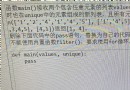
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from lxml import etree
import re,time
MONGO_URL='localhost'
MONGO_DB='jd_goods'
MONG0_TABLE='jd_goods'
from config import MONGO_DB,MONG0_TABLE,MONGO_URL
from pymongo import MongoClient
client = MongoClient(MONGO_URL)
db=client[MONGO_DB]
def main():
try:
chrome_options=Options()
chrome_options.add_argument("--headless")
browser=webdriver.Chrome(executable_path="C:\Python34\Scripts\chromedriver.exe",chrome_options=chrome_options)
browser = webdriver.Chrome()#創建谷歌浏覽器對象
wait = WebDriverWait(browser, 10)#等待對象
browser.set_window_size(1400, 900)#設置浏覽器頁面大小
total = search()
total = int(re.compile('(\d+)').search(total).group(1))
for i in range(2, total + 1):
next_page(i)
except:
print("出錯!")
finally:
browser.close()
if __name__=='__main__':
main()
def search():
try:
jd_url='https://www.jd.com/'
browser.get(jd_url)
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#key"))
)#固定用法,可參考selenium官方文檔,獲取到搜索輸入框元素
submit=wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#search > div > div.form > button > i")))#獲取到提交按鈕元素
input.send_keys("美食")#固定用法
submit.click()#完成按鈕點擊
scroll_to_down()#控制鼠標下滑,完成頁面數據全部顯示出來
total = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#J_bottomPage > span.p-skip > em:nth-child(1)"))).text#獲取到頁面底部關於頁數的文本
get_product()#解析頁面並完成存儲到mongodb
return total#返回total文本信息
except TimeoutError:
return search()#由於selenium經常報出超時錯誤,如果出現就再次運行函數
def common_click(driver,element_id,sleeptime=2):#此處代碼是網上百度的,完成頁面點擊操作
actions = ActionChains(driver)
actions.move_to_element(element_id)
actions.click(element_id)
actions.perform()
time.sleep(sleeptime)
def scroll_to_down(): #解決數據顯示不全
browser.execute_script("window.scrollBy(0,3000)")
time.sleep(1)
browser.execute_script("window.scrollBy(0,5000)")
time.sleep(1)
browser.execute_script("window.scrollBy(0,8000)")
time.sleep(1)
def next_page(page_num):
try:
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#J_bottomPage > span.p-skip > input"))
)
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#J_bottomPage > span.p-skip > a"))
)
input.clear()
input.send_keys(page_num)
submit.click()
scroll_to_down()
get_product()
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,"#J_bottomPage > span.p-num > a.curr"),str(page_num)))#判斷當前頁面高亮
except TimeoutError:
return next_page(page_num)
def get_product():
html=browser.page_source#獲取到頁面源碼
response = etree.HTML(html.lower())#方便使用xpath解析頁面
items = response.xpath('//li[@class="gl-item"]')#獲取到商品所有項
for item in items:
try:
price = item.xpath('.//div[@class="p-price"]//strong//i/text()')[0]
shop = item.xpath('.//div[@class="p-shop"]//a/text()')[0]
src = item.xpath('.//div[@class="p-img"]//a//img/@src')[0]
eva_num = item.xpath('.//div[@class="p-commit"]//strong/a/text()')[0]
title = item.xpath('.//div[@class="p-name p-name-type-2"]//a/@title')[0]
product = {
'title': title,
'src': src,
'price': price,
'eva_num': eva_num,
'shop': shop,
}
# print(product)
save_to_mongo(product)#保存到數據庫
except IndexError: #由於可能拋出數組越界,所以需要反饋異常,避免代碼終止
pass
def save_to_mongo(dict):
if db[MONG0_TABLE].insert(dict):
print('存儲到mongdb成功——————————')
return True
return False
windows下win+r打開運行界面,輸入cmd進入界面,輸入:C:\Users\童>cd C:\Program Files\MongoDB\Server\3.4\bin
即mongodb安裝路徑bin文件夾下,然後輸入:C:\Program Files\MongoDB\Server\3.4\bin>mongod -dbpath E:\mongodb\data\db
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from lxml import etree
import re,time
def search():
try:
jd_url='https://www.jd.com/'
browser.get(jd_url)
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#key"))
)#固定用法,可參考selenium官方文檔,獲取到搜索輸入框元素
submit=wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#search > div > div.form > button > i")))#獲取到提交按鈕元素
input.send_keys("美食")#固定用法
submit.click()#完成按鈕點擊
scroll_to_down()#控制鼠標下滑,完成頁面數據全部顯示出來
total = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#J_bottomPage > span.p-skip > em:nth-child(1)"))).text#獲取到頁面底部關於頁數的文本
get_product()#解析頁面並完成存儲到mongodb
return total#返回total文本信息
except TimeoutError:
return search()#由於selenium經常報出超時錯誤,如果出現就再次運行函數
def common_click(driver,element_id,sleeptime=2):#此處代碼是網上百度的,完成頁面點擊操作
actions = ActionChains(driver)
actions.move_to_element(element_id)
actions.click(element_id)
actions.perform()
time.sleep(sleeptime)
def scroll_to_down(): #解決數據顯示不全
browser.execute_script("window.scrollBy(0,3000)")
time.sleep(1)
browser.execute_script("window.scrollBy(0,5000)")
time.sleep(1)
browser.execute_script("window.scrollBy(0,8000)")
time.sleep(1)
def next_page(page_num):
try:
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#J_bottomPage > span.p-skip > input"))
)
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#J_bottomPage > span.p-skip > a"))
)
input.clear()
input.send_keys(page_num)
submit.click()
scroll_to_down()
get_product()
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,"#J_bottomPage > span.p-num > a.curr"),str(page_num)))#判斷當前頁面高亮
except TimeoutError:
return next_page(page_num)
def get_product():
html=browser.page_source#獲取到頁面源碼
response = etree.HTML(html.lower())#方便使用xpath解析頁面
items = response.xpath('//li[@class="gl-item"]')#獲取到商品所有項
for item in items:
try:
price = item.xpath('.//div[@class="p-price"]//strong//i/text()')[0]
shop = item.xpath('.//div[@class="p-shop"]//a/text()')[0]
src = item.xpath('.//div[@class="p-img"]//a//img/@src')[0]
eva_num = item.xpath('.//div[@class="p-commit"]//strong/a/text()')[0]
title = item.xpath('.//div[@class="p-name p-name-type-2"]//a/@title')[0]
product = {
'title': title,
'src': src,
'price': price,
'eva_num': eva_num,
'shop': shop,
}
# print(product)
save_to_mongo(product)#保存到數據庫
except IndexError: #由於可能拋出數組越界,所以需要反饋異常,避免代碼終止
pass
def save_to_mongo(dict):
if db[MONG0_TABLE].insert(dict):
print('存儲到mongdb成功——————————')
return True
return False
def main():
try:
chrome_options=Options()#浏覽器操作
chrome_options.add_argument("--headless")#設置無頭浏覽器
browser=webdriver.Chrome(executable_path="C:\Python34\Scripts\chromedriver.exe",chrome_options=chrome_options) #傳遞參數
browser = webdriver.Chrome()#創建谷歌浏覽器對象
wait = WebDriverWait(browser, 10)#等待對象
browser.set_window_size(1400, 900)#設置浏覽器頁面大小
total = search()
total = int(re.compile('(\d+)').search(total).group(1))
for i in range(2, total + 1):
next_page(i)
except:
print("出錯!")
finally:
browser.close()
if __name__=='__main__':
main()
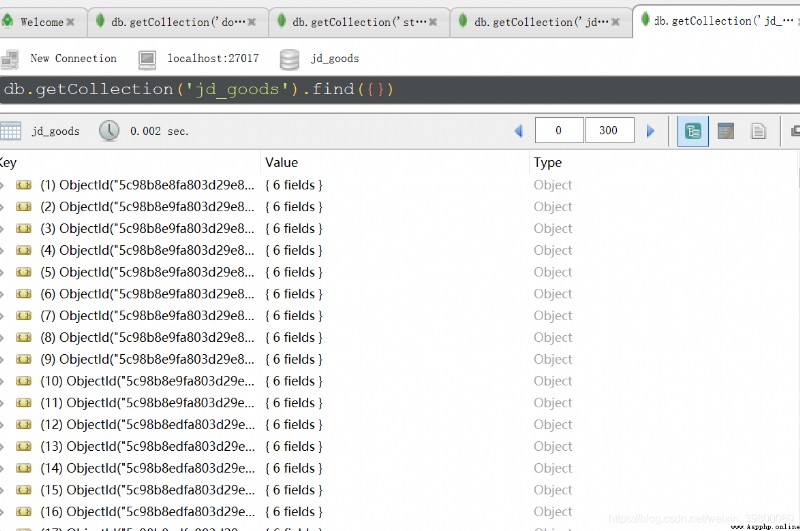
可以看到數據庫名為jd_goods下面生成一張同名的數據表