When the company is idle and bored , Want to research python Of bs modular , Try to write about reptiles . But the company has limitations , Entertainment websites are not accessible , Finally, I found that the novel website can still enter , Then you . On and off ~
I used to think it was very low Of , I've always found it boring to grab data from pages , But today I actually began to feel some sense of achievement .
This crawler mainly uses two libraries :
import requests
from bs4 import BeautifulSoup
requests The module is used to simulate the request , Get the response page ;bs4 The module is used to parse the page of the response , Easy access to page tags .
I wanted to try the water first , Try to access the page with simple code , As a result, the following problems appeared at the first try :
Traceback (most recent call last):
File "D:/PycharmProjects/NovelCrawling/novel_crawling.py", line 109, in pre_op
book_info = search_by_kewords(keword)
File "D:/PycharmProjects/NovelCrawling/novel_crawling.py", line 89, in search_by_kewords
soup = BeautifulSoup(result_html, 'lxml')
File "D:\python\lib\site-packages\bs4\__init__.py", line 310, in __init__
elif len(markup) <= 256 and (
TypeError: object of type 'NoneType' has no len()
HTTPSConnectionPool(host='www.13800100.com', port=443): Max retries exceeded with url: /index.php?s=index/search&name=%E6%96%97%E7%BD%97%E5%A4%A7%E9%99%86&page=1 (Caused by NewConnectionError('<urllib3.connection.HTTPSConnection object at 0x000002029189FD30>: Failed to establish a new connection: [Errno 11001] getaddrinfo failed'))
How strange , The browser can access , And the agency is set up in the company , Why can't I ask . With this question is a Baidu , The most common result is like this :
response = requests.get(url, verify=False)
close verify=False Parameters , Say what close openSSL Verification or something , I don't understand , I can only verify , unfortunately , failed .
Others say that many cases are caused by misspelling the address , But I checked it carefully and didn't .
Uncomfortable , Baidu couldn't find the answer it wanted for half an hour , All think about it , Boring is boring , Playing with mobile phones is also very fragrant . But then I thought , Is it right? requests The module should have a separate proxy ?
With this question, I went to Baidu again ,requests The module can really set up a proxy , I feel hopeful , In the end, we solved it successfully ! The code is as follows :
proxies = {
'http': 'http://xxx.xxx.xxx.xxx:xx', # http agent
'https': 'http://xxx.xxx.xxx.xxx:xx' # https agent
}
response = requests.get(url, verify = False, proxies = proxies)
It's still here get To a point , The above configuration means , When the request is http Let's go http Agent for , yes https Leave when you ask https Agent for , But that doesn't mean https The agent must be https The address of . For example, the two agents here are set up http Agency address . A little bit around , In fact, to put it simply , Is when the request is https I set it up http agent .
Of course, if you use it at home, you won't have so many egg pain problems .
The website of this novel is 138 Reading net https://www.13800100.com, The analysis phase is not recorded here , It mainly analyzes the elements that need information for web page positioning . Here we mainly record the general idea :
In fact, it feels quite simple , Generally speaking, there are only three steps :
1、 Get chapter list , Analyze the download pages of each chapter
2、 Analyze the download page , Get the novel content of each chapter
3、 Store the novel content in a text file
1、 Get chapter list
Analyze the pages of the chapters of the novel catalog , It looks like this :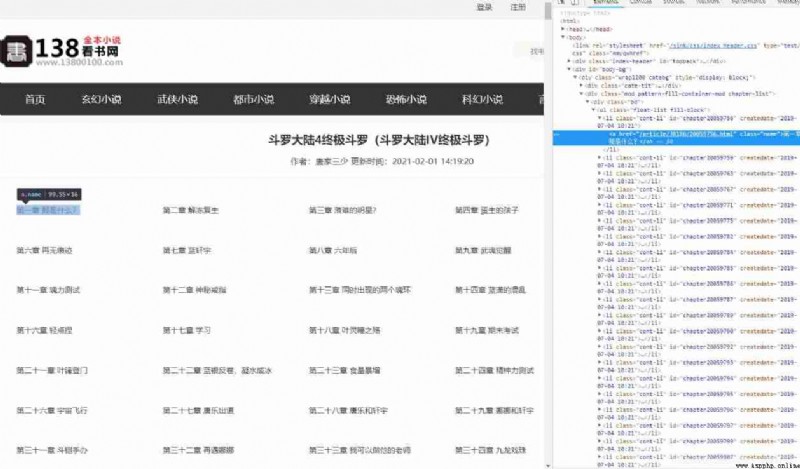
adopt F12 The development tool analyzes the element position of the chapter , Our goal is to analyze the reading address of each chapter . Here we can base on css Locate and analyze :
# Extract chapter links from web content
def get_download_page_urls(htmlContent):
# Instantiation soup object , Easy to handle
soup = BeautifulSoup(htmlContent, 'lxml')
# Get... For all chapters a label
li_as = soup.select('.bd>ul>.cont-li>a')
# The title of the novel
text_name = soup.select('.cate-tit>h2')[0].text
# Download address
dowload_urls = []
for a in li_as:
dowload_urls.append(f"{base_url}{a['href']}")
return [text_name, dowload_urls]
Here I get the name of the novel and the links to the chapters .
2、 Get the novel content of each chapter
Links to various chapters have been obtained , Next, you just need to analyze the content of the web page and store it in a file . The web page looks like this :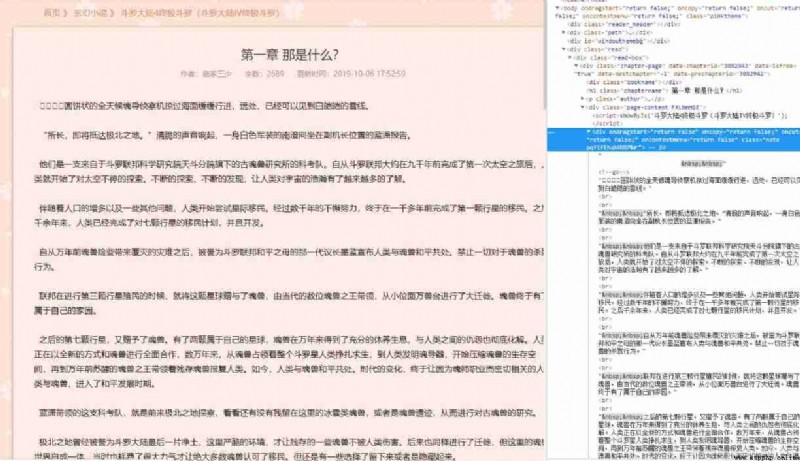
Code processing :
# Download by chapter
def download_by_chapter(article_name, url ,index):
''' article: The title of the novel url: Chapter reading Links index: Chapter number '''
content = get_content(url)
soup = BeautifulSoup(content, 'lxml')
# Chapter title
title = soup.select('.chapter-page h1')[0].text
# The author partially deals with
author = soup.select('.chapter-page .author')[0].text.replace('\n', '')
# The content of the novel is partially processed
txt = soup.select('.chapter-page .note')[0].prettify().replace('<br/>', '')\
.replace('\n', '')
txt = txt[txt.find('>') + 1:].rstrip('</div>').replace(' ', '\n').strip()
txt_file = open(fr"{article_name}\{'%04d' % index}_{title}.txt", mode='w',encoding='utf-8')
txt_file.write(f'{title}\n\n{author}\n\n{txt}'.replace(' ', ' '))
txt_file.flush()
txt_file.close()
Dealing with the content of the novel , Could have used .text Just get the text content , Then you can process it , But after the operation, I found that it was not easy to divide into paragraphs , There will be many strange symbols . After several twists and turns, I finally chose to use prettify() Method , Format the element as html character string , And then do the corresponding processing .
Here's a lesson , About the formatting of numbers :
'%04d' % index # It means that you will index Format to four digits
Sometimes we don't want to download files , So I added a method to download to the same file :
# Download to a file
def download_one_book(txt_file, url, index):
''' txt_file: Store text objects url: Chapter reading Links index: Chapter number '''
content = get_content(url)
soup = BeautifulSoup(content, 'lxml')
# Chapter title
title = soup.select('.chapter-page h1')[0].text
# The author partially deals with
author = soup.select('.chapter-page .author')[0].text.replace('\n', '')
# The content of the novel is partially processed
txt = soup.select('.chapter-page .note')[0].prettify().replace('<br/>', '') \
.replace('\n', '')
txt = txt[txt.find('>') + 1:].rstrip('</div>').replace(' ', '\n').strip()
txt_file.write(f'{title}\n\n'.replace(' ', ' '))
# Write the author only in the first chapter
if index == 0:
txt_file.write(f'{author}\n\n'.replace(' ', ' '))
txt_file.write(f'{txt}\n\n'.replace(' ', ' '))
txt_file.flush()
Obviously , The program is a little stiff , The user must manually go to 138 Read the website to find the directory address of the novel , Can be downloaded through this program . So I analyzed the web page , Write a website to search for novels :
# Keyword search books
def search_by_kewords(keyword, page=1):
''' keyword: Search for keywords page: Paging page number '''
book_info = {
}
while True:
search_url = f'{base_url}/index.php?s=index/search&name={keyword}&page={page}'
result_html = get_content(search_url)
soup = BeautifulSoup(result_html, 'lxml')
books_a = soup.select('.s-b-list .secd-rank-list dd>a')
for index, book_a in enumerate(books_a):
book_info[f'{index + 1}'] = [book_a.text.replace('\n', '').replace('\t', ''), f"{base_url}{book_a['href']}".replace('book', 'list')]
if len(books_a) == 0:
break
page += 1
print(f' We found {page} page ,{len(book_info.keys())} books .')
print('--------------------------')
return book_info
Then I did some detail processing , The complete program is obtained :
import os
import sys
import time
import traceback
import warnings
import requests
from bs4 import BeautifulSoup
# Ignore the warning
warnings.filterwarnings('ignore')
# Agent configuration
proxies = {
'http': 'http://xxx.xxx.xxx.xxx:xx', # http agent
'https': 'http://xxx.xxx.xxx.xxx:xx' # https agent
}
# 138 Reading net address
base_url = 'https://www.13800100.com'
# Get the contents of the directory URL
def get_content(url,):
response = ''
try:
# user_agent = "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.109 Safari/537.36"
response = requests.get(url, verify = False, proxies = proxies) # Situations that require the use of an agent
# response = requests.get(url, verify=False) # Without agency
response.raise_for_status() # If the returned status code is not 200, Throw an exception ;
return response.content.decode(encoding=response.encoding) # Decoded web page content
except requests.exceptions.ConnectionError as ex:
print(ex)
# Extract chapter links from web content
def get_download_page_urls(htmlContent):
# Instantiation soup object , Easy to handle
soup = BeautifulSoup(htmlContent, 'lxml')
li_as = soup.select('.bd>ul>.cont-li>a')
text_name = soup.select('.cate-tit>h2')[0].text
dowload_urls = []
for a in li_as:
dowload_urls.append(f"{base_url}{a['href']}")
return [text_name, dowload_urls]
# Download by chapter
def download_by_chapter(article_name, url ,index):
content = get_content(url)
soup = BeautifulSoup(content, 'lxml')
# Chapter title
title = soup.select('.chapter-page h1')[0].text
# The author partially deals with
author = soup.select('.chapter-page .author')[0].text.replace('\n', '')
# The content of the novel is partially processed
txt = soup.select('.chapter-page .note')[0].prettify().replace('<br/>', '')\
.replace('\n', '')
txt = txt[txt.find('>') + 1:].rstrip('</div>').replace(' ', '\n').strip()
txt_file = open(fr"{article_name}\{'%04d' % index}_{title}.txt", mode='w',encoding='utf-8')
txt_file.write(f'{title}\n\n{author}\n\n{txt}'.replace(' ', ' '))
txt_file.flush()
txt_file.close()
# Download to a file
def download_one_book(txt_file, url, index):
content = get_content(url)
soup = BeautifulSoup(content, 'lxml')
# Chapter title
title = soup.select('.chapter-page h1')[0].text
# The author partially deals with
author = soup.select('.chapter-page .author')[0].text.replace('\n', '')
# The content of the novel is partially processed
txt = soup.select('.chapter-page .note')[0].prettify().replace('<br/>', '') \
.replace('\n', '')
txt = txt[txt.find('>') + 1:].rstrip('</div>').replace(' ', '\n').strip()
txt_file.write(f'{title}\n\n'.replace(' ', ' '))
# Write the author only in the first chapter
if index == 0:
txt_file.write(f'{author}\n\n'.replace(' ', ' '))
txt_file.write(f'{txt}\n\n'.replace(' ', ' '))
txt_file.flush()
# Keyword search books
def search_by_kewords(keyword, page=1):
book_info = {
}
while True:
search_url = f'{base_url}/index.php?s=index/search&name={keyword}&page={page}'
result_html = get_content(search_url)
soup = BeautifulSoup(result_html, 'lxml')
books_a = soup.select('.s-b-list .secd-rank-list dd>a')
for index, book_a in enumerate(books_a):
book_info[f'{index + 1}'] = [book_a.text.replace('\n', '').replace('\t', ''), f"{base_url}{book_a['href']}".replace('book', 'list')]
if len(books_a) == 0:
break
page += 1
print(f' We found {page} page ,{len(book_info.keys())} books .')
print('--------------------------')
return book_info
# The main program deals with
def pre_op():
start = time.perf_counter()
try:
print(f' This procedure is applicable to downloading 138 Read online novels ,138 Reading net : {base_url}')
print(' Please enter keywords to find books :')
keword = input()
print(' Looking for ...')
book_info = search_by_kewords(keword)
print(' Please select the corresponding serial number to download :')
print('**********************')
for index in book_info.keys():
print(f"{index}: {book_info[index][0]}")
print('**********************')
c = input(' Please select :')
result_html = get_content(book_info[c][1])
dowload_urls = get_download_page_urls(result_html)
print(' Download link obtained !')
print('----------------------')
print(' Please select the download mode :')
print('1. Download by chapter ')
print('2. Download the whole book ')
c = input()
txt_file = ''
if not os.path.exists(fr'./{dowload_urls[0]}'):
os.mkdir(fr'./{dowload_urls[0]}')
if c == '2':
txt_file = open(fr"{dowload_urls[0]}\{dowload_urls[0]}_book.txt", mode='a+', encoding='utf-8')
for index, dowload_url in enumerate(dowload_urls[1]):
if c == '1':
download_by_chapter(dowload_urls[0], dowload_url, index + 1)
else:
txt_file.write(f'{dowload_urls[0]}\n\n')
download_one_book(txt_file, dowload_url, index)
sys.stdout.write('%\r')
percent = str(round(float(index + 1) * 100 / float(len(dowload_urls[1])), 2))
sys.stdout.write(f' Downloading ...{percent} %')
sys.stdout.flush()
txt_file.close()
print(f'\n The download ! total {len(dowload_urls[1])} chapter . Time consuming :{str(round(time.perf_counter() - start, 2))}s.')
print('=======================================================')
except:
traceback.print_exc()
if __name__ == '__main__':
pre_op()
Take a look at the end result :
This procedure is applicable to downloading 138 Read online novels ,138 Reading net : https://www.13800100.com
Please enter keywords to find books :
Doulo land
Looking for ...
We found 4 page ,20 books .
--------------------------
Please select the corresponding serial number to download :
**********************
1: Douluo continent ice Phoenix Douluo
2: I am the blue face of Douluo continent
3: The sword of Douluo continent determines the world
4: The limit of Douluo continent
5: Doulo land III The legend of the Dragon King ( The legend of the Dragon King )
6: Qinglian sword emperor Ji of Douluo continent
7: Doulo land 3 The legend of the Dragon King
8: Douluo, the God of the continent, the holy dragon Douluo
9: Legend of the great heaven of Douluo continent
10: The legend of white phoenix in Douluo continent
11: The beauty system of Douluo continent
12: The immortal period of Douluo continent
13: When fighting the mainland, sakazaki Kuang San
14: Doulo land lll Dragon dust
15: The legend of the flame gate of Douluo continent
16: Douluo national costume of the mainland, Dharma jade Xiaogang
17: The magician of Douluo continent
18: The sword of Douluo continent has fallen to the world
19: The soul of Douluo continent
20: The Douluo continent empties the world
**********************
Please select :11
Download link obtained !
----------------------
Please select the download mode :
1. Download by chapter
2. Download the whole book
2
Downloading ...100.0 %
The download ! total 153 chapter . Time consuming :220.17s.
=======================================================
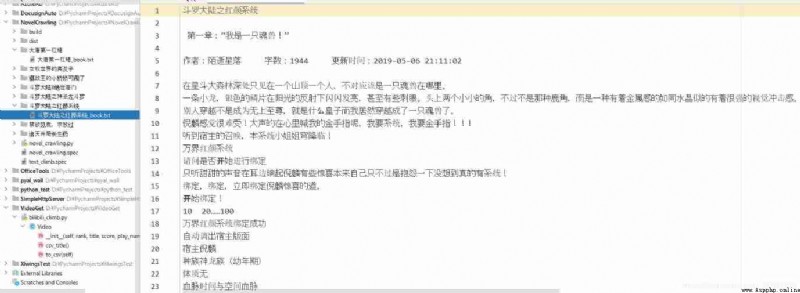
thus , This is the result of today's study , Originally, I wanted to overcome the problem of using multithreading to improve the download speed , But I am really weak in multithreading , After tossing and turning, I didn't get it out . If anyone can help me change to multithreading , Be deeply grateful .
Last , Welcome to leave a message to discuss ! If there is anything inappropriate, please correct it .