Pandas數據可以實現縱向和橫向連接,將數據連接後會形成一個新對象(Series或DataFrame)
連接是最常用的多個數據合並操作
pd.concat()是專門用於數據連接合並的函數,它可以沿著行或列進行操作,同時可以指定非合並軸的合並方式(如合集、交集等)
pd.concat()會返回一個合並後的DataFrame
語法
pd.concat(objs, axis=0, join='outer', ignore_index=False,
keys=None, levels=None, names=None, sort=False,
verify_integrity=False, copy=True)
參數
objs: 需要連接的數據,可以是多個DataFrame或者Series,它是必傳參數
axis: 連接軸的方法,默認值為0,即按行連接,追加在行後面;值為1時追加到列後面(按列連接:axis=1)
join: 合並方式,其他軸上的數據是按交集(inner)還是並集(outer)進行合並
ignore_index: 是否保留原來的索引
keys: 連接關系,使用傳遞的鍵作為最外層級別來構造層次結構索引,就是給每個表指定一個一級索引
names: 索引的名稱,包括多層索引
verify_integrity: 是否檢測內容重復;參數為True時,如果合並的數據與原數據包含索引相同的行,則會報錯
copy: 如果為False,則不要深拷貝
pd.concat()的基本操作可以實現df.append()功能
操作中ignore_index和sort參數的作用是一樣的,axis默認取值為0,即按行連接
import pandas as pd
df1 = pd.DataFrame({'x':[1,2],'y':[3,4]})
df2 = pd.DataFrame({'x':[5,6],'y':[7,8]})
res1 = pd.concat([df1,df2])
# 效果同上
res2 = df1.append(df2)
df1

df2

res1

res2

如果要將多個DataFrame按列拼接在一起,可以傳入axis=1參數,這會將不同的數據追加到列的後面,索引無法對應的位置上將值填充為NaN
import pandas as pd
df1 = pd.DataFrame({'x':[1,2],'y':[3,4]})
df2 = pd.DataFrame({'x':[5,6,0],'y':[7,8,0]})
res = pd.concat([df1,df2], axis=1)
df1

df2
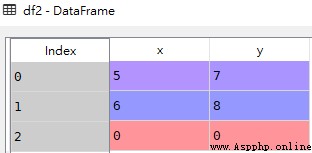
res
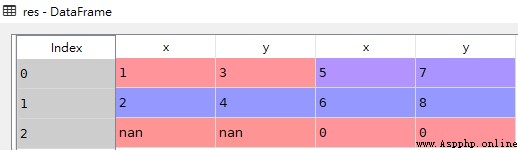
該例子中,df2比df1多一行,合並後df1的部分為NaN
上述兩個練習案例的連接操作會得到兩個表內容的並集(默認是join='outer')
合並交集需要將join參數進行改變 join='inner'
import pandas as pd
df1 = pd.DataFrame({'x':[1,2],'y':[3,4]})
df2 = pd.DataFrame({'x':[5,6,0],'y':[7,8,0]})
# 按列合並交集
# 傳入join=’inner’取得兩個DataFrame的共有部分,去除了df1沒有的第三行內容
res = pd.concat([df1,df2], axis=1, join='inner')
df1

df2
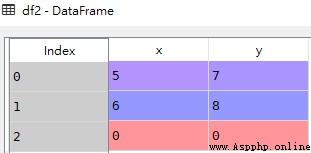
res

擴展
通過reindex()方法也可以實現取交集功能
# 兩種方法
res1 = pd.concat([df1,df2],axis=1).reindex(df1.index)
res2 = pd.concat([df1,df2.reindex(df1.index)],axis=1)res1

res2

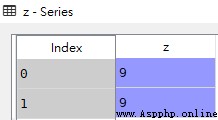
import pandas as pd
z = pd.Series([9,9],name='z')
df = pd.DataFrame({'x':[1,2],'y':[3,4]})
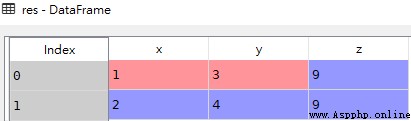
# 將序列加到新列
res = pd.concat([df,z],axis=1)z
df

res
import pandas as pd
df1 = pd.DataFrame({'x':[1,2],'y':[3,4]})
df2 = pd.DataFrame({'x':[5,6],'y':[7,8]})
# 指定索引名
res1 = pd.concat([df1,df2], keys=['a','b'])
# 以字典形式傳入
dict = {'a':df1, 'b':df2}
res2 = pd.concat(dict)
# 橫向合並,指定索引
res3 = pd.concat([df1,df2], axis=1, keys=['a','b'])df1

df2

res1

res2

res3