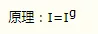Now playing games doesn't have a skin , I am ashamed to say that I played the game , It is said that a certain skin has an attack range bonus , I don't know if it's true. , Let's all climb it down today ~

The software we use here is
Python 3.8
Pycharm
If you don't have one, just scan it on the far left
modular
requests >>> Data request module Third-party module
re >>> Regular expressions Parsing data Built-in module No installation required
os >>> File operations Automatically create folders Built-in module No installation required
win+r Input cmd , Then input pip install requests Direct installation
If it fails , Read my top article .
technological process
Full video explanation , If you do, you can leave it alone
My cousin asked me for the king's skin for the new year's gift , I use... Directly python I gave him a full skin !
Not much code , A little bit , It can be done according to the process , Beginners can watch the above video if they can't .
import requests # Data request module Third-party module pip install requests
import re # Regular expression module Built-in module
import os # File operation module
# 1. Send a request
url = 'https://***.com/web201605/js/herolist.json' # Confirm the request url
# add headers Request header for camouflage
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36'
}
# adopt requests In this module get The request method is for url Address send request , And carry it with you headers Request header camouflage , Last use response Variable receive return data
response = requests.get(url=url, headers=headers)
# print(response.json()) # <class 'list'>
# print(type(response.json()))
# print(response.text) # <class 'str'>
# print(type(response.text))
# 2. get data , Get the information returned by the server response The response data
# 3. Parsing data , Extract the data content we want ID as well as Hero's name
for index in response.json():
# Dictionary values According to the content to the left of the colon Extract the content to the right of the colon Key value pair value
hero_id = index['ename'] # hero ID
hero_name = index['cname'] # Hero's name
# Relative paths Which folder is your code in , What is generated is that
# Absolute path Specify the hard disk and the file
path = f'{
hero_name}\\'
if not os.path.exists(path): # Determine whether this folder exists
os.mkdir(path) # Not created
# String formatting method
hero_url = f'https://****.com/web201605/herodetail/{
hero_id}.shtml'
# 4. Send a request , Send a request for the hero's details page
response_1 = requests.get(url=hero_url, headers=headers)
# Garbled code encountered , Transcoding directly
response_1.encoding = response_1.apparent_encoding # Automatic identification code
# print(hero_id, hero_name, hero_url)
# print(response_1.text)
title_info = re.findall('<ul class="pic-pf-list pic-pf-list3" data-imgname="(.*?)">', response_1.text)[0]
title_info = re.sub('&\d+', '', title_info).split('|')
# len(title_info) >>> 4 # Count the number of elements in the list ,
print(title_info) # len(title_info) + 1 >>> 5
for i in range(1, len(title_info) + 1): # Head and tail
img_url = f'https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{
hero_id}/{
hero_id}-bigskin-{
i}.jpg'
img_name = title_info[i-1]
print(img_name, img_url)
img_content = requests.get(url=img_url, headers=headers).content # Get binary image data
with open(path + str(img_name) + '.jpg', mode='wb') as f:
f.write(img_content)
print(hero_name, img_name)
brothers , Let's try
 [Python seckill script] Taobao or Jingdong and other seckill purchases
[Python seckill script] Taobao or Jingdong and other seckill purchases
文章目錄前言一、環境二、安裝1.ChromeDriver安裝
 Summary of list (list, array) operations in Python standard library (about 25 operations), with sample code
Summary of list (list, array) operations in Python standard library (about 25 operations), with sample code
Python List in the standard li