Pandas Data can be realized The longitudinal and The transverse Connect , After connecting the data, a new object will be formed (Series or DataFrame)
Join is the most common multiple data merge operation
pd.concat() Is a special function for data connection merging , It can operate along rows or columns , At the same time, you can specify the merging method of non merging axes ( Such as collection 、 Intersection, etc )
pd.concat() A merged DataFrame
grammar
pd.concat(objs, axis=0, join='outer', ignore_index=False,
keys=None, levels=None, names=None, sort=False,
verify_integrity=False, copy=True)
Parameters
objs: Data to be connected , It can be more than one DataFrame perhaps Series, It is Must pass parameters
axis: The way to connect the shafts , The default value is 0, That is, connect by line , Append after line ; The value is 1 Is appended to the column ( Connect by column :axis=1)
join: Merger method , The data on the other axes is by intersection (inner) Or union (outer) A merger
ignore_index: Whether to keep the original index
keys: Connection relationship , Use the passed key as the outermost level to construct a hierarchical index , It is to assign a primary index to each table
names: Name of index , Including multi tier index
verify_integrity: Whether to detect content duplication ; Parameter is True when , If the merged data contains rows with the same index as the original data , May be an error
copy: If False, Don't make a deep copy
pd.concat() The basic operations of can be realized df.append() function
In operation ignore_index and sort The function of parameters is the same ,axis The default value is 0, That is, connect by line
import pandas as pd
df1 = pd.DataFrame({'x':[1,2],'y':[3,4]})
df2 = pd.DataFrame({'x':[5,6],'y':[7,8]})
res1 = pd.concat([df1,df2])
# The effect same as above
res2 = df1.append(df2)
df1

df2

res1
res2

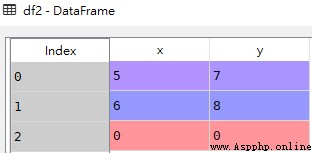
If you want to put multiple DataFrame Spliced together by columns , You can pass in axis=1 Parameters , This appends different data to the end of the column , The index cannot correspond to the location Fill the value with NaN
import pandas as pd
df1 = pd.DataFrame({'x':[1,2],'y':[3,4]})
df2 = pd.DataFrame({'x':[5,6,0],'y':[7,8,0]})
res = pd.concat([df1,df2], axis=1)
df1

df2
res
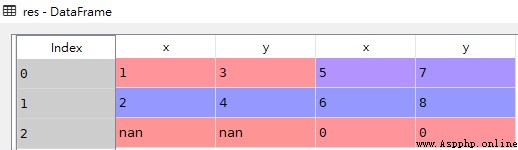
In this example ,df2 Than df1 One more line , After the merger df1 Part of the NaN
The join operation of the above two exercise cases will result in the union of the contents of the two tables ( The default is join='outer')
Merging intersections requires that join Change the parameters join='inner'
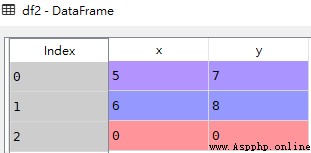
import pandas as pd
df1 = pd.DataFrame({'x':[1,2],'y':[3,4]})
df2 = pd.DataFrame({'x':[5,6,0],'y':[7,8,0]})
# Merge intersections by column
# Pass in join=’inner’ Get two DataFrame The common parts of , In addition to the df1 There is no third line
res = pd.concat([df1,df2], axis=1, join='inner')
df1

df2
res

Expand
adopt reindex() Method can also realize the function of taking intersection
# The two methods
res1 = pd.concat([df1,df2],axis=1).reindex(df1.index)
res2 = pd.concat([df1,df2.reindex(df1.index)],axis=1)res1

res2
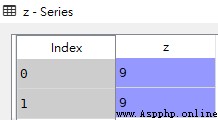
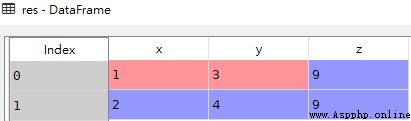
import pandas as pd
z = pd.Series([9,9],name='z')
df = pd.DataFrame({'x':[1,2],'y':[3,4]})
# Add sequence to new column
res = pd.concat([df,z],axis=1)z
df

res
import pandas as pd
df1 = pd.DataFrame({'x':[1,2],'y':[3,4]})
df2 = pd.DataFrame({'x':[5,6],'y':[7,8]})
# Specify the index name
res1 = pd.concat([df1,df2], keys=['a','b'])
# In the form of a dictionary
dict = {'a':df1, 'b':df2}
res2 = pd.concat(dict)
# Horizontal merger , Specify the index
res3 = pd.concat([df1,df2], axis=1, keys=['a','b'])df1

df2

res1

res2

res3