理解Python的序列的基本概念.
掌握字符串/列表/元組/字典的基本使用方法.
理解列表和元組的區別和各自的應用場景.
理解Python中的深拷貝和淺拷貝.
理解字典 “鍵值對” 這樣的概念
包含若干個元素, 元素有序排列, 可以通過下標訪問到一個或者多個元素. 這樣的對象, Python中統一稱為序列(Sequence).
Python中的以下對象都屬於序列
同是序列, 他們的使用方式有很多相通之處
注意:序列裡面的元素的順序很重要,因為比較是按順序比
a = [1,2,3]
b = [3,2,1]
print(a ==b) #False
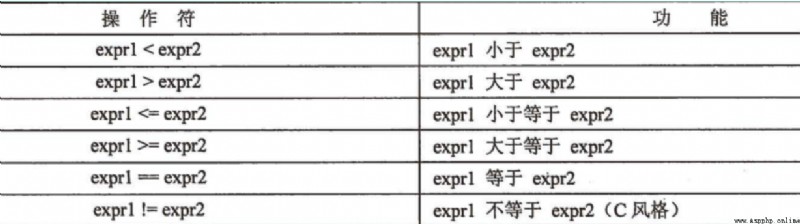
下列標准類型操作符, 大多數情況下都是適用於序列對象的(少部分特例是, 序列中保存的元素不支持標准類型操作符).
a = [1,2,3,4]
print(3 in a) #True
print(3 not in a) #False
a = [1,2,3,4]
b = [5,6]
print(a+b) #返回一個新列表,包含了a和b的所有元素[1, 2, 3, 4, 5, 6]
a = [1,2,3,4]
b = [5,6]
a.extend(b) #相當於把b的元素都插入到a的後面
print(a) #[1, 2, 3, 4, 5, 6]
a =[1,2,3]
print(a*3) #[1, 2, 3, 1, 2, 3, 1, 2, 3]
a =[1,2,3]
print(a[100])
#執行結果:
IndexError: list index out of range
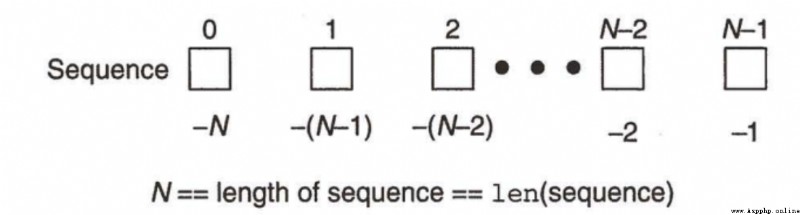
關於切片:左閉右開區間
方式1:[:] 左右兩個端點都不寫值,截取的是整個序列的元素,從頭到尾
a =[1,2,3,4,5]
print(a[:])#[1, 2, 3, 4, 5]
方式2:[A:B]
元素下標取值范圍: [A,B)
a =[1,2,3,4,5]
print(a[1:3]) #[2,3] 截取下標[1,3)的元素
print(a[1:-1]) #[2,3,4] 截取下標[1,-1)的元素
print(a[:3]) #[1,2,3] 截取下標[0,3)的元素
print(a[1:]) #[2,3,4,5] 截取下標[1,-1)的元素
如果左邊端點不寫,默認從0開始, 右邊端點不寫,默認截取到最後一個位置(即:-1位置)
方式3:[A:B:C] 第三個參數表示步長,即每隔多少個元素截取一個
例子:
a = [1,2,3,4,5]
print(a[::2]) #每兩個元素截取一個
#執行結果:
[1,3,5]
字符串翻轉, 這是一個非常基礎, 也是筆試面試中會經常出現的一個題目. 我們學過C/C++, 有三種方法來解決這個問題.
方法1:首尾指針
char str[] = "abcdefg";
char* beg = str;
char* end = str + strlen(str);
while (beg < end) {
swap(*beg++, *--end);
}
方法2:棧
char str[] = "abcdefg";
Stack stack;
char* p = str;
while(p) {
stack.push(*p++);
}
int index = 0;
while(!stack.empty()){
str[index++] = stack.top();
stack.pop();
}
方法3:使用reverse + 迭代器翻轉
#include <algorithm>
char str[] = "abcdefg";
std::reverse(str, str + strlen(str)); //指針就是天然的迭代器
python的做法:
a = "abcdefg"
print(a[::-1])
這個代碼的含義:
a[::-1] -1表示往前走,從後往前拿元素
a = [1,2,3,4,5,6]
print(a[::-1]) #[6,5,4,3,2,1]
#含義
從-1位置往前走,先走到下標為-1位置,然後從6開始往前走
對於切片語法來說, 下標越界也沒關系. 因為取的是前閉後開區間,區間裡的元素, 能取到多少就取到
多少.
len: 返回序列的長度.
a = [2,3,4,5]
print(len(a)) #4
b = "hello"
print(len(b)) #5
max: 返回序列中的最大值
a = [2,3,4,5]
print(max(a)) #5
b = "helloz"
print(max(b)) #z
min: 返回序列中的最小值
a = [2,3,4,5]
print(min(a)) #2
b = "helloz"
print(min(b)) #e
sorted: 排序. 這是一個非常有用的函數. 返回一個有序的序列(輸入參數的副本).
a = ['abc','acb','a','b']
print(sorted(a)) #['a', 'abc', 'acb', 'b']
a = [5,3,3,1,5]
print(sorted(a)) #[1, 3, 3, 5, 5]
sorted可以支持自定制排序規則
sum: 序列中的元素求和(要求序列中的元素都是數字)
a = [1,2,3,4,5]
print(sum(a)) #15
a= [1,'a']
print(sum(a)) #報錯 unsupported operand type(s) for +: 'int' and 'str'
enumerate: 同時枚舉出序列的下標和值 可以避免很多丑陋的代碼.
例如:找出元素在列表中的下標
a = [1,2,3,4,5]
def Find(input_list,x):
for i in range(0,len(input_list)):
if input_list[i] == x:
return i
else: #此處的else和for搭配
return None
print(Find(a,2)) #1 下標為1
這裡用for循環寫的就不夠優雅,使用enumerate函數就可以寫的很優雅
a = [1,2,3,4,5]
def Find(input_list,x):
for i ,item in enumerate(input_list):
if item == x:
return i
else: #此處的else和for搭配
return None
print(Find(a,2)) #1 下標為1
zip: 這個函數的本意是 “拉鏈”,
x = [1,2,3]
y = [4,5,6]
z = [7,8,9,10] #多余的10不要,3行3列
print(zip(x,y,z)) #直接打印是對象的id <zip object at 0x000001581CFE7748>
#把執行結果強轉為list,列表
print(list(zip(x,y,z))) #[(1, 4, 7), (2, 5, 8), (3, 6, 9)]
#直觀打印
for i in zip(x,y,z):
print(i)
#執行結果:
(1, 4, 7)
(2, 5, 8)
(3, 6, 9)
zip可以理解為行列互換
zip的一個比較常見的用法, 就是構造字典
key = ('name','id','score')
value =('Mango','2022','99')
d = dict(zip(key,value)) #執行結果轉為一個字典
print(d) # {'name': 'Mango', 'id': '2022', 'score': '99'}
a = 'abcd'
a[0] ='z' #TypeError: 'str' object does not support item assignment
a = 'z'+a[1:]
print(a) #zbcd
==, !=, <, <=, >, >= 這些操作符的行為前面已經提到過.
需要記得字符串比較大小是按照字典序.
a = 'abc'
b = 'ab'
print(a != b) #True
print(a < b) #False 按照字典序比較
a = 'abc'
print('a' in a) #True
print('z' in a) #False
a = 'abcd'
print(a[1:2]) #b
print(a[:2]) #ab
print(a[1:]) #bcd
print(a[:]) #abcd
print(a[::2]) #ac
x = 1
print('x = %d' %x) # x = 1
x = 10
y = 20
a = 'x = %d y = %d' %x #缺少參數:報錯 TypeError: not enough arguments for format string
#正解:
x = 10
y = 20
a = 'x = %d y = %d' %(x,y)
推薦寫法:加前綴f
x = 10
y = 20
a = f'x = {
x},y={
y}'
print(a) #x = 10,y=20
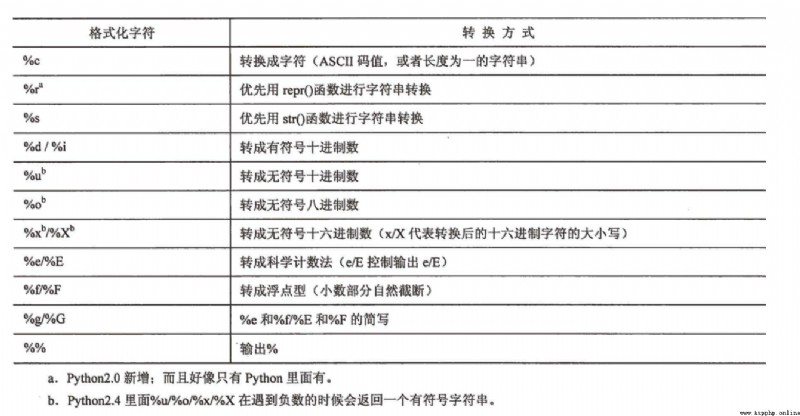
支持以下這些格式化字符串:
有的時候, 我們需要有 \n 這樣的字符作為轉義字符**. 但是有些時候我們又不希望進行轉義, 只需要原始的**
\n 作為字符串的一部分.
原始字符串中, 轉義字符不生效
例子:QQ發消息時, 有一個 “表情快捷鍵” 的功能. 這個功能就相當於 “轉義字符”.
當開啟了這個功能之後, 在輸入框中輸入 /se 就會被替換成一個表情. 比如我給同事發一個目錄 /search/odin (這本來是表示linux上的一個目錄)
這種情況下, 我們需要關閉 “表情快捷鍵” 功能. 對於Python來說, 我們就可以使用原始字符串來解決這個問題.
print(r'hello \n world') #hello \n world
a = 1
print(type(repr(a))) #<class 'str'> 字符串類型
print(str('hello')) # hello
print(repr('hello')) # 'hello'
總結一下, str轉換出的字符串是給人看的. 而repr轉換出的字符串, 是給Python解釋器看的.

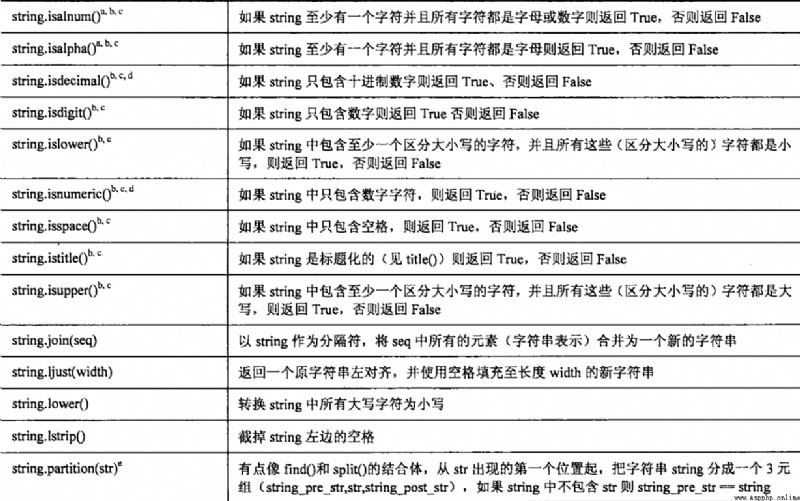


將序列中的字符串合並成一個字符串. join函數
a = ['aa','bb','cc']
b = ' '.join(a)
print(b) #aa bb cc
按空格將字符串分割成列表split函數
a = 'aa bb cc'
b = a.split(' ')
print(b) #['aa', 'bb', 'cc']
通常和join函數一起使用
a = 'aaa,bbb,ccc'
b = a.split(',') #以,分割成列表
print(b)
print(';'.join(b)) #分號連接
print('hello'.join(b))
#執行結果:
['aaa', 'bbb', 'ccc']
aaa;bbb;ccc
aaahellobbbhelloccc
判定字符串開頭結尾 startswith函數 和 endswith函數
a = 'hello world'
print(a.startswith('h')) #True
print(a.startswith('hee')) #False
print(a.endswith('d')) #True
去除字符串開頭結尾的空格/制表符 strip函數
空白字符:空格,換行,tab
a = ' hello world '
print(a.strip()) #hello world
去掉左側的空白字符:lstrip
去掉右側的空白字符: rstrip
a =' hello \n'
print(f'[{
a.lstrip()}]') #為了方便看,加上[]
print(f'[{
a.rstrip()}]')
print(f'[{
a.strip()}]')
#執行結果:
[hello
]
[ hello]
[hello]
左對齊/右對齊/中間對齊 ljust rjust center函數
a = ' hello world'
print(a.ljust(30))
print(a.rjust(30))
print(a.center(30))
#執行結果:
hello world
hello world
hello world
查找子串 find函數
a = ' hello world'
print(a.find('hello')) #4
a = 'hello hello '
print(a.find('h')) #0
返回第一次出現的下標
和in差不多,in返回的是布爾值
a = ' hello world'
print(a.find('hello')) #4
print('hello' in a) #True
替換子串(記得字符串是不可變對象, 只能生成新字符串). replace函數
a= 'hello world'
print(a.replace('world','python')) #hello python
print(a) #hello world 字符串是不可變對象, 只能生成新字符串
判定字符串是字母/數字 isalpha函數 和 isdigit函數
a = 'hello 1'
print(a.isalpha()) #False
a = '1234'
print(a.isdigit()) #True
轉換大小寫 lower和upper函數
a = 'Hello world'
print(a.lower()) #hello world
print(a.upper()) #HELLO WORLD
學過C語言的同學, 可能會問, Python的字符串是否需要 ‘\0’ 之類的結束符來做結尾?
字符串只能由字符組成, 而且不可變; 但是列表中可以包含任意類型的對象, 使用更加靈活.
a = [1,2,3,4]
a[0] = 100
print(a) #[100,2,3,4]
把append的東西當成一個元素
a = [1,2,3]
a.append('a')
print(a) #[1,2,3,'a']
注意:使用append:是把元素當成整體插入
a = [1,2]
a.append([3,4]) #插入的是個整體
print(a) #[1,2,[3,4]] 二維列表
print(len(a)) #3
a = [1,2,3]
del(a[0])
print(a) #[2,3]
a = [1,2,3]
a.remove(1)
print(a) #[2, 3]
#如果元素不存在,就會報錯
a.remove(4) #報錯 ValueError: list.remove(x): x not in list
== != 為判定所有元素都相等, 則認為列表相等;
< <= > >= 則是兩個列表從第一個元素開始 依次比較, 直到某一方勝出. 按順序比較
a = ['abc',12]
b = ['acb',123]
c = ['abc',11]
print(a<c) #False
print(b<c) #False
print(b >c and a > c) #True
a = [1,2,3]
b = [3,2,1]
print(a <b) #True 按順序比
a = [1,2,3]
b = ['a','b']
print(a<b) #報錯:TypeError: '<' not supported between instances of 'int' and 'str'
時間復雜度O(N)
a = [1,2,3,'a']
print('a' in a) #True
print(4 in a) #False
a和b都不變,生成新對象
a = [1,'a']
b = [2,'b']
print(a+b) #[1, 'a', 2, 'b']
如果使用append:是把元素當成整體插入
a = [1,2]
a.append([3,4]) #插入的是個整體
print(a) #[1,2,[3,4]]
print(len(a)) #3
使用extend
可以理解成 += (列表不支持 += 運算符)
a = [1,2]
a.extend([3,4])
print(a) #[1,2,3,4]
print(len(a)) #4
a = [1,2]
print(a*3) #[1, 2, 1, 2, 1, 2]
如果下標很大,插入到最後面
insert沒有返回值:
a =[1,2,3]
print(a.insert(0,0)) #None
例子:
a=[1,2,3]
a.insert(0,0) #在0下標位置插入0
a.insert(100,100) #在下標100位置插入100
print(a) #[0, 1, 2, 3, 100]
a = [1,2,3,'ac']
a.reverse()
print(a) #['ac', 3, 2, 1]
也可以通過切片翻轉 a[::-1]和reverse翻轉的區別:
切片翻轉不修改原來對象,生成新對象, reverse翻轉修改原來對象
這個是列表內置的成員函數,和sorted不同
例如, 排序. 我們前面講序列的時候, 有一個內建函數sorted, sorted生成了一個新的有序的序列. 列表自身還有一個成員函數sort, 是基於自己本身做修改, 並不生成新對象.

a = [4,3,2,1]
sorted(a)#內建函數sorted
print(a)#[4, 3, 2, 1] a不改變
a.sort()#成員函數sort
print(a)#[1, 2, 3, 4]
a.sort(reverse=True) #翻轉
print(a) #[4,3,2,1]
關於sort方法, 默認使用歸並排序的衍生算法. 時間復雜度是 O(N*log(N))
a = [4,3,2,1,2,4,2]
print(a.count(2)) # 3
print(a.count(5)) # 0
a = [4,3,2,1]
print(a.index(4)) #0
print(a.index(5)) #報錯 ValueError: 5 is not in list
下標刪除,默認值是-1,刪最後一個元素
如果列表為空還彈出,就會報錯
a =[1]
print(a) #[1]
a.pop()
print(a) #[]
a.pop() #列表為空還彈出,報錯:IndexError: pop from empty list
還可以給下標刪除:如果下標越界會報錯
a = [1,2,3,4]
a.pop(3) #刪除下標為3的元素
print(a) #[1,2,3]
a.pop(6) #報錯 IndexError: pop index out of range
列表自身是可變對象, 因此有些方法是修改自身的, 這種情況下的方法並沒有返回值,
這和字符串操作必須要生成一個新對象, 並不相同.
我們回顧一下數據結構中的堆棧, 這是一種後進先出的數據結構. 可以很容易使用列表進行模擬
a = [] #空列表
a.append(1) #push操作 在棧頂插入元素
print(a[-1]) #top操作 得到棧頂元素
a.pop() #pop操作 彈出棧頂元素
我們回顧一下數據結構中的隊列, 這是一種先進先出的數據結構. 也可以很容易使用列表模擬
a = [] #空列表
a.append(1) #push操作 在隊尾插入元素
print(a[0]) #top操作 得到隊頭元素
a.pop(0) #pop操作 彈出隊頭元素
#定義一個列表對象a.
a = [100, [1, 2]]
#基於a, 用三種方式創建了b, c, d
b = a
c = list(a)
d = a[:]
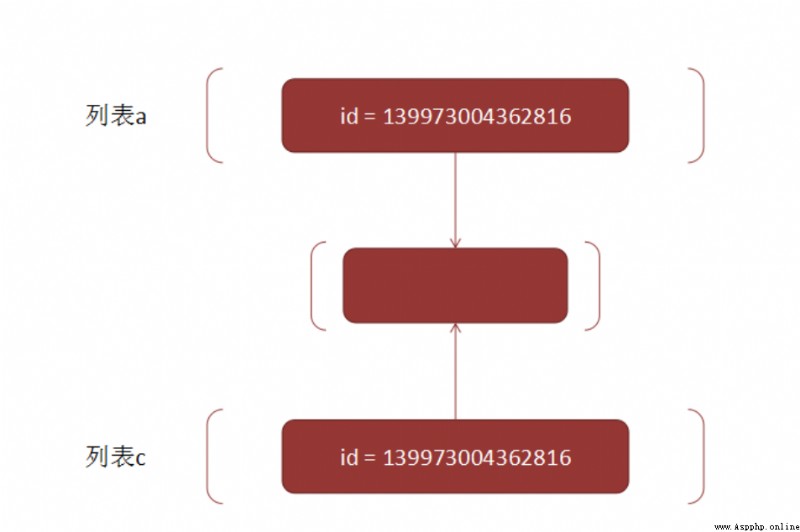
print(id(a), id(b), id(c), id(d)) #a和b同 ,c,d不同 b和a實際上是同一個對象. 而c和d都已經是新的列表對象了.
a[0] = 1
print(a, b, c, d) #a和b受影響 c和d不受影響
a[1][0] = 1000
print(a, b, c, d) #四個都受影響
print(id(a[1]), id(c[1]), id(d[1])) #三者相同
# 執行結果
140541879626136 140541879626136 140541879655672 140541879655744
[1, [1, 2]] [1, [1, 2]] [100, [1, 2]] [100, [1, 2]]
[1, [1000, 2]] [1, [1000, 2]] [100, [1000, 2]] [100, [1000, 2]]
139973004362816 139973004362816 139973004362816
結果稍微有點復雜, 我們一點一點分析
copy.deepcopy 來完成注意:深拷貝 只能針對可變對象使用
進行深拷貝: 需要導入copy模塊
import copy
a = [100, [1, 2]]
b = copy.deepcopy(a)
print(id(a[1]), id(b[1]) )
# 執行結果
139818205071552 139818205117400
這次我們看到, a[1] 和 b[1] 不再是一個對象了.
import copy
a = (100, 'aaa')
b = copy.deepcopy(a)
print(id(a[0]), id(a[1]), id(b[0]), id(b[1]))
# 執行結果
6783664 140700444542616 6783664 140700444542616
想想這是為啥?
進行深拷貝的目的:防止其中一份數據改了,會影響其它數據的結果
深拷貝就是為了改一個另外一個不變,但如果是不可變對象,都不允許修改,需求都不存在,
因為元組的內容本身就不能修改,沒必要進行深拷貝!
元組的很多操作都和列表一致. 唯一的區別是元組的內容是只讀的.
切片操作: 和列表相同
比較運算符, 規則和列表相同
連接操作(+), 重復操作(*), 判定元素存在(in/not in)都和列表相同.
**由於元組不可變, 所以並不支持append, extend, sort,[],等修改自身的操作.**當然了,也不支持深拷貝
回憶我們之前那個牛逼閃閃的交換兩個元素的值的代碼.
x, y = y, x
其實, x, y 就是一個元組. 通過 y, x 這個元組創建了一個新的元組
x = 1
y = 2
x,y = y,x
print(type((x,y))) #<class 'tuple'>
a = ([1,2],[3,4])
a[0][0] = 100
print(a) #([100, 2], [3, 4])
元組:用
,逗號分開元素
a = (10) #因為可能是(10+2)*2這種表達式,所以a是整數,不是元組
print(type(a)) #<class 'int'>
a = (10,2)
print(type(a)) #<class 'tuple'>
注意:
此處用的是元組重復操作符(*)的概念.
a = (10+20,) *3 #此處沒有逗號,a就是90
print(a) #(30, 30, 30)
print(type(a)) #<class 'tuple'> 元組
“不可變” 真的有必要嘛? 假如我們只是用列表, 能否應付所有的應用場景呢?
答案是否定的. 既然Python的設計者提供了元組這個對象, 那麼一定有一些情況下, 只有元組能勝任, 但是列表無法勝任.
原因1:函數傳參的時候使用元組可以避免函數內部把函數外部的內容修改掉
你有一個列表, 現在需要調用一個API進行一些處理. 但是你有不是特別確認這個API是否會把你的列表數據弄亂. 那麼這時候傳一個元組就安全很多.
a = [1,2,3]
def func(input_list):
input_list[0] = 100
func(a)
print(a) #[100,2,3] 列表可以修改
#如果用的是元組:
a = (1,2,3)
def func(input_list):
input_list[0] = 100
func(a) #報錯:TypeError: 'tuple' object does not support item assignment
print(a)
原因2:元組是可哈希的,元組就可以作為字典的key,而列表是可變的,列表不可以作為字典的key
我們馬上要講的字典, 是一個鍵值對結構. 要求字典的鍵必須是 “可hash對象” (字典本質上也是一個hash表). 而一個可hash對象的前提就是不可變. 因此元組可以作為字典的鍵, 但是列表不行.
a = (1,2,3)
b = {
a:100
}
print(b) # {(1, 2, 3): 100}
#如果是列表:報錯
a = [1,2,3]
b = {
a:100 #TypeError: unhashable type: 'list'
}
print(b)
Python的字典是一種映射類型數據. 裡面的數據是 鍵值對 . Python的字典是基於hash表實現的.
注意:字典的鍵和值的類型, 不需要相同
不同的鍵值用,逗號分割
a = {
10:20,
'key':'value',
'a':True
}
print(a) #{10: 20, 'key': 'value', 'a': True}
字典的key必須是可哈希的,不可變是可hash的必要條件
print(hash((10,20))) #元組可以哈希 3713074054217192181
print(hash([1,2])) #列表不可以哈希 報錯:TypeError: unhashable type: 'list'
a = {
'name':"Mango",'age':20}
print(a) #{'name': 'Mango', 'age': 20}
使用工廠方法 dict
用元組作為參數,元組的每個參數是個列表,列表裡面有兩個值: 一個是鍵 一個是值
a = dict((['name',"Mango"],['age',20]))
print(a) #{'name': 'Mango', 'age': 20}
a = {
}.fromkeys(('name',"Ename"),"Mango")
print(a) #{'name': 'Mango', 'Ename': 'Mango'}
a = {
}.fromkeys(('name'),"Mango")
print(a) #{'n': 'Mango', 'a': 'Mango', 'm': 'Mango', 'e': 'Mango'}
注意:字典的鍵和值的類型,不需要相同.
a = {
'name':"Mango",'age':20}
print(a['name']) #Mango
print(a['age']) #20
a = {
'name':"Mango",'age':20}
for item in a: #item相當於每個鍵
print(item,a[item]) #打印鍵 和 值
#執行結果:
name Mango
age 20
注意:字典中的鍵值對, 順序是不確定的(回憶hash表的數據結構, 並不要求key有序).
使用 [] 可以新增/修改字典元素. -> 如果key不存在, 就會新增; 如果已經存在, 就會修改.
a = {
} #空字典
a['name'] ="Mango"
print(a) #{'name': 'Mango'}
a['name'] = "Lemon"
print(a) #{'name': 'Lemon'}
a = {
'name':"Mango",'age':20}
del a['name']
print(a) #{'age': 20}
a = {
'name':"Mango",'age':20}
a.clear()
print(a) #{} 空字典
a = {
'name':"Mango",'age':20}
b = a.pop('name')
print(a) # {'age': 20}
print(b) # Mango
注意:字典也是可變對象. 但是鍵值對的key是不能修改的
**判定一個key是否在字典中 ** (判斷的是key,不是value)
a = {
'name':"Mango",'age':20}
print('name' in a) #True
print('Mango' in a) #False
len: 字典中鍵值對的數目
a = {
'name':"Mango",'age':20}
print(len(a)) #2
hash: 判定一個對象是否可hash. 如果可hash, 則返回hash之後的hashcode. 否則會運行出錯.
print(hash(())) #3527539 元組不可變,可以哈希
print(hash([])) #TypeError: unhashable type: 'list' 列表可變,不可哈希
返回一個列表, 包含字典的所有的key
a = {
'name':"Mango",'age':20}
print(a.keys()) #dict_keys(['name', 'age'])
返回一個列表, 包含字典的所有value
a = {
'name':"Mango",'age':20}
print(a.values()) #dict_values(['Mango', 20])
返回一個列表, 每一個元素都是一個元組, 包含了key和value
a = {
'name':"Mango",'age':20}
print(a.items()) #dict_items([('name', 'Mango'), ('age', 20)])
集合是基於字典實現的一個數據結構. 集合數據結構實現了很多數學中的交集, 並集, 差集等方法, 可以很方便的進行這些操作.
注意!! 熟練掌握集合操作, 對我們後續解筆試題面試題, 都會有很大幫助.
集合和列表不同,集合的順序沒有影響
a = set([1,2,3])
b = set([3,2,1])
print(a == b) #True
print(a,b) #{1, 2, 3} {1, 2, 3}
a = set([1, 2, 3])
b = set([1, 2, 3, 4])
print(a & b) # 取交集
print(a | b) # 取並集
print(b - a) # 取差集
print(a ^ b) # 取對稱差集(項在a中或者在b中, 但是不會同時存在於a和b中)
#執行結果
{
1, 2, 3}
{
1, 2, 3, 4}
{
4}
{
4}
a =set( [1, 1, 2, 2, 3, 3])
print(a) #{1,2,3}
a = [1,2,1,11,1,1,2]
b = set(a)
print(a) #[1, 2, 1, 11, 1, 1, 2]
print(b) #{1, 2, 11}