#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Thu Nov 2 18:38:32 2017
@author: lu
"""
import time
import pandas as pd
from sklearn.cluster import KMeans
"""
programmer_1-->進行聚類離散化
programmer_2-->None
find_rule-->定義關聯規則
connect_string-->字符串連接
"""
def programmer_1():
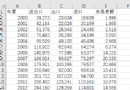
datafile = "data/data.xls"
processedfile = "tmp/data_processed.xls"
typelabel = {
u"肝氣郁結證型系數": "A",
u"熱毒蘊結證型系數": "B",
u"沖任失調證型系數": "C",
u"氣血兩虛證型系數": "D",
u"脾胃虛弱證型系數": "E",
u"肝腎陰虛證型系數": "F",
}
k = 4
data = pd.read_excel(datafile)
result = pd.DataFrame()
for key, item in typelabel.items():
print(u"正在進行“%s”的聚類..." % key)
# 進行聚類離散化
kmodel = KMeans(n_clusters&#