起因是我看到一款是基於PHP寫的豆瓣插件,所以我也想同步我的豆瓣影單以及書單到博客網站上,但是豆瓣並沒有提供這樣的接口允許你獲取到自己的影單以及書單數據。那沒辦法只能自己爬數據了,剛好我對爬蟲又有點研究,這點實現起來不難。我的豆瓣影單|我的豆瓣書單
實際上不用scrapy來爬取,純python也能實現,但是我堅持在django項目裡集成scrapy,好處有三:
- 保證整個項目的完整性,所以的內容都放在當前django項目下,便於後期遷移。
- 利用
scrapy-djangoitem可以很好的通過django的orm完成數據存儲,因為後台讀取的時候也是基於model來操作的,也避免通過執行sql插入語句來完成數據插入了。- 有了scrapy這個爬蟲框架,後期站點再需要爬取什麼的時候,直接在該框架裡面再添加爬蟲即可。
那同步的問題怎麼解決呢?我想到利用celery的定時任務定時執行爬蟲不就行了,一開始我是直接將
scrapy crawl xxx寫在一個函數裡面,然後定時執行該函數,發現行不通,會提示scrapy命令找不到,可能是因為我的scrapy工程也放在了我的博客項目根目錄下。後來我就找有沒有其他的啟動scrapy爬蟲的方法,百度了許多資料但是和django放一起好像都不行,最後讓我發現了scrapyd,通過scrapyd的api也可以執行scrapy爬蟲的啊,而且scrapyd還可以部署爬蟲項目,這樣我的博客後期如果再需要爬取什麼的話,到時候部署起來也方便。
scrapyd是用來管理scrapy的部署和運行的一款服務程序,scrapyd讓我們可以通過一個簡單的Json API來完成scrapy項目的運行、停止、結束或者刪除等操作,當然它也可以同時管理多個爬蟲。這樣的我們部署scrapy時就比較方便的控制爬蟲並且查看爬蟲日志。
pip install scrapyd
pip install scrapyd-client
正常安裝完scrapyd,linux下是沒問題的,但是windows下還需要實現一個bat腳本,因為在python安裝目錄下scripts文件裡有一個scrapyd-deploy(無擴展名),這個文件是啟動文件,但是在windows下不能運行,只能在linux運行。在上述的scrapyd-deploy同級目錄下創建一個名字為scrapyd-deploy.bat的文件,內容如下:
@echo off
"F:\develop\Python\envs\blog\Scripts\python.exe" "F:\develop\Python\envs\blog\Scripts\scrapyd-deploy" %1 %2 %3 %4 %5 %6 %7 %8 %9
注意以下兩點
在當前博客根目錄下新建scrapyd文件夾(用來部署scrapy項目)
編輯scrapy項目下的scrapy.cfg文件
[settings]
default = blog.settings
[deploy:test]
url = http://localhost:6800/
project = blog
deploy後跟的是此處部署名稱,隨便取即可,project是項目名不一定要是scrapy項目名,其他名也可以。
在terminal界面切換到scrapyd目錄下執行命令scrapyd
切記只有切換到了scrapyd的目錄下這樣部署的時候內容才會存儲在該目錄下
發布工程到scrapyd(這裡的參數就必須要跟cfg裡面配置一致)scrapyd-deploy test -p blog
在scrapyd目錄下會多個三個文件夾
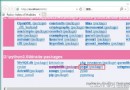
浏覽器地址欄輸入http://127.0.0.1:6800/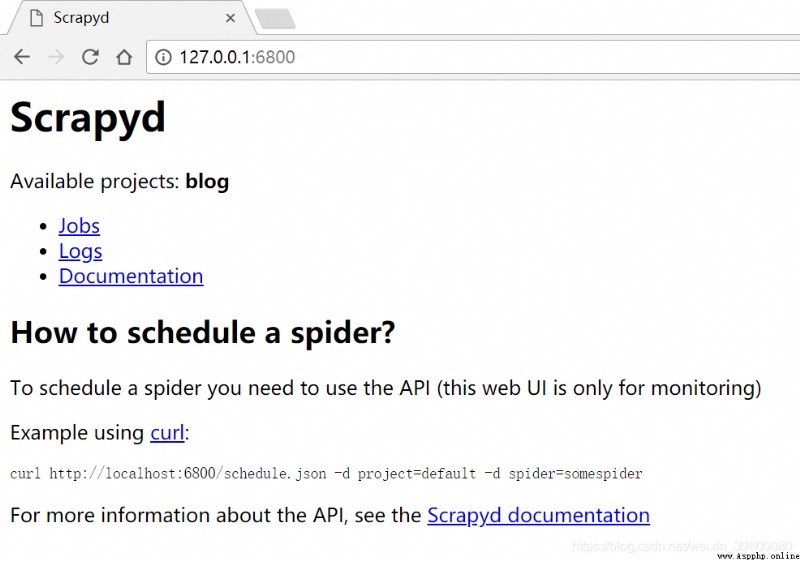 可以看到可用項目有一個blog,說明部署成功了。
可以看到可用項目有一個blog,說明部署成功了。
運行爬蟲
curl http://localhost:6800/schedule.json -d project=blog -d spider=book
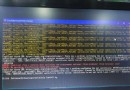
從上面的界面點擊jobs顯示如下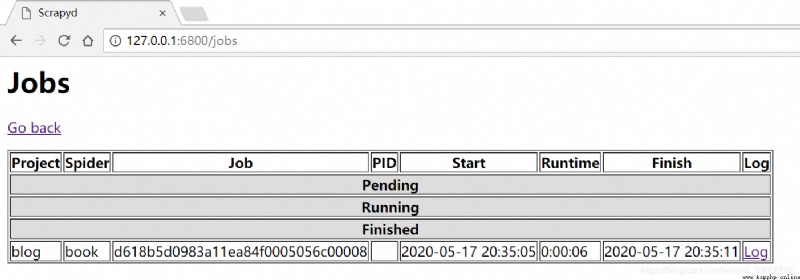 可以看到有一個爬蟲已經運行完成了,這是我爬取豆瓣書單的一個爬蟲,點擊該爬蟲最後的logs可以看到內容如下:
可以看到有一個爬蟲已經運行完成了,這是我爬取豆瓣書單的一個爬蟲,點擊該爬蟲最後的logs可以看到內容如下: 本質上內容沒有亂碼,因為我看了我存到數據庫的內容是正常的。因為scrapyd針對logs頁面請求響應頭沒有設置編碼格式,導致內容亂碼,網上解決方式也有幾種,我這裡直接用了chrome修改頁面編碼插件,改變編碼為utf-8,結果如下:
本質上內容沒有亂碼,因為我看了我存到數據庫的內容是正常的。因為scrapyd針對logs頁面請求響應頭沒有設置編碼格式,導致內容亂碼,網上解決方式也有幾種,我這裡直接用了chrome修改頁面編碼插件,改變編碼為utf-8,結果如下: 其實也可以通過post-man等restAPI訪問請求,內容也不會亂碼的。
其實也可以通過post-man等restAPI訪問請求,內容也不會亂碼的。
獲取狀態http://127.0.0.1:6800/daemonstatus.json
獲取項目列表http://127.0.0.1:6800/listprojects.json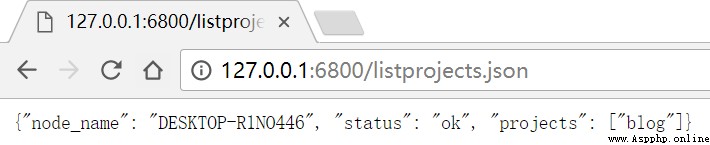
獲取某個項目下已發布的爬蟲列表http://127.0.0.1:6800/listspiders.json?project=myproject
獲取項目下已發布的爬蟲版本列表http://127.0.0.1:6800/listversions.json?project=myproject

獲取爬蟲運行狀態http://127.0.0.1:6800/listjobs.json?project=myproject
啟動服務器上某一爬蟲(需要是已部署到服務器的爬蟲)
curl語句
curl http://localhost:6800/scedule.json -d project=項目名稱 -d spider=項目名稱
python語句
import requests
req=requests.post(url="http://localhost:6800/schedule.json",data={
"project":"blog","spider":"book"})
刪除某一版本爬蟲
curl語句
import requests
http://localhost:6800/delproject.json -d project=scrapy項目名稱 -d version=scrapy項目版本號
python語句
import requests
req=requests.post(url="http://localhost:6800/delproject.json",data={
"project":"項目名","version":"項目版本號"})
刪除某一工程,包括該工程下的各版本爬蟲
curl語句
import requests
http://localhost:6800/delproject.json -d project=scrapy項目名稱
python語句
req=requests.post(url="http://localhost:6800/delproject.json",data={
"project":"項目名"})
取消爬蟲
curl語句
import requests
http://localhost:6800/cancel.json -d project=scrapy項目名稱 -d job=jobID
python語句
import requests
req=requests.post(url="http://localhost:6800/cancel.json",data={
"project":"項目名","job":"jobID"})
在根目錄下任意應用目錄下新建tasks.py文件
from __future__ import absolute_import
from celery import shared_task
import requests
@shared_task
def main():
req=requests.post(url="http://localhost:6800/schedule.json",data={
"project":"blog","spider":"movie"})
print(req.text)
切換到scrapyd部署目錄下cd scrapyd
啟動scrapydscrapyd
接下來只要設置好定時任務定時執行剛剛的tasks.py裡面的main方法即可關於如何配置celery定時任務可以參考我另外一篇關於文章django集成celery。
另外我想說的是上面的只適合在本地執行,並且需要注意一定的順序,需要開好幾個terminal分別運行celery-worker,celery-beat,scrapyd,如果用到了redis,還得再開一個redis,我目前博客已經部署上線完畢,並且豆瓣影單書單同步線上測試正常,通過supervisor來管理這些命令很方便。還有的就是關於scrapyd我也沒有開啟外網訪問,也是為了安全性考慮,也就是說不可以通過外網部署到scrapyd目錄下,不過沒事,如果新增了其他爬蟲,完全可以本地部署完畢,上線覆蓋掉原來scrapyd目錄下的內容,重啟下scrapyd即可。