能力,或者說服務器不知道客戶端是什麼狀態。
比如:我們登錄一個網站,那麼我們此時的登錄狀態便是“登錄中”。由於無狀態HTTP的特性,當我們再次請求網站時,服務器不知道我們是否登錄,所以還要在請求信息中包含我們的登錄相關信息,這會導致某些信息多次重復發送。
因此,用於保持HTTP連接狀態的技術出現了,分別時
Session和Cookie。
Session,中文稱之為會話。其本義是指有始有終的一系列動作、消息。例如:打電話時,從拿起電話撥號到掛斷電話之間的一系列過程可以成為一個Session。
Session對象用於存儲用戶Session的所需屬性及配置信息。相當於Session對象保存了當前會話的狀態。
Session存儲在服務器。當用戶發送請求到服務器時,如果沒有相應的Session對象,那麼服務器會新建一個Session對象。
Cookie,有時也用其復數形式 Cookies。類型為“小型文本文件”,是某些網站為了辨別用戶身份,進行Session跟蹤而儲存在用戶本地終端上的數據(通常經過加密),由用戶客戶端計算機暫時或永久保存的信息 。
當用戶第一次請求服務器時,服務器會返回一個響應頭中帶有
Set-Cookie字段的響應給客戶端,這個字段用於標記用戶。客戶端會把Cookie保存起來,當下一次向該服務器發送請求時,將保存的Cookie放到請求頭中傳給服務器。服務器在第一次響應客戶端請求時,創建了響應的
Session。客戶端的Cookie中保存了對應Session的ID。服務端解析客戶端發送來的Cookie可以定位到對應的Session,以此來獲取客戶端狀態。
Cookie的屬性結構以
Google Chrome浏覽器為例,進入一個網頁(比如:知乎)。按下F12進入開發者模式。左側Storage項中的Cookies子項中包含了Cookie的詳細信息。
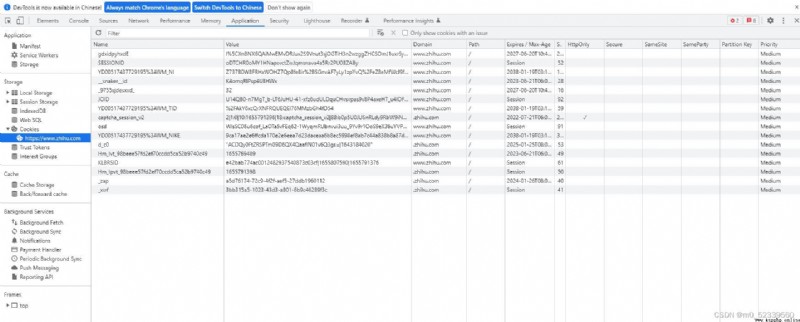
Name:
Cookie的名稱。創建後不可更改。Value:
Cookie的值。
Domain:指定可以訪問的域名。如:設置為.zhihu.com,表示所有以zhihu.com結尾的域名都可訪問。
Path:Cookie的使用路徑。
Max-Age:Cookie失效的時間,單位為秒。如果為負數,則表示浏覽器關閉後就失效。Size:
Cookie的大小
HTTP:略
Secure:略
Cookie的有效時間,有字段中的Max-Age/Expires決定。
當用戶關閉浏覽器後,位於服務端的對應的Session不會立刻消失,只有當服務器設定的Session有效時間耗盡後,Session才會由服務器刪除,以節省存儲空間。