Some websites have a lot of redirects , To jump to the real resource page . Then the crawler will report an error :requests.exceptions.TooManyRedirects: Exceeded 30 redirects.
This situation , You can turn off redirection directly , Judge that the response status is 301 or 302 Then redirect manually .
Reference resources :Python Requests:TooManyRedirects Problem solving .
After manual reset , I met again Load asynchronously The problem of .
The only pages you can crawl are “ Loading ”, No actual content .
The page with the problem is : A website often used for crawling .
This is the only thing you get after crawling :
View the web page , You can see that the data is run by the browser JS Scripts are loaded asynchronously , At this time, the browser must render , The content of the web page will be displayed .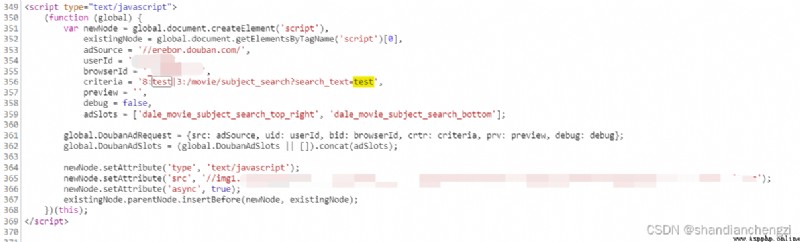
I found two solutions , First, analyze the source code , Then try to render it by yourself ; The two is the use of requests-html, It provides render Rendering 、 Provides html Asynchronous parsing .
requests-html On the surface, it doesn't seem to poke , It seems that I have everything , But the problem is that it has nothing to do with requests It's the same author ,requests It is still updated today , and requests-html It hasn't been updated for two years , It looks like a sinkhole ?
that , Do not combine with the browser , Let's give it a simulated rendering ?
Silently picked up what I had not used for a long time Selenium.
Sure enough , To work around , Still can't escape writing simulation ?
My version :
requests 2.27.1
selenium 4.2.0
Edge 102.0.1245.44
First , use Selenium You need to download a browser emulation driver :selenium Official website .
Choose your favorite browser and you're done . What I chose was Edge.
Be careful : Be consistent with the browser version in your computer .
Use Selenium I met the following problems when I was young :
pip3 install --upgrade requestsedge.find_elements(by="//div"), The right is edge.find_elements(by='xpath',value="//div").A super simple one that works selenium The procedure is as follows :
from selenium import webdriver
from selenium.webdriver.edge.service import Service
import requests
from time import sleep
s = Service('./edgedriver_win64/msedgedriver.exe')
edge = webdriver.Edge(service=s)
edge.get("https://movie.douban.com/subject_search?search_text= A bouquet of love ")
# requests library , Construct a conversation
session = requests.Session()
# obtain cookies
cookies = edge.get_cookies()
# fill
for cookie in cookies:
session.cookies.set(cookie['name'], cookie['value'])
# Give the page a little time to load , Or later find No element
sleep(2)
detail = edge.find_elements(by='xpath', value="//div[@class='detail']")
for i in range(0, len(detail)):
title = detail[i].find_element(by='xpath', value="./div[@class='title']")
rating_nums = detail[i].find_elements(by='xpath', value="./div/span[@class='rating_nums']")
title_a = detail[i].find_element(by='xpath', value="./div[@class='title']/a").get_property('href')
if (len(rating_nums) == 0):
print(i, title.text, ' No score ', title_a)
else:
print(i, title.text, rating_nums[0].text, title_a)
if (i >= 5): # Display at most 6 Just a result
break
I put the commonly used xpath dependent 、selenium As far as possible, the related code is written in the above code .
This is for learning , It should be a good example .
such as get_property Is to get the attributes of the element .
such as xpath Medium “ Catalog ” level ,./div[@class='title']( In fact, the directory structure is the same as that of the computer file system , Look more and you will find that this thing is so simple ).
such as find_elements and find_element The difference between .
Be careful : When there is no
find_elementWhen the element can be found , It just throws an exception “invalid Locator”, Instead of returning empty .
So you can only use when you are not surefind_elements.
Show us a practical effect ~
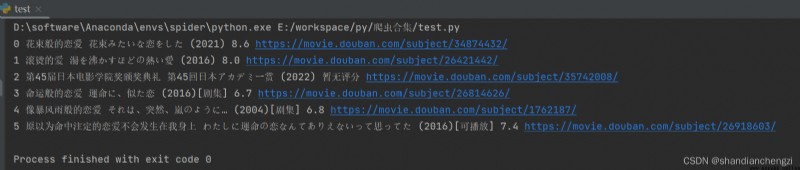
selenium Of xpath The grammar is not well written lxml The concise , I used to use lxml Parse web pages .
selenium Get page → Web page text → use lxml Do elemental analysis ,( be prone to );
Web page text →selenium Class ,( It is difficult to );
So my advice is : Just keep using lxml Library to do web page text parsing , This is more general , And the amount of code is much smaller .
Let's see selenium and lxml Comparison of ( It's on it selenium, Here is lxml):
detail = edge.find_elements(by='xpath', value="//div[@class='detail']")
for i in range(0, len(detail)):
title = detail[i].find_element(by='xpath', value="./div[@class='title']")
rating_nums = detail[i].find_elements(by='xpath', value="./div/span[@class='rating_nums']")
title_a = detail[i].find_element(by='xpath', value="./div[@class='title']/a").get_property('href')
if (len(rating_nums) == 0):
print(i, title.text, ' No score ', title_a)
else:
print(i, title.text, rating_nums[0].text, title_a)
if (i >= 5): # Display at most 6 Just a result
break
Here is lxml:
from lxml import etree
html=etree.HTML(edge.page_source) # you 're right ! Just add a line ! It can be smoothly converted into lxml
detail = html.xpath("//div[@class='detail']")
for i in range(0, len(detail)):
title = detail[i].xpath("./div[@class='title']/a/text()")
rating_nums = detail[i].xpath("./div/span[@class='rating_nums']/text()")
title_a = detail[i].xpath("./div[@class='title']/a/@href")
if (len(rating_nums) == 0):
print(i, title[0], ' No score ', title_a[0])
else:
print(i, title[0], rating_nums[0], title_a[0])
if (i >= 5): # Display at most 6 Just a result
break
The running result is the same as that of the above program :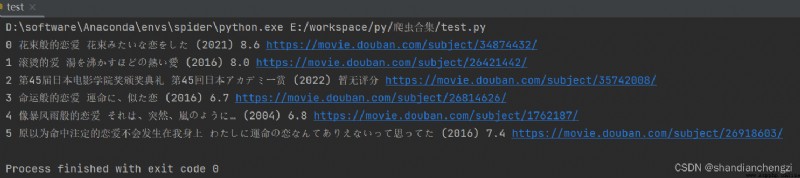
The above program is read directly selenium The web content of , It's using find_elements And so on. . And every time you read it, you have to open the web page 、 Wait for loading , This is actually quite tedious .
For pages that are not loaded asynchronously , Just one url, You can use it requests Come and ask .
There are several ways to request :requests.get、requests.post、session.get etc. .
The first two are often used , But I found out later session Of bug A little less : When the web page is redirected repeatedly , It is said that session Session requests are not lost headers The content of .
session Just one more step . for example :
import requests
headers = {
}
sessions = requests.session() # Just one more step
sessions.headers = headers
r = sessions.get(url, headers = headers)
I wrote a general function to request data , The return is res and lxml Analytic html,
You can take it away if you need it :
from lxml import etree
def getData(url):
while (1):
res = session.get(url, headers=headers)
if (res.status_code == requests.codes.ok):
content = res.text
html = etree.HTML(content)
return res, html
elif (res.status_code == 302 or res.status_code == 301):
print(url + " -- Redirect to --> " + res.headers["Location"])
url = res.headers["Location"]
else:
print(" Something's wrong !", res.status_code)
cookieChange = int(input(" Whether to replace Cookie( Input 1 or 0):"))
if (cookieChange):
headers['Cookie'] = input(" Please enter Cookie:")
sleep(5)