There are three types of programming languages : A compiled (C、C++、GO)、 interpreted (Python、JavaScript)、 mixed type (Java、C#)
Java Virtual machine running Python Script :Jython
Jython Is running on the Java On the platform Python Interpreter , You can directly Python Code compiled into Java Bytecode execution .
Code introduction :ASCII:8bit 1 byte ,GBK:16bit 2 byte , UNICODE:32bit 4 byte
UTF-8: Variable length unicode english :8bit The European :16bit Chinese characters :24bit
stay python Sometimes you can see the definition of a def function , Fill in the function content as pass, there pass The main function is to occupy the position , Make the code complete as a whole . If you define a function that is empty , So it's a mistake , When you haven't figured out what's inside the function , You can use it pass To fill the hole .
Python Basic data types in :- Number( Numeric type )- String( String type )- Tuple( A tuple type )- List( List the type )- Set( Collection types )- Dictionary( Dictionary type )- Bool( Boolean type )
tuple’ object does not support item assignment Tuple objects do not support item allocation
python Immutable data types and variable data types in
Immutable data types : When the value of the corresponding variable of the data type changes , Then its corresponding memory address will also change , For this data type , It's called immutable data type .
Variable data type : When the value of the corresponding variable of the data type changes , Then its corresponding memory address does not change , For this data type , Variable data types .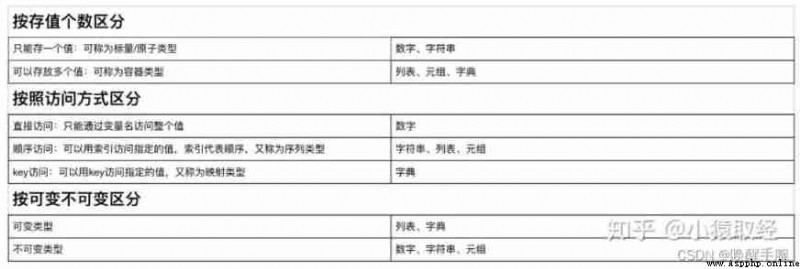
summary : The address changes after the immutable data type is changed , The address of the variable data type does not change 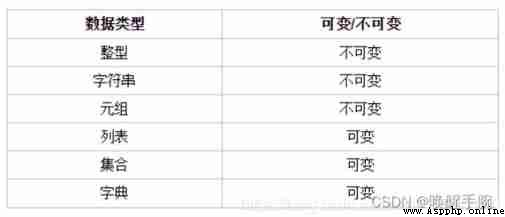
id() Returns the unique identity of the object , stay CPython Is the address of the object in memory , Two objects with non overlapping lifecycles may have the same id.
is Judge whether two objects are the same object , Logic is to judge these two objects at the same time id Are they the same? .
See the reference documentation for the function : The name of the function .__doc__
def showName(value):
""" :param value: The incoming value :return: result """
print("show myname")
print(showName.__doc__)
# return showName Function introduction document
print(str.__doc__)
# return str Function introduction document
Python Introduction to assignment operators : Incremental assignment 、 Chained assignment 、 Decompress assignment 、 Exchange assignments
# Incremental assignment :
a += 1
# Chained assignment :
a = b = c = 1
# Decompress assignment :
list = [1, 2, 3, 4, 5]
num1, num2, *num = list
# Exchange assignments :
a = 1
b = 2
a, b = b, a
Python member operator 、 Introduction to identity operator :
in : Returns if a value is found in the specified sequence True, Otherwise return to False;not in : If no value is found in the specified sequence, return True, Otherwise return to False
# member operator
print("wrist" in "my name is wrist") # True
print(" Wake up the wrist " not in "my name is wrist") # False
# Identity operator
list1 = [1, 2, 3]
list2 = [1, 2, 3]
list3 = list1
print(list1 is list2) # False
print(list1 is list3) # True
Python if Judge :if - elif - else
Base conversion :int() Decimal system 、 oct() octal 、 hex() Hexadecimal 、 bin() Binary system
String related operations : String slice 、 String segmentation 、 String to space
string = "wrist waking hello world"
string.split(" ")
# ['wrist', 'waking', 'hello', 'world']
string.split(" ", 2)
# ['wrist', 'waking', 'hello world'] 2 Is the number of switches
string[0:5:2]
# wit Before closed after opening , Head and tail ,2 It's the step length
string.strip()
# Remove the space before and after
# Left space string.lstrip() Right space string.rstrip()
string = " wrist waking hello world "
string.split(" ")
# ['', 'wrist', 'waking', 'hello', 'world', '']
# string2.rsplit Cut from right to left
string = "wrist waking hello world"
string.startswith("wrist")
# True
string.endswith("world")
# True
list = ["wrist", "waking", "I", "love", "you"]
" ".join(list)
# wrist waking I love you Can only be a string array
".".join(list)
# wrist.waking.I.love.you Can only be a string array
"12345".isdigit()
# True Judge whether it's a pure number
"12.345".isdigit()
# False Judge whether it's a pure number
with Statement is suitable for accessing resources , Make sure that the necessary... Is executed regardless of whether an exception occurs during use “ clear ” operation , Release resources , For example, the file is automatically closed after use / Automatic acquisition and release of locks in threads .
class WithTest:
def __enter__(self):
print(" Into the ".center(50, "*"))
""" exception: abnormal exception_type : Exception types exception_value : Abnormal value ( reason ) exception_traceback : Where the exception occurred ( to flash back 、 trace ) """
def __exit__(self, exc_type, exc_val, exc_tb):
print(" Exception types :", exc_type)
print(" Abnormal value :", exc_val)
print(" Where the exception occurred :", exc_tb)
print(" Out of the ".center(50, "*"))
with WithTest() as w:
print(" Before running ".center(50, "*"))
print(10 / 0)
print(" After operation ".center(50, "*"))
Traceback (most recent call last):
File "C:\Users\16204\PycharmProjects\pythonProject\file_test\with_user.py", line 19, in <module>
print(10 / 0)
ZeroDivisionError: division by zero
*********************** Into the ************************
*********************** Before running ************************
Exception types : <class 'ZeroDivisionError'>
Abnormal value : division by zero
Where the exception occurred : <traceback object at 0x0000026FFF2F8EC0>
*********************** Out of the ************************
Process finished with exit code 1
with working principle
(1) Following the with After the following statement is evaluated , Return object's “–enter–()” Method is called , The return value of this method will be assigned to as The latter variable ;
(2) When with After all the subsequent code blocks have been executed , Will call the... Of the previously returned object “–exit–()” Method .
with How it works code example :
class Sample:
def __enter__(self):
print("in __enter__")
return " Wake up the wrist "
def __exit__(self, exc_type, exc_val, exc_tb):
print("in __exit__")
def get_sample():
return Sample()
with get_sample() as sample:
print("Sample: ", sample)
# in __enter__
# Sample: Wake up the wrist
# in __exit__
You can see , The whole operation process is as follows :
(1)enter() Method is executed ;
(2)enter() Return value of method , In this case, yes ” Wake up the wrist ”, Assign a value to a variable sample;
(3) Execute code block , Print sample The value of the variable is ” Wake up the wrist ”;
(4)exit() Method is called ;
actually , stay with When the following code block throws an exception ,exit() Method is executed . When developing a library , Cleaning up resources , Close files and other operations , Can be placed in exit() In the method .
All in all ,
with - as expressionGreatly simplifies each writefinallyThe job of , This is of great help to the elegance of the code .
If there are more than one , It can be written like this :
with open('1.txt') as f1, open('2.txt') as f2:
do something
Our own classes can also with The operation of :
class A:
def __enter__(self):
print 'in enter'
def __exit__(self, e_t, e_v, t_b):
print 'in exit'
with A() as a:
print 'in with'
# in enter
# in with
# in exit
exit() Methods include 3 Parameters , exc_type、 exc_val、exc_tb, These parameters are quite useful in exception handling .exc_type: Wrong type ,exc_val: The value corresponding to the error type ,exc_tb: The location of the error in the code .
Line feed operation : stay window The system default is
"/r/n", stay Linux The operating system uses"/n", stay Mac The default operation is"/r", stay python Only add‘/n’Just go , The operating system will help us escape to the newline character for the system .
Why use documents ?
user / The application program can permanently save the data in the hard disk through the file, that is, operating the file is operating the hard disk .
user / Applications operate directly on files , All operations on the file , They're sending system calls to the operating system , Then it is converted into specific hard disk operation by operation .
How to use documents : open(), Control the mode of reading and writing content of files : t and b, emphasize : t and b Not to be used alone , Must follow r/w/a Continuous use ,t Text ( Default mode )
1、 Read and write with str (unlicode) Unit
2、 text file
3、 Must specify encoding='utf-8'
python3 The default character encoding is Unicode, The default file code is utf-8
Operation file : read / Writing documents , Applications' requests to read and write files are sent to the operating system
system call , Then the operating system controls the hard disk to read the input into the memory 、 Or write to the hard disk
f = open("helloworld.txt")
print(f)
# <_io.TextIOWrapper name='helloworld.txt' mode='r' encoding='cp936'>
# f The value of is a variable , It takes up the memory space of the application
cp936 Chinese local system is Windows Medium cmd, Default codepage yes CP936,cp936 It's the second one in the system 936 Number coding format , namely GB2312 The coding (( Of course, there are other coding formats :cp950 Traditional Chinese 、cp932 Japanese 、cp1250 Central European languages )
The default data is loaded into memory , The result is also saved in memory , End of program execution , All data is released . stay python, Use open function , You can open an existing file , Or create a new file .
# open( file name , Access pattern )
f = open("test.txt", "w")

If the file does not exist, create , If it exists, empty it first , Then write the data 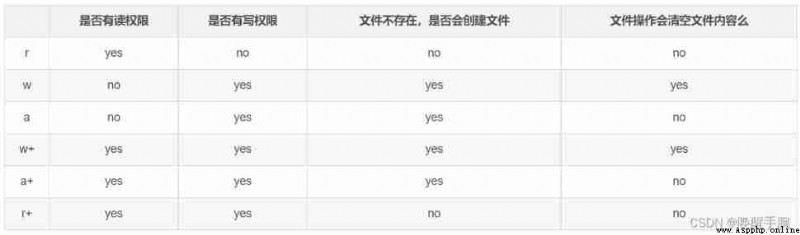
The file to read 、 Write 、 Append mode :r , w , a ,r+ ,w+ , a+ , rb ,wb ,ab , r+b ,w+b ,a+b
About file Common properties of objects :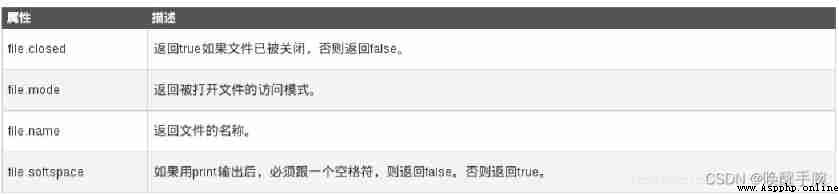
Common read / write operations :
seek(offset, from) Yes 2 Parameters :
offset: Offset ,from: Direction 0 : Indicates the beginning of the file ; 1 : Indicates the current location ; 2 : Indicates the end of the file
Common closing operations :
Method 1 : call close() Method to close the file . The file must be closed after use , Because file objects take up operating system resources , And the operating system can open a limited number of files at the same time .
Method 2 : Python Introduced with Statement to automatically call close() Method .
python Medium with Statements are used to access resources , Ensure that no matter whether an error or exception occurs during the processing, the specified will be automatically executed (“ clear ”) operation , Release the accessed resources , For example, when a file is read or written, it will be automatically closed 、 Automatic acquisition and release of locks in threads .
Flush buffer operation :
flush() Method is used to flush the buffer , Write the data in the buffer to the file immediately , Clear the buffer at the same time , No need to wait passively for the output buffer to write .
In general , The buffer will be refreshed automatically after the file is closed , But sometimes you need to refresh it before closing , It can be used at this time flush() Method .
f.write Operation of file keyword :open(“ File name ”,mode=“ operation ”,encoding= “ Encoding mode ”)
f = open("helloworld.txt", 'r+t', encoding="utf-8")
print(f)
# <_io.TextIOWrapper name='helloworld.txt' mode='r' encoding='cp936'>
# f The value of is a variable , It takes up the memory space of the application
print(" Read... For the first time ".center(50, "*"))
print(f.read())
print(" Second reading ".center(50, "*"))
print(f.read())
f.seek(0)
print(" Read... For the third time ".center(50, "*"))
print(f.read())
f.close()
# <_io.TextIOWrapper name='helloworld.txt' mode='r+t' encoding='utf-8'>
# *********************** Read... For the first time ***********************
# Hello time I like you to wake up your wrist
# *********************** Second reading ***********************
#
# *********************** Read... For the third time ***********************
# Hello time I like you to wake up your wrist
========= ===============================================================
Character Meaning
--------- ---------------------------------------------------------------
'r' open for reading (default)
'w' open for writing, truncating the file first
'x' create a new file and open it for writing
'a' open for writing, appending to the end of the file if it exists
'b' binary mode
't' text mode (default)
'+' open a disk file for updating (reading and writing)
'U' universal newline mode (deprecated)
========= ===============================================================
Error demonstration : t Mode can only read text files
with open(r' Love nmlab Love of .mp4', mode='rt') as f:
f.read()# The binary of the hard disk is read into memory -》t The mode changes what is read into memory decode decode
Whether it is read in the character stream , Or byte stream reading ,for line in f It's all about \n Newline as delimited
with open(r"helloworld.txt", 'rb') as f:
for line in f:
print(line)
# Whether it is read in the character stream , Or byte stream reading ,for line in f It's all about \n Newline as delimited
Solution to memory overflow caused by excessive content
# f.read() And f.readlines() It's all about reading content in one time , If the content is too large, the memory overflows , If you want to read all the content into memory , You have to read in... Several times , There are two ways to do it :
# Mode one
with open('a.txt',mode='rt',encoding='utf-8') as f:
for line in f:
print(line) # Read only one line of content into memory at the same time
# Mode two
with open('1.mp4',mode='rb') as f:
while True:
data=f.read(1024) # Read only... At the same time 1024 individual Bytes Into memory
if len(data) == 0:
break
print(data)
# Write operations
f.write('1111\n222\n') # Writing for text patterns , You need to write your own line breaks
f.write('1111\n222\n'.encode('utf-8')) # in the light of b Pattern writing , You need to write your own line breaks
f.writelines(['333\n','444\n']) # File mode
f.writelines([bytes('333\n',encoding='utf-8'),'444\n'.encode('utf-8')]) #b Pattern
About flush, Push the buffer data into memory .
flush() Method is used to flush the buffer , Write the data in the buffer to the file immediately , Clear the buffer at the same time , No need to wait passively for the output buffer to write .
In general , The buffer will be refreshed automatically after the file is closed , But sometimes you need to refresh it before closing , It can be used at this time flush() Method .
When using read / write streams , In fact, the data is read into memory first , Then write the data to the file , When you have finished reading the data, it doesn't mean you have finished writing it , Because there is a part that may remain in the memory buffer . If... Is called at this time close() Method closes the read / write stream , Then this part of the data will be lost , So before closing the read / write stream flush(), Clear the data first .
The function of this method is to forcibly output the data in the buffer . If you don't flush There may be no real output .
import time
with open(r"helloworld.txt", 'at', encoding="utf-8") as f:
f.write(" Wake up the wrist ")
f.flush()
print(" Wait for the buffer to be pushed into memory ...")
time.sleep(5)
print(" Write successfully ")
close(): Close flow object , But refresh the buffer first , After the closing , Stream objects can no longer be used .
flush(): Just refresh the buffer , Stream objects can still be used
seek How to move the pointer
seek(0,0) By default, move to the beginning of the file or abbreviate to seek(0)
seek(x,1) Indicates to move backward from the current pointer position x( Positive numbers ) Bytes , If x It's a negative number , The current position moves forward x Bytes
seek(x,2) Move forward and backward from the end of the file x( Positive numbers ) Bytes , If x negative , It's moving forward from the end x Bytes
File modification operation
**import os
with open("helloworld.txt", 'rt', encoding='utf-8') as f, \
open("helloworld.txt.swap", 'wt', encoding='utf-8') as temp_f:
for line in f:
line = line.replace(" like ", " Super love ")
temp_f.write(line)
os.remove("helloworld.txt")
os.rename("helloworld.txt.swap", "helloworld.txt")**
buffering: buffer
Blog address :open operation +buffering buffer + Context management +StringIO and BytesIO
-1 Indicates that the default size is used buffer. If it's binary mode , Use io.DEFAULT_BUFFER_SIZE The default value is 4096 perhaps 8192.
import io
print(io.DEFAULT_BUFFER_SIZE)
>>>8192
If it's text mode , If it's a terminal device , Is the row cache method , If not , Then use the strategy of binary mode .
0 , Use only in binary mode , It means off buffer
1 , Use only in text mode , Indicates the use of line buffering . It means that when you see a newline character flush, Buffer by one line , If the buffer memory of a row is full , Will be written to disk , Or if there is a newline character, it will be buffered
purpose : After the user enters a newline character , Save this batch of data to disk
Greater than 1, Is used to specify the buffer Size ,# For text mode , It's invalid , For binary only
f= open('test02','rb+',buffering=0)
# Close buffer , There is a data to be written immediately , Not recommended
f= open('test02','rb+',buffering=1)
# It's line buffering , Do not write when the cache is not full , Until a newline is detected
# If there is a newline character in this batch of written data , Then this batch of data is written into the disk
f.flush # Write to disk manually

buffering summary :
A buffer is an area of memory , Store the data in memory first , Then write... Once , It is similar to batch operation of database , This greatly increases the data read and write rate .
Today's peripheral controllers have their own buffer pools , Such as disk and network card , By buffering IO When reading in the way of , Such as BufferedInputStream There is one in the buf block ,CPU The buffer pool in the peripheral device available The byte block of is read into the whole block buf Memory .
dump and dumps All implemented serialization ,load and loads Both implement deserialization
The process by which a variable becomes storable or transportable from memory is called serialization , Serialization is the process of converting the state of an object into a saveable or transportable format .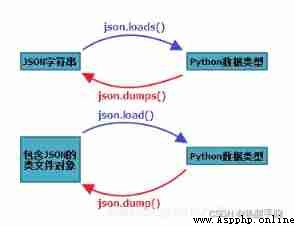
The re reading of variable contents from serialized objects to memory is called deserialization , Deserialization is the process of converting a stream into an object .
load and loads ( Deserialization )
load: For file handle , take json Format characters are converted to dict, Read from file ( take string Convert to dict )
data_json = json.load(open('demo.json','r'))
loads: For memory objects , take string Convert to dict( take string Convert to dict )
data = json.loads('{'a':'1111','b':'2222'}')
dump and dumps( serialize )
dump: take dict Type conversion to json String format , Write to file ( Easy to store )
data_dict = {
'a':'1111','b':'2222'}
json.dump(data_dict, open('demo.json', 'w'))
dumps: take dict Convert to string( Easy transmission )
data_dict = {
'a':'1111','b':'2222'}
data_str = json.dumps(data_dict)
Related built-in functions :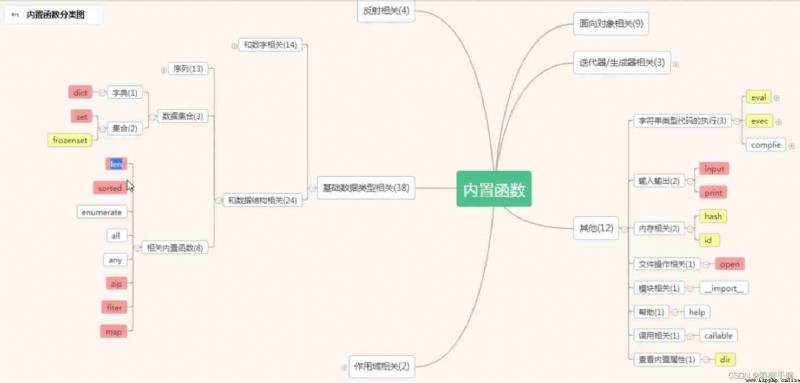
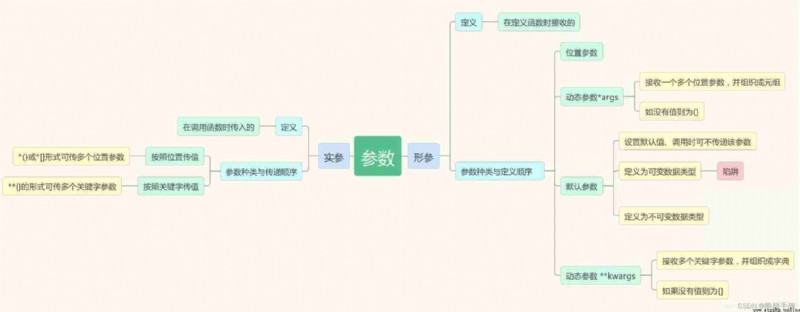
The dynamic parameters of the function *args,**kwargs, The order of formal parameters , You need to use universal parameters , Dynamic parameters ,*args,**kwargs
Parameter sequence : Positional arguments 、*args、 Default parameters 、**kwargs
*args Aggregate the positional parameters of all arguments into a tuple , And assign this tuple to args, What works is * Not at all args, However, as a convention, all position parameters that receive arguments dynamically are used args
def sumFun(*args):
print(args)
sumFun(1,2,['hello']) # It's a tuple (1, 2, ['hello'])
**kwargs Aggregate the keyword parameters of all arguments into a dictionary , And assign this dictionary to kwargs
( What works is ** Not at all kwargs, But as a rule, all keyword parameters that dynamically receive arguments are used kwargs)
def fun(*args,**kwargs):
print(args)
print(kwargs)
fun(1,2,['a','b'],name='xiaobai',age=18)
# result :
# (1, 2, ['a', 'b']) # Positional arguments , Tuples
# {'name': 'xiaobai', 'age': 18} # Key parameters , Dictionaries
A scope is a namespace ,python establish 、 Changing or finding variable names is in the so-called namespace . When a variable is created by assignment ,python The place of code assignment in determines the namespace in which the variable exists , That is, his visible range .
For the function , Function adds an additional namespace layer to the program to minimize conflicts between the same variables : By default , All variable names assigned to a function are associated with the namespace of the function . This rule means :
so , The scope of a variable depends on where it is assigned in the code , It has nothing to do with function calls
We can go through globals() Function to view the contents of the global scope , It can also be done through locals() To view variables and function information in the local scope
Scope details
The namespace of the function can be nested , So that the variable names used inside the function are not different from those outside the function ( In the same module or another function ) The variable names of conflict . Function defines the local scope , And the module defines the global scope :
Be careful : Any type of assignment within a function will delimit a name as local , Include = sentence ,import Module name of ,def The function name of , Function form parameter name, etc . If you are in the def Assign a name in any way in , It defaults to the local name of the function .
however , Note that the original position change object does not divide the variable into local variables , Only assign values to variables . for example L It is assigned as a list at the top level of the module , In a function, it is similar to L.append(X) The statement does not L Divided into local variables , and L = X But you can .append Is to modify the object , and = It's assignment , Understand that modifying an object does not assign a value to a variable name .
Variable name resolution :LEGB The rules , Summarize three simple rules
The variable name resolution mechanism is called LEGB The rules , It is also named after the scope :
Local scope L, To the next floor def or lambda Local scope of E, Global scope G, Last hour Built-in scope B. If they are not found, an error will be reported .Case introduction to consolidate :
def show_value():
temp = 1
def show_value_inner():
temp = 2
show_value_inner()
print(temp) # 1
show_value()
global and nonlocal Scope of action
global Keyword is used to use global variables in functions or other local scopes . But if you don't modify global variables, you can also not use global keyword
Declare global variables , If you want to modify the global variable locally , The global variable must also be declared locally
If you do not declare a global variable locally , And do not modify global variables . You can use global variables normally
nonlocal Keyword is used to use outer layers in functions or other scopes ( Non Global ) Variable
global temp
temp = 1
def show_value():
def show_value_inner():
print(temp) # 1
show_value_inner()
print(temp) # 1
show_value()
Introduction to closures :
If you define another function inside of one function , An external function is called an external function , The inner function is called its inner function .
Closure conditions :
An inner function is defined in an outer function
The temporary variable of the outer function is used in the inner function
And the return value of the outer function is the reference of the inner function
In general , If a function ends , Everything inside the function is released , Return to memory , Local variables will disappear . But closures are a special case , If the outer function finds its own temporary variable at the end, it will be used in the inner function in the future , We bind the temporary variable to the inner function , Then I'll finish it myself .
# Examples of closure functions
# outer It's an external function a and b They are all temporary variables of external functions
def outer( a ):
b = 10
# inner It's an internal function
def inner():
# In the inner function We use the temporary variable of the external function
print(a+b)
# The return value of the outer function is a reference to the inner function
return inner
if __name__ == '__main__':
# Here we call the external function to pass in the parameters 5
# In this case, the external function has two temporary variables a yes 5 b yes 10 , And created the inner function , Then I save the reference of the inner function back to demo
# At the end of the external function, it is found that the internal function will use its own temporary variables , These two temporary variables are not released , Will be bound to this inner function
demo = outer(5)
# We call the inner function , See if an internal function is a temporary variable that can use an external function
# demo Save the return value of the external function , That is to say inner References to functions , This is equivalent to executing inner function
demo() # 15
demo2 = outer(7)
demo2() #17
We can think of a closure as a special function , This function consists of two nested functions , They are called external functions and internal functions , The return value of an outer function is a reference to an inner function , So that's the closure .
Modify the value of the outer function in the inner function
Usually at the end of a function , Will release temporary variables , But in closures , Because the temporary variable of the outer function is used in the inner function , In this case, the outer function will bind the temporary variable to the inner function , So, the outer function is over , But you can still use temporary variables when calling inner functions , That is, the parameters of the outer layer of the closure can be preserved in memory
If you want to modify the value of the outer function in the inner function , Need to use nonlocal Keyword declaration variables
The following describes the closure format with pseudo code
def Outer functions ( Parameters ):
def Inner function ():
print(" Inner functions perform ", Parameters )
return Inner function
References to inner functions = Outer functions (" Pass in the parameter ")
References to inner functions ()
Next, we test closures as follows :
def outer():
list = []
def inner(value):
list.append(value)
return list
return inner
inner = outer()
list_temp = inner(1)
list_temp = inner(2)
list_temp = inner(3)
print(list_temp) # [1, 2, 3]
def outer():
list = []
def inner(value):
list.append(value)
return list
return inner
list_temp = outer()(1)
list_temp = outer()(2)
list_temp = outer()(3)
print(list_temp) # [3]
Blog recommended address : Decorator
What is a decorator (decorator)
Simply speaking , A decorator can be understood as a function that wraps a function , It generally handles the incoming functions or classes , Return the modified object . therefore , We can do this without modifying the original function , Execute other code before and after executing the original function , Common scenarios include log insertion , Transactions, etc .
python Decorator is a function used to expand the original function function , What's special about this function is that its return value is also a function , Use python The advantage of decorators is to add new functions without changing the original function code .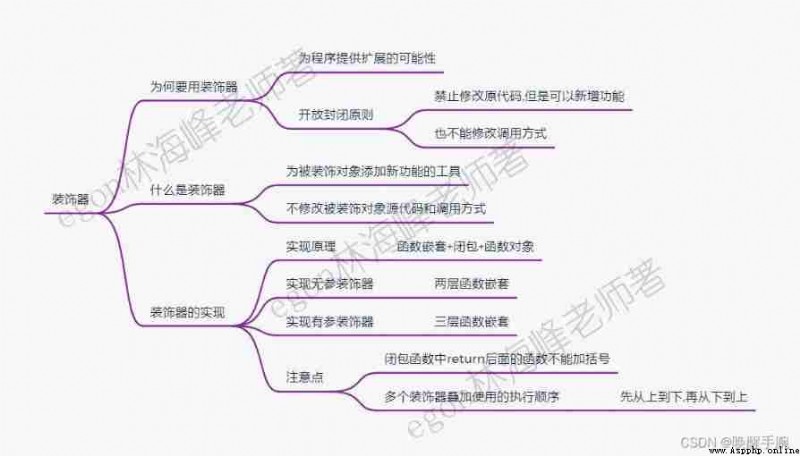
The design of software should follow the principle of opening and closing , It's open to expansion , And changes are closed . Open to expansion , It means when there are new demands or changes , You can extend existing code , To adapt to the new situation . Closed to modification , It means that once the object is designed , You can do your job on your own , Don't modify it .
The source code and calling method of all functions included in the software , Should avoid modification , Otherwise, once the mistake is corrected , It is very likely to produce a chain reaction , Eventually, the program crashes , And for the software that goes online , New demands or changes are emerging one after another , We must provide the program with the possibility of extension , This uses the decorator .
Function decorators are divided into : There are two kinds of ornaments, i.e. non - parametric ornament and parametric ornament , The implementation principle of the two is the same , All are ’ Nested function + Closure + Function object ’ The product of the combined use of .
The strange thing here is , In the above code, we only declare two functions docorate and house, No function was called , After running, the console will print out decorate Information in , The reason is that we use decorators @decorate
def decorate(func): # The decorator receives a function as an input
print(' Outer layer printing test ')
print(' Inner layer loading completed ……')
func()
@decorate # Decorator
def house(): # Decorated function
print(' I'm a blank room ')
Case test of decorator :
# There is no need to invade , There's no need for functions to execute repeatedly
import time
def deco(func):
def wrapper():
startTime = time.time()
func()
endTime = time.time()
msecs = (endTime - startTime)*1000
print("time is %d ms" %msecs)
return wrapper
@deco
def func():
print("hello")
time.sleep(1)
print("world")
if __name__ == '__main__':
f = func # here f To be an assignment func, perform f() Is to perform func()
f()
there deco Function is the most primitive decorator , Its argument is a function , Then the return value is also a function . Where the function as a parameter func() It's just returning functions wrapper() Internal execution of .
In function func() prefix @deco,func() Function is equivalent to being injected with timing function , Now just call func(), It has become “ New features more ” Function of .
Here the decorator is like an injection symbol : With it , It expands the function of the original function, and does not need to intrude into the function to change the code , There is no need to repeat the original function .
# A decorator with indefinite parameters
import time
def deco(func):
def wrapper(*args, **kwargs):
startTime = time.time()
func(*args, **kwargs)
endTime = time.time()
msecs = (endTime - startTime)*1000
print("time is %d ms" %msecs)
return wrapper
@deco
def func(a,b):
print("hello,here is a func for add :")
time.sleep(1)
print("result is %d" %(a+b))
@deco
def func2(a,b,c):
print("hello,here is a func for add :")
time.sleep(1)
print("result is %d" %(a+b+c))
if __name__ == '__main__':
f = func
func2(3,4,5)
f(3,4)
#func()
The sequence of multiple decorators is from the last decorator , Go to the first decorator , And execute the function itself .
The decorator starts with the called function , If decorated , The decorating function is executed until the wrapping function is encountered , If the wrapper function is also decorated , Then execute the upper decoration function , The cycle goes on , Until there is no upper decorator , And then from the top decoration to continue .
@deco01
@deco02
def func(a,b):
print("hello,here is a func for add :")
time.sleep(1)
print("result is %d" %(a+b))
My test case is shown below :
import time
from functools import wraps
def outter(long=1):
def deco(func):
@wraps(func)
def wrapper(*args, **kwargs):
print(args, kwargs)
start = time.time()
res = func(*args, **kwargs)
time.sleep(long)
# delay time
end = time.time()
# wrapper.__name__ = func.__name__
# wrapper.__doc__ = func.__doc__
print("the cost of time is :{}".format(end - start))
return res
return wrapper
# wrapper‘s address
return deco
@outter(2)
def old_func(name, key="bilibili"):
""" the infor of helloworld """
print("helloworld", name, key)
return "helloworld"
old_func(" Wake up the wrist ")
print(old_func.__name__)
print(old_func(" Wake up the wrist "))
# func = deco(func)
about python Come on , Everything is the object , All variable assignments follow the object reference mechanism . When the program is running , Need to carve out a space in memory , It is used to store temporary variables generated by runtime ; After calculation , Then output the result to the permanent memory . If the amount of data is too large , Poor memory space management can easily occur OOM(out of memory), Commonly known as burst memory , The program may be aborted by the operating system .
And for servers , Memory management is more important , Otherwise, it is easy to cause memory leakage - The leak here , It's not that you have information security issues in your memory , Used by a malicious program , It means that the program itself is not well designed , Causes the program to fail to free memory that is no longer in use .
Memory leaks don't mean that your memory is physically gone , It means that the code allocates a certain amount of memory , Because of design mistakes , Lost control of this memory , This results in a waste of memory . That is, this memory is out of gc The control of .
Python Garbage collection mechanism : Count references 、 Recycling 、 Mark clear 、 Generational recycling
Garbage collection mechanism : Count references
because python Everything is an object , All the variables you see , Is essentially a pointer to an object .
When an object is no longer called , That is, when the reference count of this object ( Number of pointers ) by 0 When , It means that this object will never reach , Naturally, it becomes garbage , Need to be recycled . It can be simply understood that there is no variable pointing to it .
Call function func(), In the list a After being created , Memory usage has rapidly increased to 433 MB: And at the end of the function call , Memory returns to normal . This is because , List of function internal declarations a It's a local variable , After the function returns , References to local variables are deregistered ; here , list a The number of references to the referenced object is 0,Python Garbage collection will be performed , So the large amount of memory used before is back .
In the new code ,global a It means that you will a Declare as a global variable . that , Even if the function returns , The reference to the list still exists , So the object will not be garbage collected , Still takes up a lot of memory . Again , If we return the generated list , Then receive... In the main program , Then the reference still exists , Garbage collection will not be triggered , A lot of memory is still being used :
How can you see how many times a variable is referenced ? adopt sys.getrefcount
If a function call is involved , It will be added twice 1. Function stack 2. Function call
You can see it from here python No longer need to be like C That kind of artificial release of memory , however python It also provides us with the method of manually releasing memory gc.collect()
So far , Looks like python The garbage collection mechanism is very simple , As long as the number of object references is 0, It must trigger gc, Then the number of references is 0 Is it triggered gc The necessary and sufficient conditions for ?
Garbage collection mechanism : Recycling
If there are two objects , They refer to each other , And is no longer referenced by other objects , So should they be recycled ?
The result is obvious , They are not recycled , But from a procedural point of view , When this function ends , As a local variable a,b It no longer exists in the sense of procedure . But because of their mutual references , As a result, the number of references is not 0.
At this time, how to avoid it ?
python For circular references , It has an automatic garbage collection algorithm :1. Mark clear (mark-sweep) Algorithm 2. Generational collection (generational)
Garbage collection mechanism : Mark clear
The steps for mark removal are summarized as follows :
GC Will take all of 『 The object of activity 』 Mark
Put those unmarked objects 『 Inactive objects 』 To recycle
that python How to determine what is an inactive object ?
By using graph theory to understand the concept of inaccessibility . For a directed graph , If we start from a node to traverse , And mark all nodes it passes through ; that , At the end of the traversal , All nodes not marked , We call it an unreachable node . Obvious , The existence of these nodes is meaningless , natural , We need to recycle them .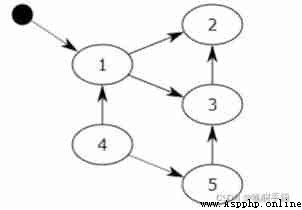
But every time I traverse the whole graph , about Python It's a huge performance waste . therefore , stay Python The implementation of garbage collection ,mark-sweep A data structure is maintained using a two-way linked list , And only consider the objects of the container class ( Only container class objects ,list、dict、tuple,instance, It is possible to generate circular references ).
Container object ( such as :list,set,dict,class,instance) Both can contain references to other objects , So it's possible to have circular references . and “ Mark - eliminate ” Counting is all about circular references .
Before we get to the tag removal algorithm , We need to be clear , About the storage of variables , There are two regions in memory : Heap and stack areas , When you define variables , The relationship between variable name and value memory address is stored in stack area , Variable values are stored in the heap , Memory management recycles the contents of the heap area , Details are shown below
Two variables are defined x = 10、y = 20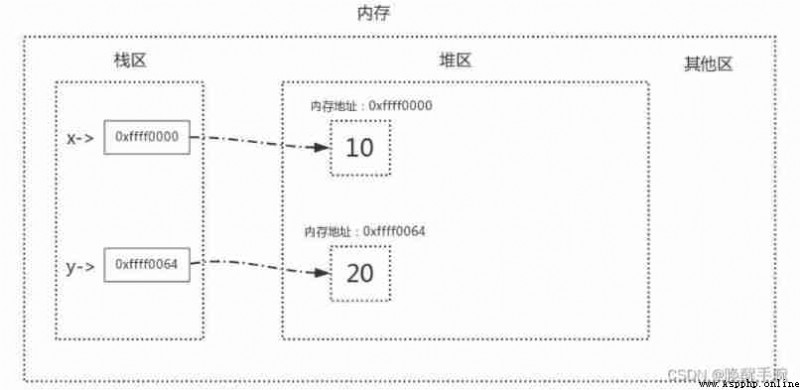
When we execute x=y when , The changes of stack area and heap area in memory are as follows :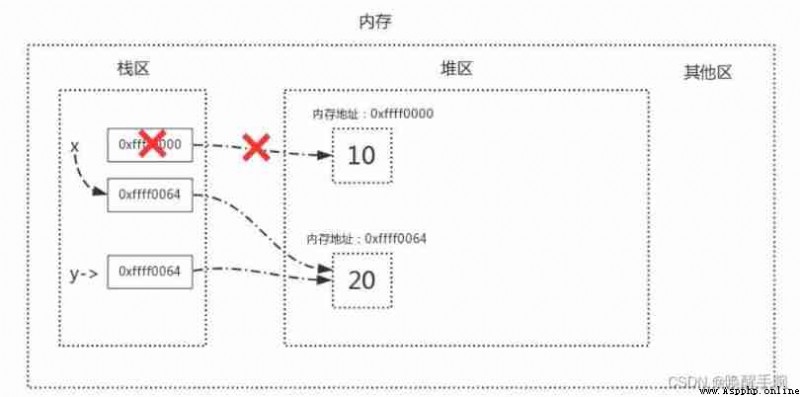
Mark / The cleaning algorithm works when the available memory space of the application is exhausted , It stops the whole process , Then we do two things , The first term is the label , The second term is clear .
Generally speaking, it is : The process of marking is equivalent to starting a line from the stack area ,“ Connect ” To heap area , And then indirectly from the heap area “ Connect ” To another address , Any memory space connected by this line starting from the stack area is accessible , Will be marked as alive .
In particular : The process of marking is essentially , Traverse all GC Roots object ( All the contents or threads in the stack area can be used GC Roots object ), And then all of the GC Roots Objects that can be accessed directly or indirectly are marked as living objects , The rest are non living objects , It should be removed .
Direct reference refers to the memory address directly referenced from the stack area , Indirect reference refers to the memory address that is referenced from the stack area to the heap area and then further referenced , Take our previous two lists l1 And l2 For example, draw the following image :
When we delete at the same time l1 And l2 when , It will be cleaned up in the stack l1 And l2 The content of :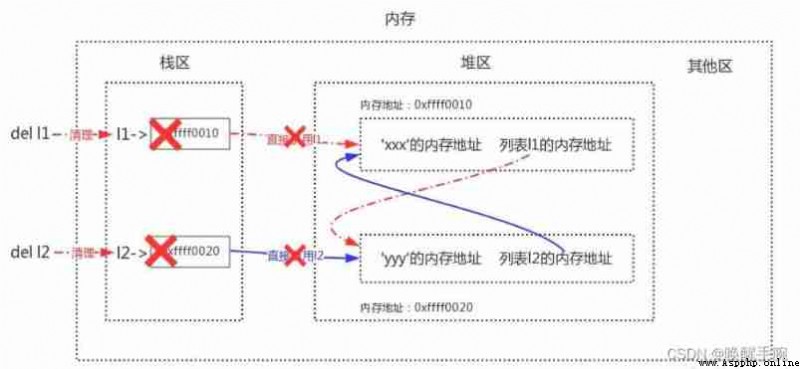
In this way, when the mark clearing algorithm is enabled , It is found that there are no more l1 And l2( All that's left is mutual references between the two in the heap ), So the list 1 And list 2 None of them are marked alive , Both will be cleaned up , This solves the memory leak problem caused by circular reference .
Garbage collection mechanism : Generational recycling
Generational recycling is a way of exchanging space for time ,Python The memory is divided into different sets according to the lifetime of the object , Each set is called a generation ,Python Divide memory into 3“ generation ”, They are the young generation ( The first 0 generation )、 Middle age ( The first 1 generation )、 Old age ( The first 2 generation ), They correspond to 3 A linked list , Their garbage collection frequency and the survival time of objects increase and decrease . The newly created objects will be assigned to the younger generation , When the total number of young generation linked lists reaches the upper limit ( When the new object minus the deleted object in the garbage collector reaches the corresponding threshold ),Python The garbage collection mechanism will be triggered , Recycle the objects that can be recycled , And objects that won't be recycled will be moved to the middle ages , And so on , The object of the old generation is the one who has the longest life , Even in the whole life cycle of the system . meanwhile , Generational recycling is based on marker removal technology .
in fact , The idea of generational recycling is , Newborn objects are more likely to be garbage collected , And objects that survive longer have a higher probability of surviving . therefore , In this way , It can save a lot of computation , So as to improve Python Performance of .
So for the question just now , Reference counting just triggers gc A sufficient and nonessential condition of , Circular references also trigger .
Garbage collection mechanism : debugging
have access to objgraph To debug the program , Because at present its official documents , I haven't read it carefully yet , We can only put the document here for your reference ~ Two of these functions are very useful 1. show_refs() 2. show_backrefs()
Garbage collection mechanism : summary
Recycling is Python A mechanism of its own , Used to automatically release memory space that will not be used again ;
Reference counting is one of the simplest implementations , But remember , This is only a sufficient and unnecessary condition , Because circular references need to pass the unreachable judgment , To determine if it can be recycled ;
Python The automatic recycling algorithm includes mark removal and generational recycling , It mainly aims at garbage collection of circular reference ;
Debug memory leaks , objgraph It's a good visual analysis tool .
Blog address recommendation :https://zhuanlan.zhihu.com/p/108683483
Python Caching integers and short strings , Therefore, each object has only one copy in memory , The object referred to by the reference is the same , Even with assignment statements , Just create new references , Not the object itself ;
Python There is no cache for long strings 、 Lists and other objects , It can be composed of multiple identical objects , You can use assignment statements to create new objects .
stay Python in , Each object has a total number of references to that object : Reference count
View the reference count of the object :sys.getrefcount()
When using a reference as an argument , Pass to getrefcount() when , Parameter actually creates a temporary reference . therefore ,
getrefcount()The result obtained , It will be more than expected 1.
Python A container object for ( such as : surface 、 Dictionaries, etc ), Can contain multiple objects .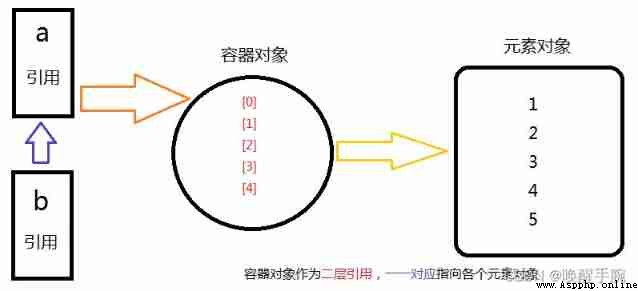
By the visible on , actually , The container object does not contain the element object itself , Is a reference to each element object .
What does reference count reduction include :
1、 The alias of the object is explicitly destroyed
import sys
temp1 = "wrist_waking"
temp2 = temp1
print(sys.getrefcount("wrist_waking")) # 5
del temp2
print(sys.getrefcount("wrist_waking")) # 4
2、 An alias of an object is assigned to another object
import sys
temp1 = "wrist_waking"
temp2 = temp1
print(sys.getrefcount("wrist_waking")) # 5
temp2 = " Wake up the wrist "
print(sys.getrefcount("wrist_waking")) # 4
3、 Object to remove from a container object , Or the container object itself is destroyed
temp = "wrist_waking"
list = [1, 2, temp]
print(sys.getrefcount("wrist_waking"))
list.remove(temp)
# del list
print(sys.getrefcount("wrist_waking"))
4、 A local reference is out of its scope , Like the one above foo(x) At the end of the function ,x Object reference to minus 1
import sys
def foo():
var = "wrist_waking"
print(" When the function is executed :", sys.getrefcount("wrist_waking")) # 5
temp = "wrist_waking"
print(" Before function execution :", sys.getrefcount("wrist_waking")) # 6
foo()
print(" After function execution :", sys.getrefcount("wrist_waking")) # 5
When Python More and more people in , Take up more and more memory , Start garbage collection
(garbage collection), Remove useless objects .
When Python The reference count of an object of the is reduced to 0 when , Indicates that there is no reference to the object , The object becomes garbage to be recycled . For example, a new object , Assigned to a reference , Object's reference count changes to 1. If the reference is removed , Object has a reference count of 0, Then the object can be garbage collected .
del temp after , There are no references to the previously created [1, 2, 3] , The table reference count becomes 0, Users can't touch or use this object in any way , When garbage collection starts ,Python The reference count scanned is 0 The object of , Just empty the memory it occupies .
Garbage collection considerations :
1、 Garbage collection ,Python You can't do anything else , Frequent garbage collection will greatly reduce Python Work efficiency ;
2、Python Only under certain conditions , Start garbage collection automatically ( There is no need to recycle if there are few garbage objects )
3、 When Python Runtime , It will record the assigned objects (object allocation) And unassign objects (object deallocation) The number of times . When the difference between the two is higher than a certain threshold , Garbage collection will start .
Problem generation : Collection mechanism based on reference counting , Memory recovery , You need to go through the reference count of all the objects , It's very time consuming , Therefore, generational recycling was introduced to improve recycling efficiency , Generational recycling uses “ Space for time ” The strategy of .
The core idea of generational recycling ∶ In the case of multiple scans , There are no recycled variables ,gc The mechanism says , This variable is a commonly used variable ,gc It's going to be scanned less frequently
Python Memory pool mechanism
Python There are big memory and small memory :(256K Size memory for bounds )
1、 Large memory usage malloc Distribute
2、 Small memory is allocated using a memory pool
Python learning a == b and a is b The difference between
Python To optimize efficiency , Built in small integer object pool and simple string object pool .
The small integer object pool includes [-5, 256], When the small integer values between them are the same, they belong to the same object in the small integer object pool . That is a is b return True. The same is true for simple strings , Not applicable to other objects . But in Pycharm There may be differences in the compiler .
character string ( String resident )
When two object strings are the same , They use an internal memory , But there is a rule , That is, only numbers are allowed , Letter , Only when the underscore is composed can the string reside .
String persistence is actually equivalent to small integers . In different environments , String persistence is also different , stay pycharm in , Strings do not distinguish , Are resident .
Reference type : Such as list、tuple、dict etc.
stay python in , The reference type is used to create the object , Will open up a storage space , Whether the elements are the same or not . It's not like a non - reference type , The same elements all point to the same memory address .
stay Python in ,print() Function supports formatted output , And C Linguistic printf similar .
Related blog recommendation : Introduction to formatted output
Format output example :
str1 = "%s.length = %d" % ("AmoXiang", len("AmoXiang"))
% Representing formatting operators in strings , It must be followed by a formatting symbol , The details are shown in the table below
%() Tuples can contain one or more values , Such as variables or expressions , Used to add to a string % Operators pass values , Tuples contain the number of elements 、 The order must be the same as in the string % Operators correspond to each other , Otherwise an exception is thrown .
%() Tuple must be after string , Otherwise it will not work . If the string contains only one % The operator , You can also pass values directly .
Format and output relevant symbols and descriptions 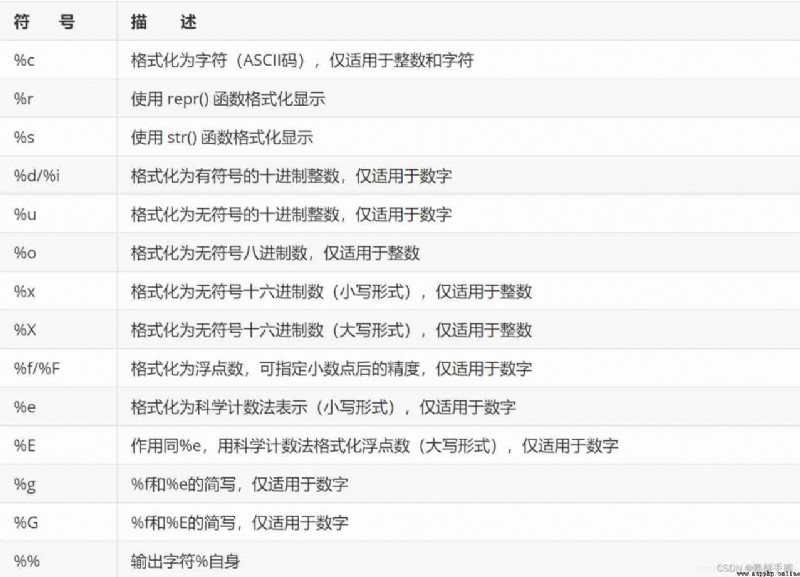
Format output floating point number : Output numbers as floating-point character strings in different formats .
PI = 3.141592653
print("pi1 = %10.3f" % PI) # The total width is 10, Decimal place precision is 3
print("pi2 = %.*f" % (3, PI)) # * Indicates reading from the following tuple 3, Define precision
print("pi3 = %010.3f" % PI) # use 0 Fill in the blanks
print("pi4 = %-10.3f" % PI) # Align left , Total width 10 Characters , Decimal place precision is 3
print("pi5 = %+f" % PI) # Display a positive sign in front of a floating-point number
Use str.format() Method
% Operator is the basic method of traditional formatting output , from Python 2.6 Version start , New formatting method for string data str.format(), It passes through {} Operators, and : Auxiliary instructions instead of % The operator .
Through the location index value
print('{0} {1}'.format('Python', 3.7)) # Python 3.7
print('{} {}'.format('Python', 3.7)) # Python 3.7
print('{1} {0} {1}'.format('Python', 3.7)) # 3.7 Python 3.7
You can use... In a string {} As a formatting operator . And % The difference between operators is ,{} The operator can customize the position of the reference value through the included position value , You can also quote repeatedly .
Index values by keywords
# Output :Amo Age is 18 year .
print('{name} Age is {age} year .'.format(age=18, name="Amo"))
Index by subscript
L = ["Jason", 30]
# Output :Jason Age is 30 year .
print('{0[0]} Age is {0[1]} year .'.format(L))
By using format() Function, which is convenient mapping The way , Lists and tuples can Break up Pass as a normal parameter to format() Method , Dictionaries can be broken up into keyword parameters for methods .format() Methods contain rich format qualifiers , Attached to {} In the operator : After the symbol .
The following example design output 8 Bit character , And set different filling characters and value alignment .
print('{:>8}'.format('1')) # The total width is 8, Right alignment , Default space fill
print('{:0>8}'.format('1')) # The total width is 8, Right alignment , Use 0 fill
print('{:a<8}'.format('1')) # The total width is 8, Align left , Use a fill
f And float Type data
print('{:.2f}'.format(3.141592653)) # Output results :3.14
# among .2f Indicates that the precision after the decimal point is 2,f Indicates floating point number output .
Use b、d、o、x Output binary respectively 、 Decimal system 、 octal 、 Hexadecimal number .
num = 100
print('{:b}'.format(num)) # 1100100
print('{:d}'.format(num)) # 100
print('{:o}'.format(num)) # 144
print('{:x}'.format(num)) # 64
Use a comma (,) The thousands separator of the output amount .
print('{:,}'.format(1234567890)) # 1,234,567,890
format Function introduction :
utilize format() Function to implement data numbering . Number the data , It is also a way to format strings , Use format() Function to format and number a string .
Just set the padding character ( The number is usually set to 0), When setting the alignment, you can use <、> and ^ The symbol indicates left alignment 、 Right and Center , Align filled symbols in Width Fill in when output within the range .
Pairs of numbers 1 Conduct 3 Bit number , Right alignment , Need to set up format() The padding character of the function is 0
print(format(1, '0>3')) # Output :001
print(format(1, '>03')) # Output :001
print(format(15, '0>5')) # Output :00015
Use f-string Method
f-string yes Python3.6 A new string format method , Because we have already introduced various formatting methods , Be the same in essentials while differing in minor points , Here we use a simple case to demonstrate its usage . Embed variables and expressions in strings
name = "Python" # character string
ver = 3.6 # Floating point numbers
# Output :Python-3.6、Python-3.7、Python-3.8000000000000003
print(f"{name}-{ver}、{name}-{ver + 0.1}、{name}-{ver + 0.2}")
stay python in , An object assignment is actually a reference to an object . When creating an object , And when you assign it to another variable ,python There is no copy of this object , It just copies the reference to the object .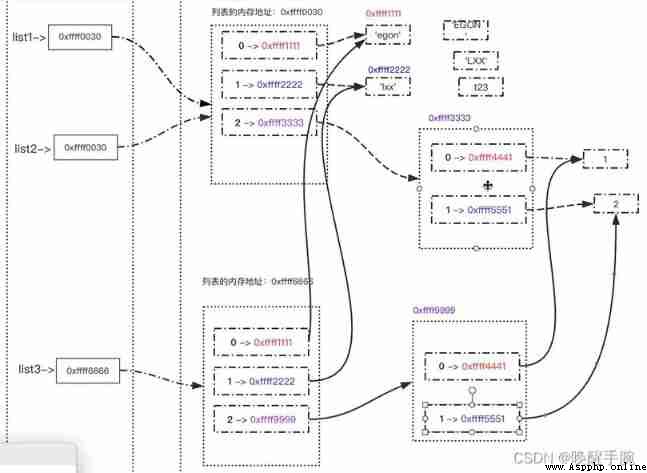
Shallow copy : Copy the outermost object itself , The internal elements just copy a reference . That is to say , Copy the object again , But I don't copy other objects referenced in this object
Deep copy : The external and internal elements are copied, and the object itself , Not references . That is to say , Copy the object again , And I also copy other objects referenced in this object .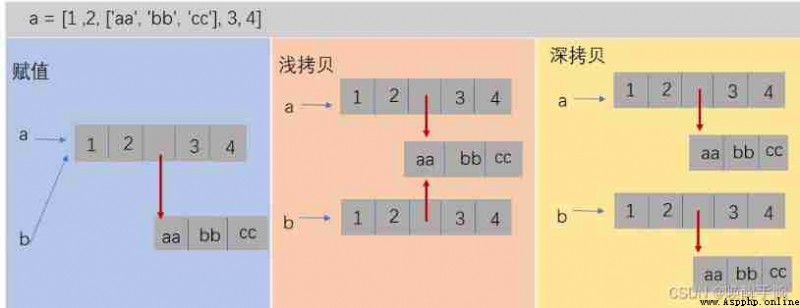
import copy Call the standard library module copy
# Direct reference assignment
L1 = [1, [1, 2, 3], 6]
# Use list.copy()
L2 = L1.copy()
# Using index slicing
L2 = L1[:]
# Use list() Function assignment
L2 = list(L1)
# Call the standard library module copy The function in copy() Shallow copy
L2 = copy.copy(L1)
# Call the standard library module copy The function in copy() Deep copy
L2 = copy.deepcopy(L1)
Recommended blog : Why? range Not an iterator ?range What kind is it ?
An iterator is 23 One of the most commonly used design patterns ( One of ), stay Python It can be seen everywhere in , We use it a lot , But not necessarily aware of its existence . Some methods are dedicated to generating iterators , There are other ways to solve other problems “ secretly ” Use iterators .
Before the system learns iterators , I always thought range() Method is also used to generate iterators , Now I suddenly find , It generates only iteratable objects , Not an iterator ! (PS:Python2 in range() What is generated is a list , This article is based on Python3, Generated are iteratable objects )
range() What is it? ?
Its grammar :range(start, stop, [step]) ;start Refers to the starting value of the count , The default is 0;stop Refers to the end value of the count , But does not include stop ;step It's the step length , The default is 1, Not for 0 .range() The method of generating a left closed range of integers .
about range() function , There are several points to pay attention to :
(1) The range it represents is an interval that is left closed and right open ;
(2) The parameters it receives must be integers , It could be negative , But it can't be floating-point numbers or other types ;
(3) It is an immutable sequence type , You can judge the elements 、 Look for the element 、 Section operation , But you cannot modify the element ;
(4) It is an iteratable object , It's not an iterator .
Why? range() Do not produce iterators ?
There are many built-in ways to get iterators , for example zip() 、enumerate()、map()、filter() and reversed() wait , But like range() In this way, there is no way to get only iteratable objects .
stay for- loop Ergodic time , Iteratable objects have the same performance as iterators , That is, they are all evaluated inert , There is no difference in space complexity and time complexity . I have summed up the difference between the two “ Two different things together ”: The same thing is that you can iterate lazily , The difference is that iteratable objects do not support self traversal ( namely next() Method ), The iterator itself does not support slicing ( namely __getitem__() Method ).
Despite these differences , But it's hard to conclude which of them is better . Now the subtlety is , Why give 5 Both built-in methods design iterators , Just give range() Method design is an iterative object ? Unify them all , Isn't it better ?
zip() 、enumerate()、map()、filter() and reversed() And other methods need to receive the parameters of the determined iteratable object , It's a reprocessing process of them , Therefore, we also hope to produce certain results immediately to , therefore Python The developer designed this, and the result is an iterator . There's another advantage to this , That is, when the iteratable object as a parameter changes , The iterator as a result is consumptive , Will not be misused .
and range() The method is different , The parameter it receives is not an iteratable object , Itself is a process of initial processing , So design it as an iterative object , It can be used directly , It can also be used for other reprocessing purposes . for example ,zip() And so on range Parameters of type .
range What is the type ?
There are three basic sequence types : list 、 Tuples and ranges (range) object .(There are three basic sequence types: lists, tuples, and range objects.)
I haven't noticed that , original range Types are the same basic sequence as lists and tuples ! I always remember that strings and tuples are immutable sequence types , Never thought , There is also an immutable sequence type !
>>> range(2) + range(3)
-----------------------------------------
TypeError Traceback (most recent call last)
...
TypeError: unsupported operand type(s) for +: 'range' and 'range'
>>> range(2)*2
-----------------------------------------
TypeError Traceback (most recent call last)
...
TypeError: unsupported operand type(s) for *: 'range' and 'int'
Copy code
So here comes the question : It's the same immutable sequence , Why do strings and tuples support these two operations , And it happened range Sequence doesn't support ? Although you can't modify immutable sequences directly , But we can copy them to a new sequence for operation , why range The object doesn't even support this ?
Let's see the explanation of the official documents :
…due to the fact that range objects can only represent sequences
that follow a strict pattern and repetition and concatenation will
usually violate that pattern.as a result of range An object simply represents a sequence that follows a strict pattern , And repetition and splicing usually break this pattern …
The key to the problem is range Sequential pattern, Think carefully , In fact, it represents an equal difference sequence ( meow , I didn't forget my math knowledge in high school …), Splicing two arithmetic sequences , Or repeat an arithmetic sequence , It's not right to think about it , That's why range Type does not support these two operations . It follows that , Other modifications can also destroy the structure of the arithmetic sequence , It's all changed .
Review the full text , I came to two unpopular conclusions :range It's an iteratable object, not an iterator ;range The object is an immutable sequence of equal differences .
Analysis of iterator principle :
Iteratable object :
Iterate through the index , Implement a simple , But only for sequence types : character string , list , Tuples . For dictionaries without indexes 、 Set and other non sequential types , We must find a way to iterate without relying on the index , This uses the iterator .
To understand what iterators are , A very important concept must be clarified in advance : Iteratable object (Iterable).
Grammatically speaking , Built in __iter__ Method objects are all iteratable objects , character string 、 list 、 Tuples 、 Dictionaries 、 aggregate 、 Open files are iteratable objects
"".__iter__()
[].__iter__()
{
}.__iter__()
set().__iter__()
().__doc__
range(10).__iter__()
open("helloworld.txt").__iter__()
Iterator object :
The iterator object calls obj.iter() Method returns an iterator object (Iterator). Iterator objects are built-in iter and next Object of method , The open file itself is an iterator object , Execute iterator object .iter() Method still gets the iterator itself , And execute iterators .next() Method will calculate the next value in the iterator .
An iterator is Python Provide a unified 、 The iterative value taking method that does not depend on the index , As long as there are multiple “ value ”, Both sequential and non sequential types can be taken as iterators
for Principle of circulation
With iterators , Then we can not rely on the index iteration , Use while The implementation of the loop is as follows
goods=['mac','lenovo','acer','dell','sony']
i=iter(goods) # Each time you need to retrieve an iterator object
while True:
try:
print(next(i))
except StopIteration: # Catch abnormal termination loop
break
for Loops are also called iterative loops ,in Can be followed by any iteratable object , Above while A loop can be abbreviated as
goods=['mac','lenovo','acer','dell','sony']
for item in goods:
print(item)
for When the cycle is working , First, the iteratable object will be called goods Built in iter Method to get an iterator object , Then call the... Of the iterator object next Method assigns the obtained value to item, Execute the loop body to complete a loop , Go round and begin again , Until capture StopIteration abnormal , End iteration .
The advantages and disadvantages of iterators
Index based iteration , The state of all iterations is saved in the index , The iterative method based on iterator does not need index , The state of all iterations is stored in the iterator , However, this treatment has both advantages and disadvantages :
1、 advantage : It provides a unified iterative value method for sequential and non sequential types .
2、 advantage : The inertia calculation : An iterator object represents a data stream , You can call... Only when you need it next To calculate a value , As far as the iterator itself is concerned , There is only one value in memory at the same time , So it can store infinite data stream , For other container types , As listing , You need to store all the elements in memory , Limited by memory size , The number of values that can be stored is limited .
3、 shortcoming : Unless it's exhausted , Otherwise, the length of the iterator cannot be obtained
4、 shortcoming : Only one value can be taken , Can't go back to the beginning , More like ‘ disposable ’, The only goal of an iterator is to execute repeatedly next Method until the values are exhausted , Otherwise, it will stay in a certain position , Wait for the next call next; If you want to iterate over the same object again , You can only call iter Method to create a new iterator object , If there are two or more loops using the same iterator , There must be only one loop to get the value .
List yes python One of the basic data structures in , and Java Medium ArrayList Some similar , Support the addition of dynamic elements .list It also supports different types of elements in a list ,List is an Object.
One , Create a list of Just use square brackets for comma separated items ([]) Enclose to subscript ( Corner marker , Indexes ) from 0 Start , The subscript of the last element can be written -1
list = ['1',‘2,‘3’]
list= [] An empty list
Two , Add new elements
list.append()
# stay list Add an element at the end
list.insert(n,'4')
# Add the element in the specified position , If the specified subscript does not exist , Then add... At the end
list1.extend(list2)
# Merge two list list2 There are still elements in
3、 ... and , Look at the values in the list
print(list[n])
# Use the subscript index to access the values in the list , You can also use square brackets to intercept characters
print(list.count(xx))
# Check the number of an element in this list , If the modified element does not exist , Then the return 0
print(list.index(xx))
# Find the small label of this element , If there are more than one , Return to the first , If you find an element that does not exist, you will report an error
Four , Delete list The elements in
list.pop()
# Delete the last element
list.pop(n)
# Specify subscript , Delete the specified element , If you delete a nonexistent element, an error will be reported
list.remove(xx)
# Delete list One of the elements , There are multiple identical elements , Delete the first
print(list.pop())
# There is a return value
print(list.remove())
# No return value
del list[n]
# Delete the element corresponding to the specified subscript
del list
# Delete the entire list , list Cannot access after deletion
5、 ... and , Sort and invert
list.reverse()
# Reverse list
list.sort()
# Sort , Default ascending order
list.sort(reverse=True)
# Descending order
notes :list There are strings in , You cannot sort numbers , Sort for the same type
6、 ... and , List operation function
len(list)
# Number of list elements
max(list)
# Returns the maximum value of a list element
min(list)
# Returns the minimum value of a list element
list(seq)
# Converts a tuple to a list
python Tuples (tuple) And list (list) difference
I'm sure you all know that , stay Python There are two objects in the data type : Tuples tuple And list list . Their writing and usage are very similar , Stupid is not clear . Maybe some students will be crazy to find the difference between them on the Internet , However, the following statements can be found :
list It's a variable object , Tuples tuple It's an immutable object !
because tuple immutable , So use tuple Can make code more secure !
In fact, in a lot of comparison “ Senior ” There are no tuples at first in our programming language , such as :Java、C++、C# etc. , But because of the flexibility and convenience of tuples , In the end, these programming languages all add . And a lot of young programming languages Python、Scala etc. , Tuple types are built in from the beginning .
The reason why they are so popular , In fact, the key point is the flexibility and convenience of its grammar , Improved programming experience . One of the biggest features is that functions can return multiple values , This feature is very common .
The function returns (return) Multiple values
def func():
value = "hello"
num = 520
return value, num
print(type(func()))
# <class 'tuple'>
print(func()[0])
# hello
print(func()[1])
# 520
It can be seen from the printed results that , Here the return value is a tuple! Because in grammar , Return to one tuple You can omit the brackets , Multiple variables can receive one at the same time tuple, Assign corresponding value by position .
therefore ,Python When the function returns multiple values , In fact, it's just to return to a tuple. Do you suddenly feel tuple Helped a lot , It makes it easier to get the results ?
tuple Immutable benefits
be relative to list for ,tuple It's immutable , This makes it possible for dict Of key, Or throw it in set in , and list No way. .
tuple Abandon the addition and deletion of elements ( Memory structure design has become more streamlined ), In exchange for performance improvement : establish tuple Than list Be quick , Storage space is more than list It takes less . So there it is “ It works tuple You don't have to list” That's what I'm saying .
When multithreading is concurrent ,tuple It doesn't need to be locked , Don't worry about security , It's much easier to write .
Whether tuples can be modified or not ( Tuple operation )
Create and access a tuple if you create an empty tuple , Just use parentheses ; If there is only one element in the tuple to be created , Put a comma after it ,
Update and delete tuples
It is not feasible to update directly on the same tuple , But it can be solved by copying the existing tuple fragment to construct a new tuple .
Split tuples into two parts by slicing , Then we use the join operator (+) Merge into a new set of elements , Finally, the original variable name (temp) Point to the connected new element group . Here we should pay attention to , Commas are required , Parentheses are also required !
__author__ = 'Administrator'
# -*- coding:utf-8 -*-
temp = (" Totoro "," Poodle "," Dingdang cat ")
temp = temp[:2] + (" Peppa Pig ",)+temp[2:]
print(temp)
""" (' Totoro ', ' Poodle ', ' Peppa Pig ', ' Dingdang cat ') Process finished with exit code 0 """
Delete elements in tuples : For the principle that tuples are immutable , It is impossible to delete an element alone , Of course, you can update tuples by slicing , Indirectly delete an element .
__author__ = 'Administrator'
# -*- coding:utf-8 -*-
temp = (' Totoro ', ' Poodle ', ' Peppa Pig ', ' Dingdang cat ')
temp = temp[:2] + temp[3:]
print(temp)
""" (' Totoro ', ' Poodle ', ' Dingdang cat ') Process finished with exit code 0 """
Rarely used in daily life del To delete the entire tuple , because Python The collection mechanism will automatically delete the tuple when it is no longer used .
__author__ = 'Administrator'
# -*- coding:utf-8 -*-
temp = (' Totoro ', ' Poodle ', ' Peppa Pig ', ' Dingdang cat ')
del temp
print(temp)
""" Traceback (most recent call last): File "F:/python_progrom/test.py", line 7, in <module> print(temp) NameError: name 'temp' is not defined Process finished with exit code 0 """
What is a dictionary ?
stay Python in , Dictionaries Is a series of keys — It's worth it . Each key Are associated with a value , You can use the key to access the value associated with it . The value associated with the key can be a number 、 character string 、 Lists and even dictionaries . in fact , Any Python Object is used as a value in the dictionary .dictionary( Dictionaries ) Except for the list python The most flexible data type in .
The difference between a dictionary and a list ? A list is an ordered set of objects and , Dictionaries are unordered sets of objects and
Dictionary use {} Definition , Dictionaries use key value pairs to store data , Use... Between key value pairs , Separate , key key It's the index , value value Is the data , Use... Between key and value : Separate , The key must be unique ( Because we have to find data through keys , The value can take any data type , But keys can only use strings , A number or tuple , A dictionary is an unordered data set and , Use print Function output Dictionary , Usually the order of output is not the same as the order of definition .
clear( ): Delete all dictionary entries , Nothing back ,None.
use : When x and y All point to the same dictionary , adopt x={} To clear x, Yes y No impact , But with x.clear(),y Will also be empty .
>>>a = {
'qq':123123,'name':'jack'}
>>>a.clear()
>>>a
{
}
copy( )
Return to a new dictionary , The key it contains - Values are the same for the original dictionary ( This method is shallow replication . Be careful :copy() Deep copy parent ( First level directory ), Sub object ( Two level directory ) No, no copy , Or reference , It will change with it . To avoid this situation , You can use deep copy deepcopy(), Not affected by each other .
>>>a = {
'qq':[123123,666666],'name':'jack'}
>>>b = a.copy()
>>>b['name'] = 'mark'
>>>b['qq'].remove(123123)
>>>b
{
'qq':[666666],'name':'mark'}
>>>a
{
'qq':[666666],'name':'jack'}
fromkeys( )
Create a new dictionary , Contains the specified key , And the value corresponding to each key is... By default None. It's fine too () Internal addition ( The default value is ) To any value
>>>a.fromkeys(['name','qq'], The default value is )
{
'name':None,'qq':None}
get( )
Used to access Dictionaries , If it doesn't exist in the dictionary . Then return to None, Also available at () Add a string after the find key in to change None.
items ( )
Returns a list of all dictionary items , Each of these elements is (key, value) In the form of . The order in which dictionary items are arranged in the list is uncertain
>>>a = {
'qq':[123123,666666],'name':'jack'}
>>>a.items()
dict_items([('qq', [123123, 666666]), ('name', 'jack')])
keys( )
Returns the key in the specified dictionary
>>>a = {
'qq':[123123,666666],'name':'jack'}
>>> a.keys()
dict_keys(['qq', 'name'])
pop( )
Can be used to get the value associated with the specified key , And set the key - Value pairs are removed from the dictionary
>>>a = {
'qq':[123123,666666],'name':'jack'}
>>>a.pop('name')
'jack'
>>> a
{
'qq': [123123, 666666]}
popitem( )
Pop up a dictionary item randomly , And delete
>>> a = {
'qq':[123123,666666],'name':'jack'}
>>> a.popitem()
('name', 'jack')
>>> a
{
'qq': [123123, 666666]}
setdefault( )
And get identical , But when the specified key is not included , Add the specified key to the dictionary - It's worth it .
>>> a = {
'qq':[123123,666666],'name':'jack'}
>>> a.setdefault('age',18)
18
>>> a
{
'qq': [123123, 666666], 'name': 'jack', 'age': 18}
>>> a.setdefault('name','mark')
'jack'
>>> a
{
'qq': [123123, 666666], 'name': 'jack', 'age': 18}
updata( )
Use items in one dictionary to update another dictionary , If the current dictionary contains items with the same key , Just replace its value .
>>>a = {
'qq':666666,'name':'jack'}
>>>b = {
'age':18,'name':'mark'}
>>>a.update(b)
>>>a
{
'qq': 666666, 'name': 'mark', 'age': 18}
values( )
Returns a dictionary view of the values in the dictionary . But the returned value can contain duplicate values .
>>>a = {
'qq':666666,'name':'jack','num':666666}
>>>a.value()
dict_values([666666,'jack',666666])
list (list) And a tuple (tuple) It's standard Python data type , They store values in a sequence . aggregate (set) Is another standard Python data type , It can also be used to store values . The main difference between them is , Collections are different from lists or tuples , Each element in the collection cannot appear more than once , And it is stored out of order .
Be careful : A collection can only store data of immutable type
Because elements in a collection cannot appear more than once , This enables the collection to efficiently remove duplicate values from lists or tuples to a large extent , And execute the Union 、 Intersection and other common mathematical operations .
A set is a set that has certain properties ( only ) Of 、 Unchanging elements , Variable data organization with disordered elements .
my_set = set() # initialization
Deduplication :
li = [1,2,3,1,1,2,3]
print(list(set(li)))
# duplicate removal Convert it to a collection type to remove duplication , Then convert to list type output
Limitations of set de duplication : Only containers that are all immutable type elements can be de duplicated , The order of the previous container cannot be maintained after the de duplication .
set The creation and use of collections of
#1. use {} establish set aggregate
person ={
"student","teacher","babe",123,321,123} # Similarly, various types of nesting , Duplicate data can be assigned , But storage will be de duplicated
print(len(person)) # Deposited 6 Data , The length display is 5, Storage is automatic de duplication .
print(person) # But the display is de duplication
''' 5 {321, 'teacher', 'student', 'babe', 123} '''
# empty set Collective set() Function representation
person1 = set() # Said empty set, Out-of-service person1={}
print(len(person1))
print(person1)
''' 0 set() '''
#3. use set() Function creation set aggregate
person2 = set(("hello","jerry",133,11,133,"jerru")) # Only one parameter can be passed in , It can be list,tuple etc. type
print(len(person2))
print(person2)
''' 5 {133, 'jerry', 11, 'jerru', 'hello'} '''
Common precautions
#1.set The string will also be de duplicated , Because the string belongs to the sequence .
str1 = set("abcdefgabcdefghi")
str2 = set("abcdefgabcdefgh")
print(str1,str2)
print(str1 - str2) # - No. can find the difference set
print(str2 - str1) # Null value
# print(str1 + str2) # set Can't be used in + Number
# print(str1 | str2) # Ask for a collection
{
'd', 'i', 'e', 'f', 'a', 'g', 'b', 'h', 'c'} {
'd', 'e', 'f', 'a', 'g', 'b', 'h', 'c'}
{
'i'}
set()
set Addition, deletion, modification and query of collection
# 1. to set Collection adds data
person ={
"student","teacher","babe",123,321,123}
person.add("student") # If the element already exists , No error , It will not add , The string will not be split into multiple elements , Don't go update
print(person)
person.add((1,23,"hello")) # You can add tuples , But it can't be list
print(person)
''' {321, 'babe', 'teacher', 'student', 123} {(1, 23, 'hello'), 321, 'babe', 'teacher', 'student', 123} '''
person.update((1,3)) # have access to update Add some tuple lists , Dictionary, etc . But it can't be a string , Otherwise, it will split
print(person)
person.update("abc")
print(person) # Will split the string into a,b,c Three elements
''' {321, 1, 3, 'teacher', (1, 23, 'hello'), 'babe', 'student', 123} {321, 1, 3, 'b', 'c', 'teacher', (1, 23, 'hello'), 'a', 'babe', 'student', 123} '''
# 2. from set Delete data in
person.remove("student") # Press the element to delete
print(person)
# print("student") If it doesn't exist , Will report a mistake .
''' {321, 1, 3, 'c', 'b', (1, 23, 'hello'), 'teacher', 'babe', 'a', 123} '''
person.discard("student") # Function and remove equally , The advantage is that if there is no , No mistake.
person.pop() # stay list Delete the last one by default , stay set Randomly delete one in the .
print(person)
''' {1, 3, (1, 23, 'hello'), 'teacher', 'b', 'a', 'babe', 123, 'c'} '''
# 3. to update set An element in , Because it's out of order , So you can't use angle marks
# So the general update is to use remove, And then in add
# 4. Query exists , Cannot return index , Use in Judge
if "teacher" in person:
print("true")
else:
print(" non-existent ")
''' true '''
# 5. Ultimate trick : Just empty set
print(person)
person.clear()
print(person)
''' set() '''
What we see on the computer screen are materialized characters , What is stored in the computer storage medium is actually a binary bit stream . There is a conversion rule between the two , Encryption and decryption in analog cryptography , from “ character ” To “ Bit stream ” be called “ code ”, from “ Bit stream ” To “ character ” Call it “ decode ”. This also leads to several concepts that we will talk about below .
python The interpreter reads the encoding of the file by default python3 Default : utf-8
python2 Default : ASCII
Specify the file header and modify the default encoding : stay py The first line of the file reads : #coding: gbk
Guaranteed operation python The core rule of no random code in the first two stages of the program :
Specify the file header #coding: The encoding format in which the file was originally stored on the hard disk 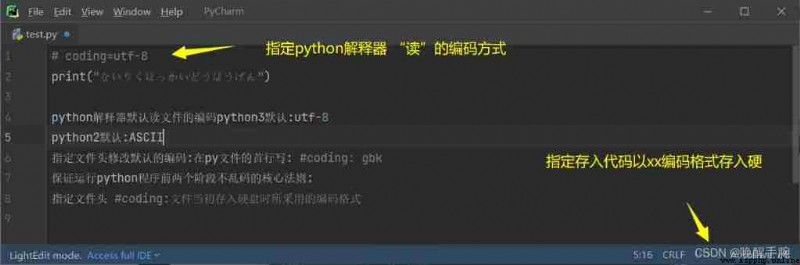
python3 Of str Type is saved directly by default unicode Format , in any case , Guarantee python2 Of str The type is not garbled :x= u' Wake up the wrist '
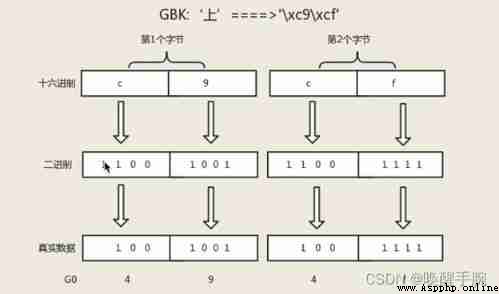
python2 And python3 Encoding rules for in memory characters
python3: Always with Unicode Encoding to store characters in memory , In this case :
window Systematic cmd The default encoding format for the command line window is :GBK, stay Pycharm In the console console Is to use utf-8 The encoding format of , So use python3 Stored string , To read ( Print ) There is no need to convert the code , The default encoding for computer memory is Unicode, So there will be no garbled code .
python2: The default is ASCII Encoding to store characters in memory , If an interpreter read is specified python How the script is encoded ( #coding: gbk), Then we will use The interpreter reads python How the script is encoded To store characters in memory . If specified u'xxx', Is to adopt Unicode To store characters in memory .
window Systematic cmd The default encoding format for the command line window is :GBK, stay Pycharm In the console console Is to use utf-8 The encoding format of , So use python2 Stored string .
stay window Command line window printing , If the stored character is GBK The format will not be garbled , stay Pycharm Console printing , If the stored character is GBK The format will be garbled , Because in Pycharm In the console console Is to use utf-8 The encoding format of .
First of all, understand unicode and utf-8 The difference between .
unicode It refers to the universal code , It's a kind of “ Character table ”. and utf-8 This is the encoding method stored in the code table .unicode Not necessarily by utf-8 In this way, it is compiled into bytecode Store , You can also use utf-16,utf-7 And so on . At present, most of them are based on utf-8 The way to become bytecode.
ASCII American standard code for information exchange
ASCII(American Standard Code for Information Interchange, American standard code for information exchange ) It's a computer coding system based on the Latin alphabet , Mainly used to show modern English and other western European languages . It's the most common single byte encoding system today , And equivalent to international standards ISO/IEC 646.
Because computers are invented by Americans , therefore , At the very beginning 127 One letter is encoded into the computer , That is to say, the English letters in upper and lower case 、 Numbers and symbols , This code table is called ASCII code , Like capital letters A The code of is 65, Lowercase letters a The code of is 97. after 128 This is called an extension ASCII code .
GBK and GB2312
It is very important for us to be able to display Chinese characters in the computer , However ASCII There is not even a radical in the table . So we also need a table about the correspondence between Chinese and numbers . A byte can only represent at most 256 Characters , It is obvious that one byte is not enough to process Chinese , So we need to use two bytes to represent , And not with ASCII Encoding conflict , therefore , China made GB2312 code , It's used to compile Chinese .
Unicode
therefore ,Unicode emerge as the times require .Unicode Unify all languages into one set of codes , So there won't be any more confusion .
Unicode Standards are evolving , But the most common is to use two bytes to represent a character ( If you want to use very remote characters , Need 4 Bytes ). Modern operating systems and most programming languages directly support Unicode.
But if unified into Unicode code , The confusion disappeared . however , If the text you write is basically all in English , use Unicode Coding ratio ASCII Coding requires twice as much storage space , It's very uneconomical in storage and transmission .
UTF - 8
Based on the principle of economy , There is a Unicode Code to “ Variable length encoding ” Of UTF-8 code .UTF-8 Code a Unicode Characters are encoded into... According to different number sizes 1-6 Bytes , Common English letters are encoded as 1 Bytes , Chinese characters are usually 3 Bytes , Only rare characters are encoded as 4-6 Bytes . If the text you are transferring contains a large number of English characters , use UTF-8 Coding saves space . As shown below :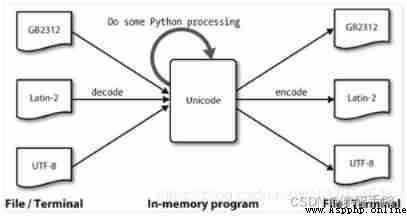
From the above table, you can also find ,UTF-8 Coding has an additional benefit , Namely ASCII Coding can actually be thought of as UTF-8 Part of coding , therefore , A large number only support ASCII The history of coding legacy software can be found in UTF-8 Keep working under the code .
When editing with Notepad , Read from file UTF-8 The characters are converted to Unicode Characters in memory , After editing , Save it with Unicode Convert to UTF-8 Save to file . Here's the picture :
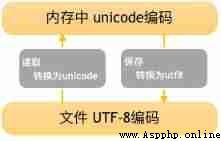
ultimately , Let's also fill in the cold knowledge of character coding . What we need to know , A character set is like having a version number , The content is constantly expanding , The new version contains the old version . such as gb2312 < gbk < gb18030.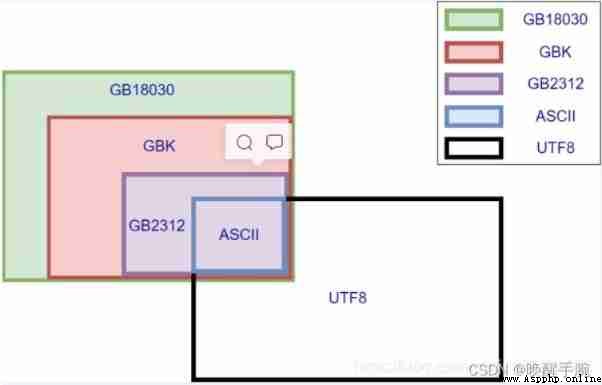
About unicode, It's like a generic data structure , Any character code can be converted into unicode code , This conversion is decode( decode 、 decoding ). We spent a lot of time understanding gbk <-> unicode Conversion between , Maybe I still can't remember which one is encode, Which is it decode. Here's a way :
One more thing to note ,unicode In terms of spelling ,union of code, It's a concept 、 slogan 、 General character encoding rules , Not a specific character encoding , It has no corresponding character set ,unicode Objects simply mean , The binary data in memory corresponding to this object is a string , Which language is it , Which code does it correspond to , How to show , Don't know . So you can't see the terminal device using the string unicode Output in the form of ( Unless you want that kind of processing ), therefore python stay print unicode When , It knows to take the corresponding character code from the standard output , transcoding (encode) Then output , Such output is the human language . Then you may have to ask ,unicode What's the use ?
It solves a key problem : Character code (Code Point) A one-to-one relationship with characters , In this way, we can get the character length normally , It's no problem to cut and splice strings .
This is it. str and unicode The most important difference between . Even though unicode The code of is also 2 Bytes , however unicode Know this 2 Bytes are together , Other character codes cannot do this .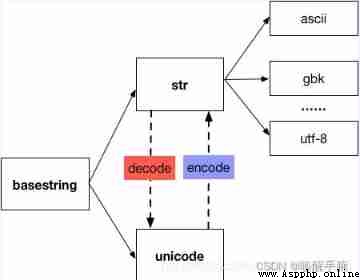
Define what happens to the function
1、 Request memory space to save function body code section
2、 Bind the above memory address to the function name
3、 Defining functions does not execute function body code , But it will check function body Syntax
What happens when you call a function
1、 Find the memory address of the function by the function name
2、 Then add slogans to trigger the execution of function body code
The relationship between formal parameters and actual parameters
1、 In the call phase , Actual parameters ( A variable's value ) It will be bound to formal parameters ( Variable name )
2、 This binding can only be used inside the function body
3、 The binding relationship between an actual parameter and a formal parameter takes effect when a function is called , Unbound after function call
def List_test(list):
list.append(4)
def var_test(value):
value = value + 1
list = [1, 2, 3]
List_test(list)
print(list) # [1, 2, 3, 4]
value = 1
var_test(value)
print(value) # 1
python In the function memory operation picture and text detailed explanation
def fun(a):
a[1] = [200]
list_target = [1,[2,3]]
fun(list_target) # What changes is the incoming mutable object
print(list_target[1])
Stored in the method area is the function code , Do not execute function bodies .
When you call a function , Will open up a memory space , It's called stack frame , Used to store variables defined inside a function ( Including the parameters ), And the function is completed , Stack frames are released immediately .
The function memory profile is shown below :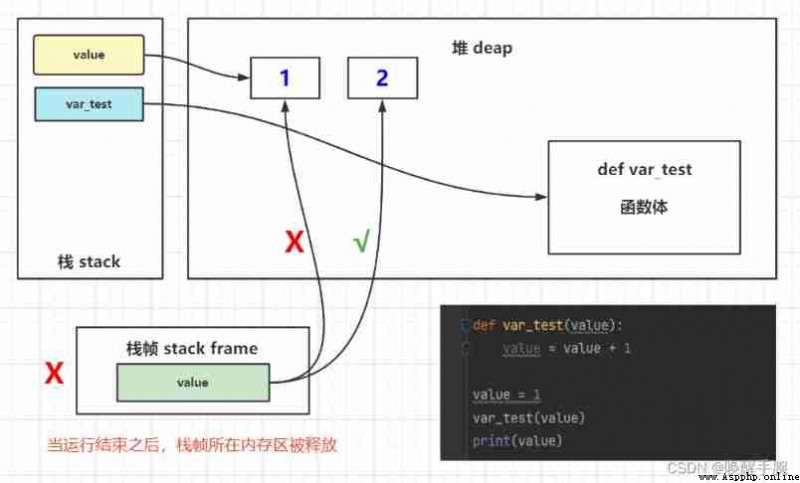
About why the value of an immutable variable does not change , The principle is as follows :
time And datetime modular
stay Python in , There are usually several ways to express time :
Time stamp (timestamp): Generally speaking , The time stamp indicates that the 1970 year 1 month 1 Japan 00:00:00 Start offset in seconds . We run “type(time.time())”, The return is float type .
Formatted time string (Format String)
Structured time (struct_time):struct_time Tuple co ownership 9 Nine elements in total :( year , month , Japan , when , branch , second , The week of the year , The day of the year , Daylight saving time )
import time
#-------------------------- Let's take the current time first , Let's get to know three kinds of time quickly
print(time.time()) # Time stamp :1487130156.419527
print(time.strftime("%Y-%m-%d %X"))
# Formatted time string :'2017-02-15 11:40:53'
print(time.localtime()) # Local time zone struct_time
print(time.gmtime()) # UTC Time zone struct_time
Among them, the time that the computer knows can only be ’ Time stamp ’ Format , And the time that programmers can handle or understand is : ‘ Formatted time string ’,‘ Structured time ’ , So there is a transformation relationship in the figure below :
According to the figure 1 The conversion time is shown below :
import time
# localtime([secs])
# Converts a timestamp to the current time zone's struct_time.secs Parameter not provided , The current time shall prevail .
time.localtime()
time.localtime(1473525444.037215)
# gmtime([secs]) and localtime() The method is similar to ,gmtime() The method is to convert a timestamp to UTC The time zone (0 The time zone ) Of struct_time.
# mktime(t) : Will a struct_time Convert to timestamps .
print(time.mktime(time.localtime()))#1473525749.0
# strftime(format[, t]) : Put a tuple representing time or struct_time( Such as by time.localtime() and time.gmtime() return ) Convert to formatted time string .
# If t Not specified , Incoming time.localtime(). If any element in the tuple is out of bounds ,ValueError Will be thrown .
print(time.strftime("%Y-%m-%d %X", time.localtime())) # 2016-09-11 00:49:56
# time.strptime(string[, format])
# Convert a formatted time string to struct_time. In fact, it's related to strftime() Inverse operation .
print(time.strptime('2011-05-05 16:37:06', '%Y-%m-%d %X'))
# time.struct_time(tm_year=2011, tm_mon=5, tm_mday=5, tm_hour=16, tm_min=37, tm_sec=6,
# tm_wday=3, tm_yday=125, tm_isdst=-1)
# In this function ,format The default is :"%a %b %d %H:%M:%S %Y".
According to the figure 2 The conversion time is shown below :
import time
# asctime([t]) : Put a tuple or struct_time In this form :'Sun Jun 20 23:21:05 1993'.
# If there are no parameters , Will be time.localtime() Pass in as a parameter .
print(time.asctime())# Sun Sep 11 00:43:43 2016
# ctime([secs]) : Put a time stamp ( Floating point number in seconds ) Turn into time.asctime() In the form of . If the parameter is not given or is
# None When , Will default to time.time() Is the parameter . Its function is equivalent to time.asctime(time.localtime(secs)).
print(time.ctime()) # Sun Sep 11 00:46:38 2016
print(time.ctime(time.time())) # Sun Sep 11 00:46:38 2016
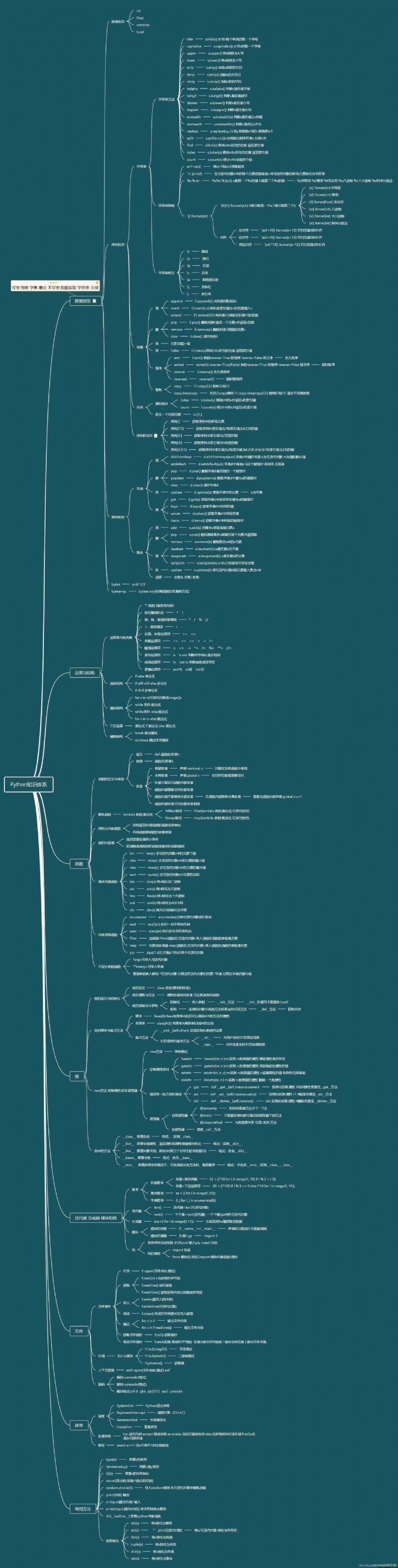
 Python takes you to collect content, so you can watch it for free without money, and strive to be a little expert in saving money~
Python takes you to collect content, so you can watch it for free without money, and strive to be a little expert in saving money~
Preface Hi. , Hello, everyone