一些網站會有很多的重定向,才能跳轉到真實的資源頁。然後爬蟲就會報錯:requests.exceptions.TooManyRedirects: Exceeded 30 redirects.
這種情況,可以直接關掉重定向,判斷響應狀態是301或302然後手動重定向。
參考:Python Requests:TooManyRedirects問題解決。
在手動重定向後,我又遇到了異步加載的問題。
爬取得到的頁面只有“加載中”,沒有實際內容。
出問題的網頁是:常用來爬蟲的某網站。
爬取之後得到的就只有這個:
查看網頁,可以看到數據是靠浏覽器運行JS腳本異步加載的,這時候必須要浏覽器渲染,網頁的內容才會顯示出來。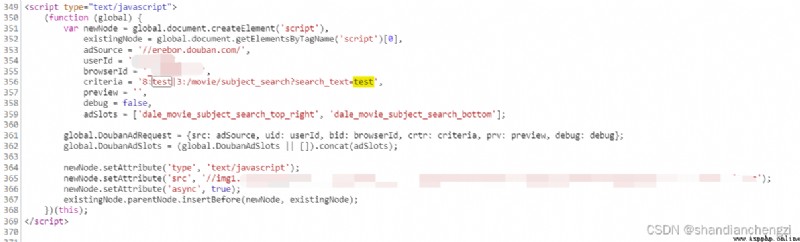
我查到兩種解決方式,一是分析源碼,然後想辦法自己渲染一下;二是使用requests-html,它提供了render渲染、提供了html異步解析。
requests-html表面上看起來非常不戳啊,好像啥都有了,可是問題是它和requests是同一個作者,requests直到今天還在更新,而requests-html兩年沒更新了,怎麼看都是個天坑吧?
那,要不結合浏覽器,咱給它模擬渲染一個吧?
默默撿起了我好久沒用的Selenium。
果然,兜兜轉轉,還是逃不過寫模擬嗎?
我的版本:
requests 2.27.1
selenium 4.2.0
Edge 102.0.1245.44
首先,用Selenium需要下載個浏覽器模擬驅動:selenium官網。
選個自己常用的浏覽器就完事了。我選的是Edge。
注意:和自己的電腦中的浏覽器版本要一致。
使用Selenium的時候遇到了以下問題:
pip3 install --upgrade requestsedge.find_elements(by="//div"),正確的是edge.find_elements(by='xpath',value="//div")。一個超簡單的能正常運行的selenium程序如下:
from selenium import webdriver
from selenium.webdriver.edge.service import Service
import requests
from time import sleep
s = Service('./edgedriver_win64/msedgedriver.exe')
edge = webdriver.Edge(service=s)
edge.get("https://movie.douban.com/subject_search?search_text=花束般的戀愛")
# requests庫,構造會話
session = requests.Session()
# 獲取cookies
cookies = edge.get_cookies()
# 填充
for cookie in cookies:
session.cookies.set(cookie['name'], cookie['value'])
# 給網頁留一點加載的時間,不然之後find不了元素
sleep(2)
detail = edge.find_elements(by='xpath', value="//div[@class='detail']")
for i in range(0, len(detail)):
title = detail[i].find_element(by='xpath', value="./div[@class='title']")
rating_nums = detail[i].find_elements(by='xpath', value="./div/span[@class='rating_nums']")
title_a = detail[i].find_element(by='xpath', value="./div[@class='title']/a").get_property('href')
if (len(rating_nums) == 0):
print(i, title.text, '暫無評分', title_a)
else:
print(i, title.text, rating_nums[0].text, title_a)
if (i >= 5): # 最多顯示6個結果就行
break
我把常用的xpath相關的、selenium相關的都盡可能在上述代碼中寫到了。
這對於學習來說,應該是一個很好的例子。
比如get_property是獲取元素的屬性。
比如xpath中的“目錄”層次,./div[@class='title'](其實和電腦的文件系統的目錄結構是一樣的,多看看就會發現這東西好簡單的)。
比如find_elements和find_element的區別。
注意:當頁面中沒有
find_element能夠找到的元素的時候,它就會直接拋出異常“invalid Locator”,而不是返回空。
所以不能確定到底有沒有的時候只能用find_elements。
給大家表演一個實際效果~
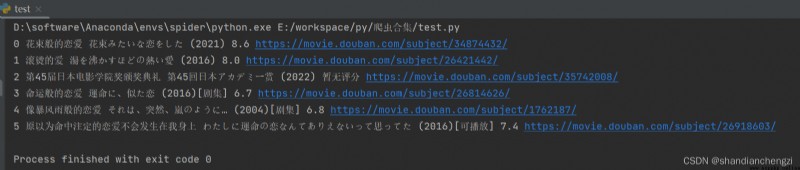
selenium的xpath語法寫得沒有lxml的簡潔,我之前一直用的是lxml解析網頁。
selenium得到的網頁→網頁文本→用lxml做元素分析,(很容易);
網頁文本→selenium的類,(很難);
所以我的建議是:干脆一直用lxml庫做網頁文本的解析,這樣更通用些,而且代碼量小很多很多。
給大伙看一下selenium和lxml的對比(上面是selenium,下面是lxml):
detail = edge.find_elements(by='xpath', value="//div[@class='detail']")
for i in range(0, len(detail)):
title = detail[i].find_element(by='xpath', value="./div[@class='title']")
rating_nums = detail[i].find_elements(by='xpath', value="./div/span[@class='rating_nums']")
title_a = detail[i].find_element(by='xpath', value="./div[@class='title']/a").get_property('href')
if (len(rating_nums) == 0):
print(i, title.text, '暫無評分', title_a)
else:
print(i, title.text, rating_nums[0].text, title_a)
if (i >= 5): # 最多顯示6個結果就行
break
下面是lxml:
from lxml import etree
html=etree.HTML(edge.page_source) # 沒錯!只要加上一行!就可以絲滑地轉換成lxml
detail = html.xpath("//div[@class='detail']")
for i in range(0, len(detail)):
title = detail[i].xpath("./div[@class='title']/a/text()")
rating_nums = detail[i].xpath("./div/span[@class='rating_nums']/text()")
title_a = detail[i].xpath("./div[@class='title']/a/@href")
if (len(rating_nums) == 0):
print(i, title[0], '暫無評分', title_a[0])
else:
print(i, title[0], rating_nums[0], title_a[0])
if (i >= 5): # 最多顯示6個結果就行
break
運行結果和上面那個程序是一樣的哈: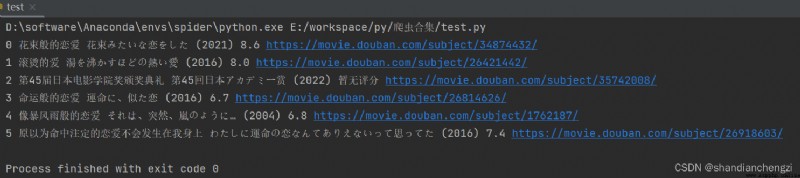
上面那個程序是直接讀selenium的網頁內容,用的是find_elements之類的。而且每次讀都要打開網頁、等待加載,這其實挺繁瑣的。
對於不是異步加載的網頁,只要個url,就可以用requests來請求了。
請求方式有好幾種:requests.get、requests.post、session.get等。
常用前兩種,但是我後來發現session的bug少一點:網頁反復重定向的時候,據說用session會話請求就不會丟失headers的內容。
session只是多一個步驟罷了。例如:
import requests
headers = {
}
sessions = requests.session() # 就多這一個步驟
sessions.headers = headers
r = sessions.get(url, headers = headers)
我寫了個比較通用的請求數據的函數,返回的是res和lxml解析的html,
有需要的話可以抱走:
from lxml import etree
def getData(url):
while (1):
res = session.get(url, headers=headers)
if (res.status_code == requests.codes.ok):
content = res.text
html = etree.HTML(content)
return res, html
elif (res.status_code == 302 or res.status_code == 301):
print(url + " --重定向到--> " + res.headers["Location"])
url = res.headers["Location"]
else:
print("出問題啦!", res.status_code)
cookieChange = int(input("是否更換Cookie(輸入1或0):"))
if (cookieChange):
headers['Cookie'] = input("請輸入Cookie:")
sleep(5)