1、A/B testQu'est - ce que c'est?
A / BTests(Aussi appelé test de séparation ou test de baril)Est un moyen de comparer deux versions d'une page Web ou d'une application l'une à l'autre pour déterminer quelle version fonctionne mieux.ABLe test est essentiellement une expérience,Où deux ou plusieurs variantes de la page sont affichées au hasard à l'utilisateur,L'analyse statistique permet de déterminer quelle variante correspond à un objectif de conversion donné(Indicateurs tels que:CTR)Ça marche mieux.
Dans cet article,Nous présenterons l'analyse A/B Le processus de l'expérience,De la formulation d'hypothèses、Test jusqu'au résultat final de l'interprétation.Pour nos données,Nous utiliserons les données de Kaggle Ensemble de données pour,Il contient des paires qui semblent être des pages du site 2 Différents modèles(old_page Avec new_page)De A/B Résultats des essais.
C'est ce qu'on va faire:
1,Concevoir nos expériences
(Indicateurs sélectionnés,Construire des hypothèses,Sélectionnez l'unit é expérimentale,Calculer la taille de l'échantillon,Répartition du trafic,Calcul de la période expérimentale,.Vérification en ligne si la politique a été mise en oeuvre)
2,Collecte et préparation des données
3,Visualisation des résultats
4,Vérifier les hypothèses
5,Tirer des conclusions
Pour le rendre plus réaliste,Voici un scénario potentiel que nous étudions
Supposons que vous travailliez dans une équipe de produits d'une entreprise de commerce électronique en ligne de taille moyenne.UI Les concepteurs ont travaillé très dur sur la nouvelle version de la page produit, J'espère qu'il donnera un taux de conversion plus élevé. .Product Manager(PM)Je vais te le dire., Le taux de conversion actuel est en moyenne de 13%Gauche et droite,Si ça s'améliore2% , L'équipe sera heureuse ,C'est - à - dire, Si le nouveau design s'améliore , Est considéré comme un succès .Taux de conversion15%.
Avant d'introduire les modifications , L'équipe sera plus encline à les tester sur un petit nombre d'utilisateurs pour comprendre leur performance , Par conséquent, vous suggérez que certains utilisateurs du Groupe d'utilisateurs A/B Tests.
Concevoir nos expériences
Choisissez nos indicateurs ,Indicateur de valeur relative:Taux de conversion.
Choisissez l'unit é expérimentale :Granularité de l'utilisateur,Unuser_idEn tant qu'identificateur unique
Faire des hypothèses:
Étant donné que nous ne savons pas si le rendement de la nouvelle conception sera meilleur ou pire que celui de notre conception actuelle, (Ou identique?),Nous choisirons Expérience à deux queues :
Hₒ:p = p ₒ
Hₐ :p ≠ pₒ
Parmi euxpEtp ₒ Représente le taux de conversion de l'ancien et du nouveau design respectivement .Nous mettrons également en place95% Niveau de confiance:
α = 0.05
α La valeur est le seuil que nous avons fixé ,On a dit:“ Si la probabilité de résultats extrêmes ou plus est observée (pValeur)Inférieur àα, Alors nous refusons Null Hypothèses”.Grâce à notreα=0.05( Indique que la probabilité est 5%), Notre confiance (1- α ) Pour 95%.
Si vous n'êtes pas familier avec ce qui précède ,Ne vous inquiétez pas., Cela signifie en fait que peu importe le taux de conversion que nous observons dans les tests pour les nouvelles conceptions, , Nous voulons tous 95% Il est statistiquement différent du taux de conversion de notre ancien Design , Après avoir décidé de rejeter l'hypothèse zéro Hₒ Avant.
Sélectionner la taille de l'échantillon
Il est important de noter, Parce que nous ne testons pas toute la base d'utilisateurs ( Notre population ), Le taux de conversion que nous obtiendrons ne sera inévitablement qu'une estimation du taux de conversion réel. .
Nous avons déterminé le nombre de personnes capturées dans chaque groupe ( Ou une session utilisateur ) Affectera la précision de nos estimations de conversion : Plus la taille de l'échantillon est grande, Plus nos estimations sont précises ( C'est - à - dire que plus notre intervalle de confiance est petit ), Plus les chances de trouver des différences sont élevées dans les deux groupes ,Si ça existe.
D'un autre côté, Plus notre échantillon est grand , Plus nos recherches seront coûteuses ( Et irréaliste ), En général, il s'agit de sélectionner le nombre minimal d'échantillons satisfaits. .
Combien de personnes devrions - nous avoir dans chaque groupe? ?
La taille de l'échantillon dont nous avons besoin est déterminée par une méthode appelée Power analysis Pour estimer , Ça dépend de plusieurs facteurs :
Efficacité des tests (1 - β) — Cela signifie que lorsqu'il y a une différence réelle , Probabilité de trouver des différences statistiques entre les groupes dans nos tests .Comme d'habitude,C'est généralement réglé à 0.8
Alpha Valeur(α) — On l'a réglé à 0.05 Le seuil de
Taille de l'effet —— Nous nous attendons à ce qu'il y ait une grande différence entre les taux de conversion
Parce que notre équipe va s'occuper de 2% Satisfait de la différence ,Pour que nous puissions utiliser 13% Et 15% Pour calculer la taille de l'effet que nous prévoyons .
Python Tous ces calculs ont été traités pour nous. :
# Importation de paquets
import numpy as np
import pandas as pd
import scipy.stats as stats
import statsmodels.stats.api as sms
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
from math import ceil
%matplotlib inline
# Quelques préférences de style de dessin
plt.style.use('seaborn-whitegrid')
font = {
'family' : 'Helvetica',
'weight' : 'bold',
'size' : 14}
mpl.rc('font', **font)
effect_size = sms.proportion_effectsize(0.13, 0.15) # Calculer la taille de l'effet en fonction de nos ratios prévus
required_n = sms.NormalIndPower().solve_power(
effect_size,
power=0.8,
alpha=0.05,
ratio=1
) # Calculer la taille requise de l'échantillon
required_n = ceil(required_n) # Arrondi à l'entier suivant
print(required_n)
Produits:4720
Dans la pratique powerParamètre défini à 0.8 Cela signifie que s'il y a une différence réelle dans le taux de conversion entre nos conceptions, , Supposons que la différence soit la différence que nous estimons (13% C'est exact. 15%),On a environ 80% L'occasion de le tester comme statistiquement significatif dans notre taille d'échantillon calculée .
Bien sûr.,Tu peux l'utiliser aussi.:
Cette formule approximative est utilisée pour évaluer Taille de l'échantillon
Défini par l'indicateur de valeur absolue et l'indicateur de valeur relative , Le calcul de l'écart type sera différent :
Commencez à voir nos données :
df = pd.read_csv('ab_data.csv')
df.head()
Produits:
df.info()
Produits:
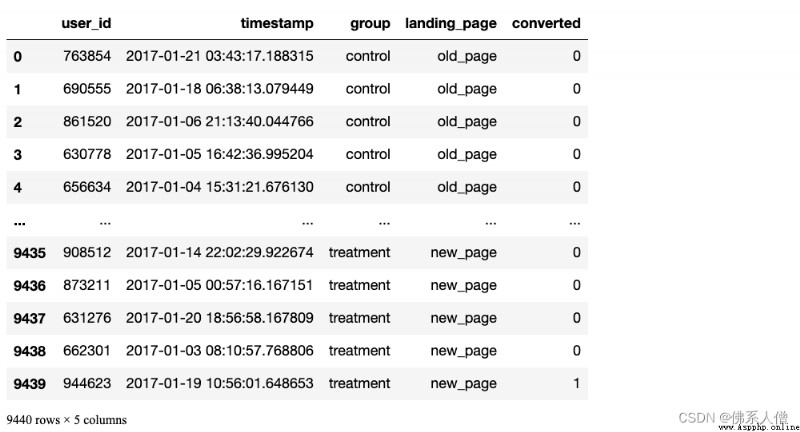
DataFrame Oui.294478 D'accord, Chaque ligne représente une session utilisateur ,Et5 Colonnes:
user_id- Utilisateurs par session ID
timestamp- L'horodatage de la session
group- Quel groupe d'utilisateurs est affecté à cette session { controlGroupe, treatmentGroupe}
landing_page- Les dessins que chaque utilisateur voit dans cette session { old_page( Ancienne page ), new_page}(Nouvelle page)
converted- Si la session est convertie (0= Non converti ,1=Transformation)
Nous n'utiliserons que groupEtconverted Colonne à analyser .
Avant de procéder à l'échantillonnage des données pour obtenir notre sous - ensemble , Assurons - nous qu'aucun utilisateur n'est échantillonné plus d'une fois .
Oui. 3894 Plus d'une fois, des utilisateurs sont apparus . Parce que le nombre est très faible , Nous continuerons à les extraire de DataFrame Supprimer, Pour éviter d'échantillonner deux fois le même utilisateur .
sers_to_drop = session_counts[session_counts > 1].index
df = df[~df['user_id'].isin(users_to_drop)]
print(f' L'ensemble de données mis à jour a maintenant {
df.shape[0]}Entrées')
Échantillonnage
Maintenant notre DataFrame Propre et propre, On peut continuer et n=4720 Échantillonner les entrées pour chaque groupe .On peut utiliser pandas DeDataFrame.sample() Méthode pour effectuer cette opération , Il effectuera un échantillonnage aléatoire simple pour nous .
Attention!random_state=22: Si vous souhaitez travailler sur votre propre carnet , J'ai réglé pour reproduire les résultats :C'est tout.random_state=22 Utilisez , Vous devriez avoir le même exemple que moi .
control_sample = df[df['group'] == 'control'].sample(n=required_n, random_state=22)
treatment_sample = df[df['group'] == 'treatment'].sample(n=required_n, random_state=22)
ab_test = pd.concat([control_sample, treatment_sample], axis=0)
ab_test.reset_index(drop=True, inplace=True)
ab_test
ab_test.info()

Voir la segmentation du Groupe expérimental et du groupe témoin
ab_test['group'].value_counts()
C'est génial.!
3. Visualisation des résultats
conversion_rates = ab_test.groupby('group')['converted']
std_p = lambda x: np.std(x, ddof=0) # Std. Écart proportionnel
se_p = lambda x: stats.sem(x, ddof=0) # Std. Erreur d'échelle (std / sqrt(n))
conversion_rates = conversion_rates.agg([np.mean, std_p, se_p])
conversion_rates.columns = ['conversion_rate', 'std_deviation', 'std_error']
conversion_rates.style.format ('{:.3f}')

D'après les statistiques ci - dessus , On dirait que nos deux dessins sont très similaires. , Notre nouveau design fonctionne un peu mieux ,Environ.12.3% C'est exact. 12.6% Taux de conversion.
Code de visualisation:
plt.figure(figsize=(8,6))
sns.barplot(x=ab_test['group'], y=ab_test['converted'], ci=False)
plt.ylim(0, 0.17)
plt.title( ' Taux de conversion par groupe ', pad=20)
plt.xlabel('Group', labelpad=15)
plt.ylabel('Converted (proportion)', labelpad=15);
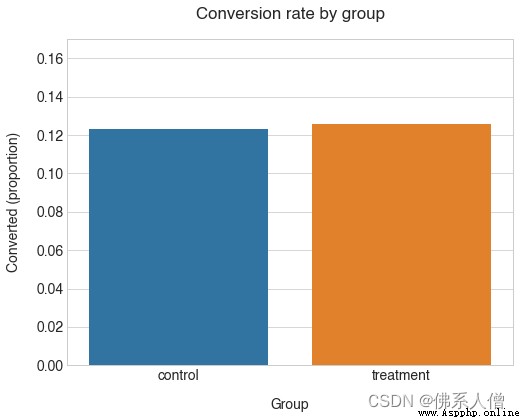
Les taux de conversion de notre groupe sont très proches .Veuillez également noter,control Compte tenu de notre connaissance de la moyenne, , Le taux de conversion de ce groupe est inférieur à nos attentes .Taux de conversion(12.3% C'est exact. 13%). Cela indique certaines différences dans les résultats de l'échantillonnage de la population. .
Alors...treatment Les groupes ont plus de valeur . Cette différence est - elle statistiquement significative? ?
4. Vérifier les hypothèses
La dernière étape de notre analyse est de tester nos hypothèses . Parce que nous avons un très grand échantillon , Nous pouvons utiliser l'approximation normale pour calculer notre pValeur(C'est - à - dire: z Inspection).
Encore une fois,Python Rendre tous les calculs très faciles .Nous pouvons utiliser cecistatsmodels.stats.proportionModule pour obtenirp Valeurs et intervalles de confiance :
from statsmodels.stats.proportion import ratios_ztest, ratio_confint
control_results = ab_test[ab_test['group'] == 'control']['converted']
treatment_results = ab_test[ab_test['group'] == 'treatment']['converted']
n_con = control_results.count()
n_treat = treatment_results.count()
Succès = [control_results.sum(),treatment_results.sum()]
nobs = [n_con, n_treat]
z_stat, pval = ratios_ztest(successes, nobs=nobs)
(lower_con , lower_treat), (upper_con, upper_treat) = ratio_confint(successes, nobs=nobs, alpha=0.05)
print(f'z statistic: {
z_stat:.2f}')
print(f'p-value: {
pval:.3f }')
print(f'ci 95% for control group: [{
lower_con:.3f}, {
upper_con:.3f}]')
print(f'ci 95% for treatment group: [{
lower_treat:.3f}, {
upper_treat:.3f}]')

5. Tirer des conclusions
Grâce à notrep -value=0.732 Bien au - dessus de notre α=0.05Seuil, On ne peut pas refuser l'hypothèse zéro Hₒ, Cela signifie que notre nouveau design n'est pas très différent de l'ancien. ( Et encore moins mieux )
En outre,Si nous regardonstreatment Intervalle de confiance pour le Groupe ([0.116, 0.135] Ou 11.6-13.5%),Nous remarquerons:
Ça nous inclut 13% Valeur de référence du taux de conversion
Ça ne nous inclut pas 15% Valeur cible pour(Notre objectif est 2% Promotion de)
Cela signifie que le taux de conversion réel de la nouvelle conception est plus susceptible d'être similaire à notre base de référence. ,Au lieu de ce que nous espérions 15% Objectifs. Cela prouve en outre qu'il est peu probable que notre nouveau design soit une amélioration par rapport à l'ancien. .