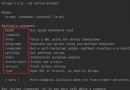
Recently used in the project Pandas Of DataFrame, Take advantage of the freshness , Organize the following knowledge , If there's something wrong , Please correct me .
This blog starts from DataFrame Create and DataFrame Emptiness of , Filter columns and other operations .
The input can be np.array, list, It can also be excel,csv etc. .
df = pd.DataFrame([[1, "aa", 12, 67, "xian"],
[2, "bb", 13, 89, "shanghai"],
[3, "cc", 12, 56, "hangzhou"],
[4, "dd", 10, 90, "suzhou"]], columns=["id", "name", "credit", "score", "city"])
print(df.head())
Output
id name credit score city
0 1 aa 12 67 xian
1 2 bb 13 89 shanghai
2 3 cc 12 56 hangzhou
3 4 dd 10 90 suzhou
Basic operations include the following
- Operations on Columns
- Air handling
- groupby
- duplicate removal
- Count different elements
- lambda Function USES
- merge
- preservation
utilize pandas Read csv file
df = pd.read_csv("./xxxx.csv")
print("df columns: ", df.columns)
print('data size: ', df.shape)
print(df.head())
df.columns = ['pclass', 'survived', 'name', 'sex', 'age', 'sibsp', 'parch', 'ticket',
'fare', 'cabin', 'embarked']
df_name = df[['name', 'sex', 'age', 'sibsp']]
df["salary"] = 10000
df.isnull().sum()
Output
pclass 1
survived 1
name 1
sex 1
age 264
sibsp 1
parch 1
ticket 1
print('"age" Proportion of missing %.2f%%' %((df['age'].isnull().sum()/df.shape[0])*100))
data = df.copy()
data["age"].fillna(df["age"].median(skipna=True), inplace=True)
data_na = df.copy()
print("data na shape: ", data_na.shape)
data_na = data_na.dropna()
print("data_na shape: ", data_na.shape)
data na shape: (1310, 12)
data_na shape: (270, 12)
data_gy = data.copy()
data_gy = data_gy[['pclass', 'survived', 'sex']].groupby(data_gy['age'])
print(data_gy.head())
(1) Aggregate operations
data_gy = data.copy()
data_gy = data_gy[['pclass', 'survived', 'sex']].groupby(data_gy['age']).mean()
print(data_gy.head())
(2) Grouping results
data_gy = data.copy()
for name, group in data_gy[['sex', 'age']].groupby('age'):
print (group)
Get rid of dataframe Repeated lines in
data = df.copy()
data = data.drop_duplicates()
Method 1:
data = df.copy()
data["age"].fillna(df["age"].median(skipna=True), inplace=True)
age_list = list(set(data['age'].values.tolist()))
print("different age: ", age_list)
Method 2:
age = data["age"].unique().tolist()
print("age set: ", age)
unique() yes dataframe Built in functions for , In case of large amount of data , Method two is faster than method one .
lambda Functions can be used for dataframe Automatically traverse the columns or rows of processing data , Than for The cycle is much faster .
df = pd.DataFrame([[1, "aa", " Physical education teaching ", 67, "xian", " Sports news reports , Liu Xiang and Yao Ming attended the afternoon activities "],
[2, "bb", " English Language Teaching ", 89, "shanghai"," The boss is fluent in English "],
[3, "cc", " teaching of language and literature ", 56, "hangzhou", " At the Chinese poetry conference, Dongqing blurted out many poems , And say your understanding of the poem "],
[4, "dd", " mathematics ", 90, "suzhou", " Image registration uses differential homeomorphism of differential geometry "]],
columns=["id", "name", "class", "score", "city", "text"])
df["tag"] = df.apply(lambda x: "A" if x["score"] >= 89 else "B" if x["score"] >=60 and x["score"] < 89 else "C", axis=1)
Output
id name class score city text tag
0 1 aa Physical education teaching 67 xian Sports news reports , Liu Xiang and Yao Ming attended the afternoon activities B
1 2 bb English Language Teaching 89 shanghai The boss is fluent in English A
2 3 cc teaching of language and literature 56 hangzhou At the Chinese poetry conference, Dongqing blurted out many poems , And say your understanding of the poem C
3 4 dd mathematics 90 suzhou Image registration uses differential homeomorphism of differential geometry A
import jieba
def get_token(x):
token_list = [token for token in jieba.cut(x['text'])]
return token_list
df['token'] = df.apply(lambda x: get_token(x), axis=1)
Output
id name class score city text \
0 1 aa Physical education teaching 67 xian Sports news reports , Liu Xiang and Yao Ming attended the afternoon activities
1 2 bb English Language Teaching 89 shanghai The boss is fluent in English
2 3 cc teaching of language and literature 56 hangzhou At the Chinese poetry conference, Dongqing blurted out many poems , And say your understanding of the poem
3 4 dd mathematics 90 suzhou Image registration uses differential homeomorphism of differential geometry
token
0 [ sports news , reports , ,, Liu xiang , Yao Ming , To attend the , Afternoon , Of , Activities ]
1 [ Boss , with , A bite of , fluent , Of , English ]
2 [ China , poetry , The conference , On , Dong Qing , Casual , Give voice , quite a lot , Verse , ,, also , Give voice , ...
3 [ Images , Registration , Use , 了 , differential , The geometric , Of , differential , Same as , embryo ]
pandas Of merge and sql Medium join similar , It is divided into left,right, inner, outer. among on Is to select which column name to associate ,how Is to select the method of association .
df_name = pd.DataFrame([["aa", " sports "],
["bb", " English "],
["cc", " Chinese language and literature "],
["dd", " mathematics "]], columns=["name", "func"])
df_new = pd.merge(df, df_name, on=["name"], how='inner')
dataframe Can be saved as csv,excel, Can also be written mysql database .
df.to_csv(" file name ", index=False, header=True, encoding="utf-8)
df.to_excel(" file name ", index=False, header=True, encoding="utf-8)
df.to_sql(' Database table name ', database, index=False, if_exists='append')