Pandas有2種數據結構,分別是Series和DataFrame
Series類似表格中的一個列(column),類似於一維數組,可以保存任何數據類型
Series由索引(index)和列組成
提示
索引起到解釋、定位數據的作用,Series是Pandas最基礎的數據結構
語法
import pandas as pd
pd.Series(data, index, dtype, name, copy)參數說明
data: 一組數據(ndarray類型)
index: 數據索引標簽,如果不指定,默認從0開始
dtype: 數據類型,默認會自己判斷
name: 設置名稱
copy: 拷貝數據,默認為False
實例
import pandas as pd
arr = [1, 2, 3]
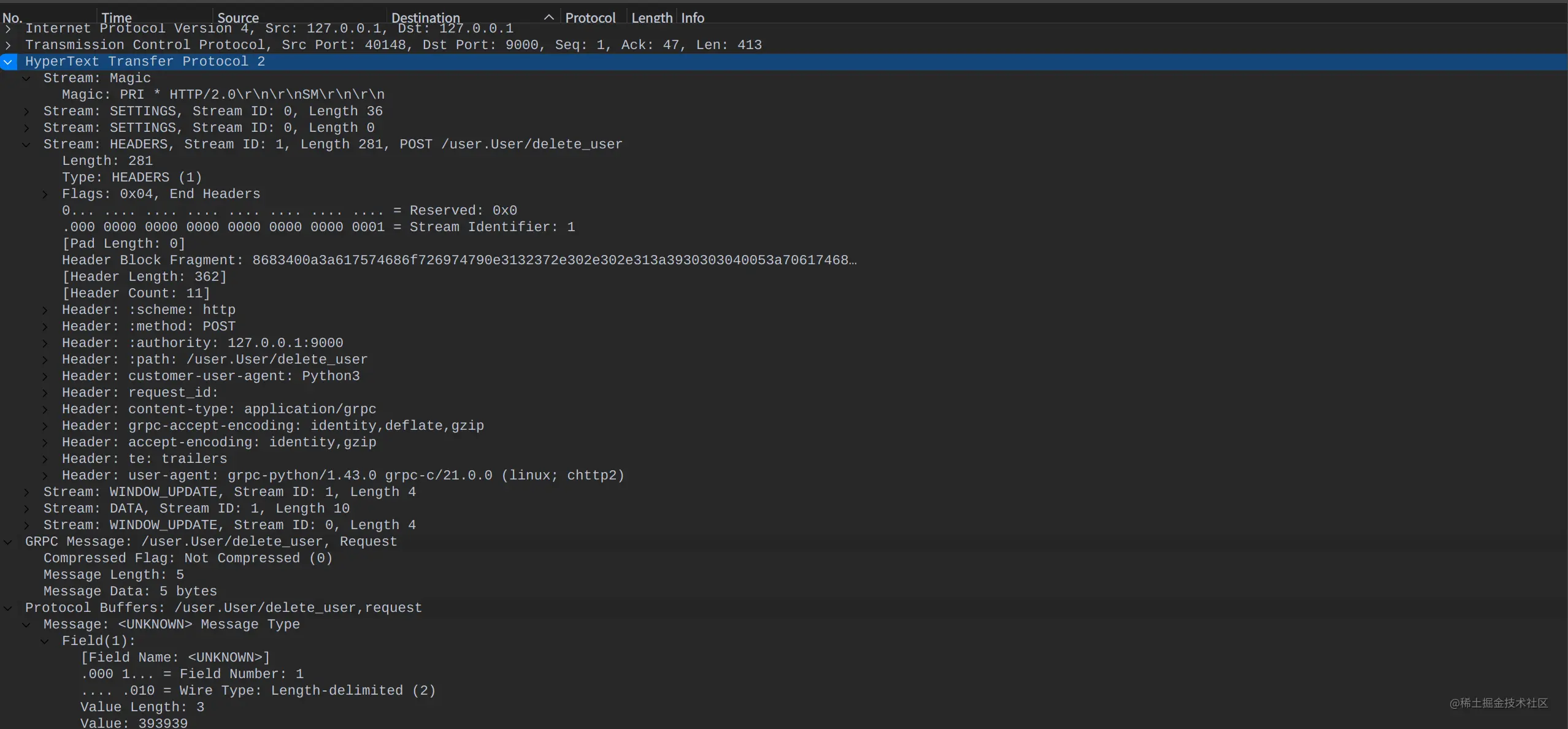
res1 = pd.Series(arr)
# 根據索引值讀取數據
res1[1] # 2
# 指定索引值
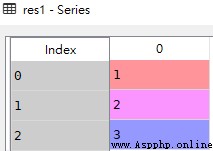
res2 = pd.Series(arr, index = ['x','y','z'])
# 根據索引值讀取數據
res2['y'] # 2
res1
從上圖可知,如果沒有指定索引,索引值就從0開始
res2
使用key/value對象,類似字典來創建Series
import pandas as pd
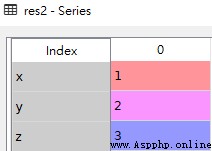
dicts = {1: "Odin", 2: "Jack", 3: "Lee"}
res3 = pd.Series(dicts)res3
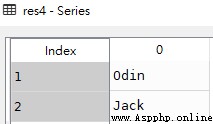
從上圖可知,字典的key變成了索引值
如果我們只需要字典中的一部分數據,只需要指定需要數據的索引即可
import pandas as pd
dicts = {1: "Odin", 2: "Jack", 3: "Lee"}
res4 = pd.Series(dicts, index = [1, 2])res4
設置Series名稱參數
import pandas as pd
dicts = {1: "Odin", 2: "Jack", 3: "Lee"}
pd.Series(dicts, index = [1, 2], name='Hudas')
未設置Series名稱參數
import pandas as pd
dicts = {1: "Odin", 2: "Jack", 3: "Lee"}
pd.Series(dicts, index = [1, 2])
DataFrame是一個表格型的數據結構,它含有一組有序的列,每列可以是不同的值類型(數值、字符串、布爾型值)
DataFrame既有行索引也有列索引,它可以被看做由多個Series組成的字典(共同用一個索引)
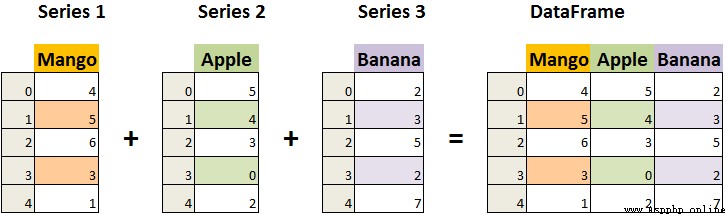
DataFrame是Pandas定義的一個二維數據結構
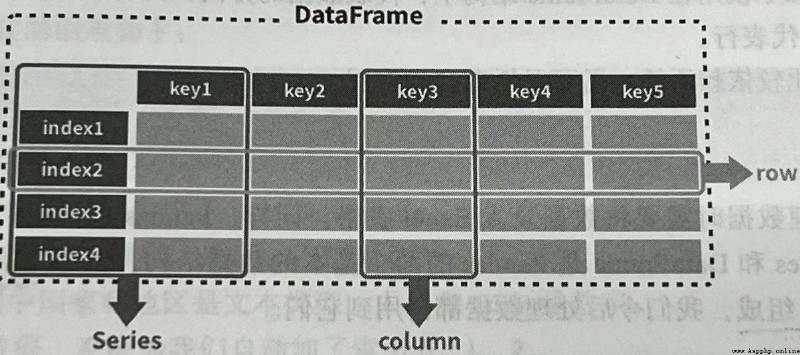
橫向的稱作行(row),一條數據就是指其中的一行
縱向的稱作列(column)或字段,是一條數據的某個值
第一行是表頭或者叫字段名,類似於Python字典裡的鍵,代表數據的屬性
第一列是索引,就是這行數據所描述的主體,也是這條數據的關鍵
在一些場景下,表頭稱為列索引,索引稱為行索引
語法
import pandas as pd
pd.DataFrame(data, index, columns, dtype, copy)參數說明
data: 一組數據(ndarray、series, map, lists, dict 等類型)
index: 索引值,或者可以稱為行標簽
columns: 列標簽,默認為 RangeIndex (0, 1, 2, …, n)
dtype: 數據類型
copy: 拷貝數據,默認為 False
2.1 使用列表創建DataFrame
import pandas as pd
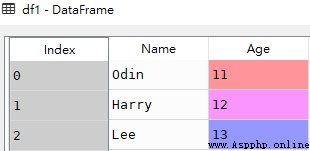
data = [['Odin',11],['Harry',12],['Lee',13]]
df1 = pd.DataFrame(data,columns=['Name','Age'],dtype=float)df1
2.2 使用ndarrays創建DataFrame
import pandas as pd
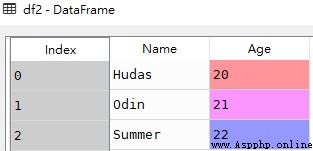
data = {'Name':['Hudas', 'Odin', 'Summer'], 'Age':[20, 21, 22]}
df2 = pd.DataFrame(data)df2
2.3 使用字典key/value創建DataFrame
import pandas as pd
# 字典的key為列名
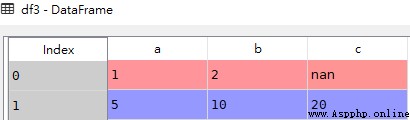
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
df3 = pd.DataFrame(data)df3
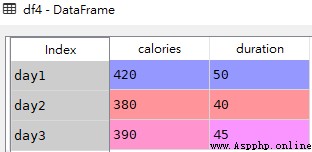
import pandas as pd
data1 = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
df4 = pd.DataFrame(data1, index = ["day1", "day2", "day3"])df4