The reason is that I saw one based on PHP Write Douban plug-in , So I also want to synchronize my Douban shadow list and book list to the blog website , But Douban does not provide such an interface to allow you to obtain your own shadow list and book list data . There is no way but to climb the data by yourself , I happen to have some research on reptiles , This is not difficult to achieve . My Douban shadow list | My Douban book list
In fact, there is no need to scrapy To crawl , pure python Can also be realized , But I insist on django Project Integration scrapy, There are three advantages :
- Ensure the integrity of the whole project , All the contents are put in the current django Under the project , Easy for later migration .
- utilize
scrapy-djangoitemIt's a good way to pass django Of orm Complete data storage , Because the background reading is also based on model To operate the , Also avoid implementing sql Insert statements to complete the data insertion .- With scrapy This reptile frame , Later, when the site needs to crawl , Add crawlers directly to the framework .
How to solve the problem of synchronization ? I want to use celery It's OK to execute the crawler regularly , At the beginning, I directly put
scrapy crawl xxxWrite it in a function , Then execute the function regularly , Find it doesn't work , Will prompt scrapy Command not found , Maybe it's because of my scrapy The project is also placed in the root directory of my blog project . Then I looked for any other startup scrapy The reptile way , Baidu has a lot of information, but it is similar to django It doesn't seem to work together , Finally, I found scrapyd, adopt scrapyd Of api It can also be executed scrapy Reptilian , and scrapyd You can also deploy crawler projects , In this way, if I need to crawl something later in my blog , It will be convenient to deploy at that time .
scrapyd Is to manage scrapy The deployment and operation of a service program ,scrapyd Let's go through a simple Json API To complete scrapy Operation of the project 、 stop it 、 End or delete , Of course, it can also manage multiple crawlers at the same time . So we deploy scrapy It is convenient to control the crawler and view the crawler log .
pip install scrapyd
pip install scrapyd-client
After normal installation scrapyd,linux There's no problem next time , however windows You also need to implement a bat Script , Because in python Installation directory scripts There's one in the file scrapyd-deploy( No extension ), This file is the startup file , But in windows It doesn't work under the same conditions , Only in linux function . In the above scrapyd-deploy Create a directory named scrapyd-deploy.bat The file of , The contents are as follows :
@echo off
"F:\develop\Python\envs\blog\Scripts\python.exe" "F:\develop\Python\envs\blog\Scripts\scrapyd-deploy" %1 %2 %3 %4 %5 %6 %7 %8 %9
Pay attention to the following two points
Create a new blog under the current blog root directory scrapyd Folder ( Used for deployment scrapy project )
edit scrapy Under the project of scrapy.cfg file
[settings]
default = blog.settings
[deploy:test]
url = http://localhost:6800/
project = blog
deploy Followed by the deployment name here , Just pick it up ,project It is the project name, not necessarily scrapy Project name , Other names are OK .
stay terminal Interface Switch to scrapyd Catalog Give orders scrapyd
Remember that only when you switch to scrapyd The content will only be stored in the directory when it is deployed in this way
Release project to scrapyd( The parameters here must follow cfg The configuration inside is consistent )scrapyd-deploy test -p blog
stay scrapyd There will be three more folders under the directory 
Browser address bar input http://127.0.0.1:6800/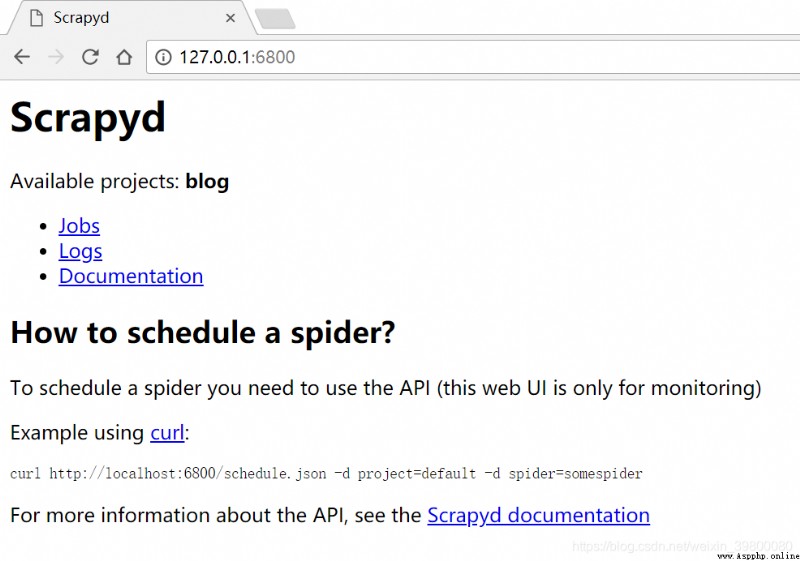 You can see that there is one available project blog, It shows that the deployment is successful .
You can see that there is one available project blog, It shows that the deployment is successful .
Run crawler
curl http://localhost:6800/schedule.json -d project=blog -d spider=book
Click... From the above interface jobs It is shown as follows  You can see that a crawler has finished running , This is a reptile that I crawled to get the Douban book list , Click on the last of the crawler logs You can see the following : Essentially, the content is not garbled , Because I saw that the content I saved in the database is normal . because scrapyd in the light of logs The page request response header has no encoding format , The content is garbled , There are also several online solutions , I use it directly here chrome Modify the page encoding plug-in , Change the code to utf-8, give the result as follows :
You can see that a crawler has finished running , This is a reptile that I crawled to get the Douban book list , Click on the last of the crawler logs You can see the following : Essentially, the content is not garbled , Because I saw that the content I saved in the database is normal . because scrapyd in the light of logs The page request response header has no encoding format , The content is garbled , There are also several online solutions , I use it directly here chrome Modify the page encoding plug-in , Change the code to utf-8, give the result as follows : In fact, it can also be through post-man etc. restAPI Access request , The content will not be garbled .
In fact, it can also be through post-man etc. restAPI Access request , The content will not be garbled .
To obtain state http://127.0.0.1:6800/daemonstatus.json
Get item list http://127.0.0.1:6800/listprojects.json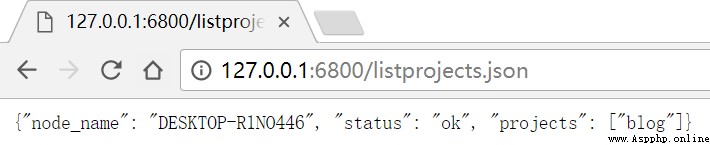
Get the list of published crawlers under a project http://127.0.0.1:6800/listspiders.json?project=myproject
Get the list of published versions of crawlers under the project http://127.0.0.1:6800/listversions.json?project=myproject

Get crawler running status http://127.0.0.1:6800/listjobs.json?project=myproject
Start a crawler on the server ( Need to be a crawler deployed to the server )
curl sentence
curl http://localhost:6800/scedule.json -d project= Project name -d spider= Project name
python sentence
import requests
req=requests.post(url="http://localhost:6800/schedule.json",data={
"project":"blog","spider":"book"})
Delete a version of crawler
curl sentence
import requests
http://localhost:6800/delproject.json -d project=scrapy Project name -d version=scrapy Project version No
python sentence
import requests
req=requests.post(url="http://localhost:6800/delproject.json",data={
"project":" Project name ","version":" Project version No "})
Delete a project , Including all versions of reptiles under the project
curl sentence
import requests
http://localhost:6800/delproject.json -d project=scrapy Project name
python sentence
req=requests.post(url="http://localhost:6800/delproject.json",data={
"project":" Project name "})
Cancel the reptile
curl sentence
import requests
http://localhost:6800/cancel.json -d project=scrapy Project name -d job=jobID
python sentence
import requests
req=requests.post(url="http://localhost:6800/cancel.json",data={
"project":" Project name ","job":"jobID"})
Create a new... In any application directory under the root directory tasks.py file
from __future__ import absolute_import
from celery import shared_task
import requests
@shared_task
def main():
req=requests.post(url="http://localhost:6800/schedule.json",data={
"project":"blog","spider":"movie"})
print(req.text)
Switch to scrapyd In the deployment Directory cd scrapyd
start-up scrapydscrapyd
Next, just set the scheduled task and execute the just tasks.py Inside main Method on how to configure celery You can refer to my other article about timed tasks django Integrate celery.
In addition, what I want to say is that the above is only suitable for local execution , And you need to pay attention to a certain order , Need to drive several terminal Run respectively celery-worker,celery-beat,scrapyd, If used redis, I have to open another one redis, My blog has been deployed and launched , And Douban shadow single book list synchronization online test is normal , adopt supervisor It is convenient to manage these commands . There is also something about scrapyd I haven't opened Internet access either , It is also for the sake of safety , That is to say, it cannot be deployed to through the Internet scrapyd Under the table of contents , But it's okay , If you add another crawler , It can be deployed locally , Go online to overwrite the original scrapyd Contents under the directory , Restart the scrapyd that will do .