understand Python The basic concept of the sequence of .
Mastering strings / list / Tuples / How to use a dictionary .
Understand the differences between lists and tuples and their application scenarios .
understand Python Deep and shallow copies in .
Understand the dictionary “ Key value pair ” This concept
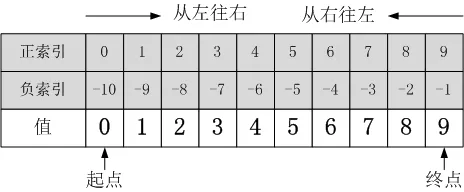
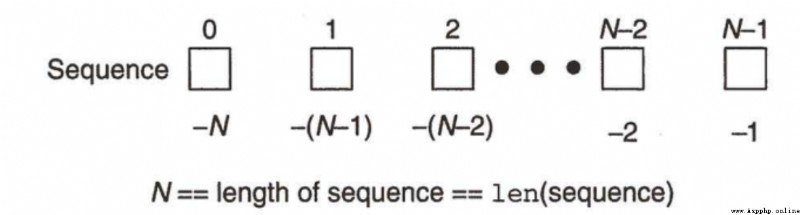
Contains several elements , The elements are arranged in order , One or more elements can be accessed by subscript . Such an object , Python It is uniformly called sequence (Sequence).
Python The following objects in are all part of the sequence
Same sequence , There are many similarities in their ways of use
Be careful : The order of the elements in the sequence is very important , Because the comparison is in order
a = [1,2,3]
b = [3,2,1]
print(a ==b) #False
The following standard type operators , In most cases, it is applicable to sequence objects ( A few exceptions are , Elements saved in a sequence do not support standard type operators ).
a = [1,2,3,4]
print(3 in a) #True
print(3 not in a) #False
a = [1,2,3,4]
b = [5,6]
print(a+b) # Return to a new list , Contains a and b All elements of [1, 2, 3, 4, 5, 6]
a = [1,2,3,4]
b = [5,6]
a.extend(b) # Is equivalent to b All elements of are inserted into a Behind
print(a) #[1, 2, 3, 4, 5, 6]
a =[1,2,3]
print(a*3) #[1, 2, 3, 1, 2, 3, 1, 2, 3]
a =[1,2,3]
print(a[100])
# Execution results :
IndexError: list index out of range
About slicing : Left closed right away Section
The way 1:[:] The left and right endpoints do not write values , What is intercepted is the elements of the entire sequence , From a to Z
a =[1,2,3,4,5]
print(a[:])#[1, 2, 3, 4, 5]
The way 2:[A:B]
Element subscript value range : [A,B)
a =[1,2,3,4,5]
print(a[1:3]) #[2,3] Intercept subscripts [1,3) The elements of
print(a[1:-1]) #[2,3,4] Intercept subscripts [1,-1) The elements of
print(a[:3]) #[1,2,3] Intercept subscripts [0,3) The elements of
print(a[1:]) #[2,3,4,5] Intercept subscripts [1,-1) The elements of
If the left endpoint does not write , The default from the 0 Start , The right endpoint does not write , The default is to intercept to the last position ( namely :-1 Location )
The way 3:[A:B:C] The third parameter represents the step size , That is, every few elements
Example :
a = [1,2,3,4,5]
print(a[::2]) # Intercept one every two elements
# Execution results :
[1,3,5]
String flip , This is a very basic , It is also a topic that often appears in the written examination interview . We have learned C/C++, There are three ways to solve this problem .
Method 1: Head and tail pointer
char str[] = "abcdefg";
char* beg = str;
char* end = str + strlen(str);
while (beg < end) {
swap(*beg++, *--end);
}
Method 2: Stack
char str[] = "abcdefg";
Stack stack;
char* p = str;
while(p) {
stack.push(*p++);
}
int index = 0;
while(!stack.empty()){
str[index++] = stack.top();
stack.pop();
}
Method 3: Use reverse + Iterator flip
#include <algorithm>
char str[] = "abcdefg";
std::reverse(str, str + strlen(str)); // Pointers are natural iterators
python How to do it :
a = "abcdefg"
print(a[::-1])
The meaning of this code :
a[::-1] -1 It means to go forward , Take the elements from the back to the front
a = [1,2,3,4,5,6]
print(a[::-1]) #[6,5,4,3,2,1]
# meaning
from -1 Position forward , Go to the subscript -1 Location , And then from 6 Start walking
For slicing grammar , It doesn't matter if the subscript is out of bounds . Because I took Before closed after opening Section , The elements in the interval , Take as much as you can
How many? .
len: Returns the length of the sequence .
a = [2,3,4,5]
print(len(a)) #4
b = "hello"
print(len(b)) #5
max: Returns the maximum value in the sequence
a = [2,3,4,5]
print(max(a)) #5
b = "helloz"
print(max(b)) #z
min: Returns the minimum value in the sequence
a = [2,3,4,5]
print(min(a)) #2
b = "helloz"
print(min(b)) #e
sorted: Sort . This is a very useful function . Returns an ordered sequence ( Copy of input parameters ).
a = ['abc','acb','a','b']
print(sorted(a)) #['a', 'abc', 'acb', 'b']
a = [5,3,3,1,5]
print(sorted(a)) #[1, 3, 3, 5, 5]
sorted It can support self customized sorting rules
sum: Sum the elements in the sequence ( All elements in the sequence are required to be numbers )
a = [1,2,3,4,5]
print(sum(a)) #15
a= [1,'a']
print(sum(a)) # Report errors unsupported operand type(s) for +: 'int' and 'str'
enumerate: At the same time, the index and value of the sequence are listed You can avoid a lot of ugly code .
for example : Find the subscript of the element in the list
a = [1,2,3,4,5]
def Find(input_list,x):
for i in range(0,len(input_list)):
if input_list[i] == x:
return i
else: # Here else and for collocation
return None
print(Find(a,2)) #1 Subscript to be 1
Here we use for Circular writing is not elegant enough , Use enumerate Function can be written gracefully
a = [1,2,3,4,5]
def Find(input_list,x):
for i ,item in enumerate(input_list):
if item == x:
return i
else: # Here else and for collocation
return None
print(Find(a,2)) #1 Subscript to be 1
zip: The original meaning of this function is “ zipper ”,
x = [1,2,3]
y = [4,5,6]
z = [7,8,9,10] # Redundant 10 Don't ,3 That's ok 3 Column
print(zip(x,y,z)) # Direct printing is an object id <zip object at 0x000001581CFE7748>
# Force the execution result to list, list
print(list(zip(x,y,z))) #[(1, 4, 7), (2, 5, 8), (3, 6, 9)]
# Visual printing
for i in zip(x,y,z):
print(i)
# Execution results :
(1, 4, 7)
(2, 5, 8)
(3, 6, 9)
zip It can be understood as row column interchange
zip A common usage of , Is to construct a dictionary
key = ('name','id','score')
value =('Mango','2022','99')
d = dict(zip(key,value)) # The execution result is converted into a dictionary
print(d) # {'name': 'Mango', 'id': '2022', 'score': '99'}
a = 'abcd'
a[0] ='z' #TypeError: 'str' object does not support item assignment
a = 'z'+a[1:]
print(a) #zbcd
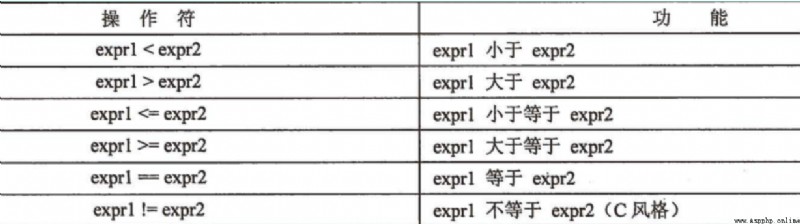
==, !=, <, <=, >, >= The behavior of these operators has been mentioned earlier .
Remember that the size of string comparison is in dictionary order .
a = 'abc'
b = 'ab'
print(a != b) #True
print(a < b) #False Compare in dictionary order
a = 'abc'
print('a' in a) #True
print('z' in a) #False
a = 'abcd'
print(a[1:2]) #b
print(a[:2]) #ab
print(a[1:]) #bcd
print(a[:]) #abcd
print(a[::2]) #ac
x = 1
print('x = %d' %x) # x = 1
x = 10
y = 20
a = 'x = %d y = %d' %x # Lack of parameter : Report errors TypeError: not enough arguments for format string
# Positive solution :
x = 10
y = 20
a = 'x = %d y = %d' %(x,y)
Recommend writing : Prefixed f
x = 10
y = 20
a = f'x = {
x},y={
y}'
print(a) #x = 10,y=20
The following formatting strings are supported :
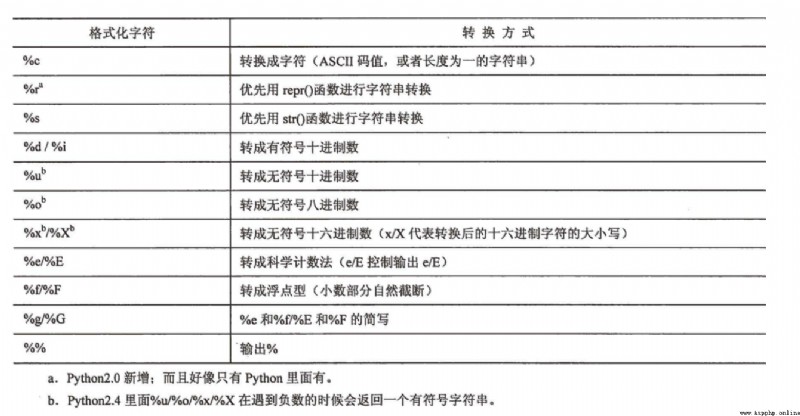
sometimes , We need to have \n Such characters are used as escape characters **. But sometimes we don't want to escape , Just the original **
\n As part of a string .
In the original string , Escape characters do not take effect
Example :QQ When sending messages , There is one “ Expression shortcut key ” The function of . This function is equivalent to “ Escape character ”.
When this function is enabled , Enter in the input box /se Will be replaced by an expression . For example, I send a directory to my colleagues /search/odin ( This originally meant linux A directory on )
In this case , We need to close “ Expression shortcut key ” function . about Python Come on , We can use the original string to solve this problem .
print(r'hello \n world') #hello \n world
a = 1
print(type(repr(a))) #<class 'str'> String type
print(str('hello')) # hello
print(repr('hello')) # 'hello'
To sum up , str The converted string is for people to see . and repr Converted String , It's for Python The interpreter looks at it .



Combine the strings in the sequence into one string . join function
a = ['aa','bb','cc']
b = ' '.join(a)
print(b) #aa bb cc
Divide the string into a list by space split function
a = 'aa bb cc'
b = a.split(' ')
print(b) #['aa', 'bb', 'cc']
Usually and join Functions together
a = 'aaa,bbb,ccc'
b = a.split(',') # With , Split into lists
print(b)
print(';'.join(b)) # Semicolon connection
print('hello'.join(b))
# Execution results :
['aaa', 'bbb', 'ccc']
aaa;bbb;ccc
aaahellobbbhelloccc
Determine the beginning and end of the string startswith function and endswith function
a = 'hello world'
print(a.startswith('h')) #True
print(a.startswith('hee')) #False
print(a.endswith('d')) #True
Remove spaces at the beginning and end of a string / tabs strip function
Blank character : Space , Line break ,tab
a = ' hello world '
print(a.strip()) #hello world
Remove the blank characters on the left :lstrip
Remove the white space on the right : rstrip
a =' hello \n'
print(f'[{
a.lstrip()}]') # For the sake of convenience , add []
print(f'[{
a.rstrip()}]')
print(f'[{
a.strip()}]')
# Execution results :
[hello
]
[ hello]
[hello]
Align left / Right alignment / Align in the middle ljust rjust center function
a = ' hello world'
print(a.ljust(30))
print(a.rjust(30))
print(a.center(30))
# Execution results :
hello world
hello world
hello world
Find substring find function
a = ' hello world'
print(a.find('hello')) #4
a = 'hello hello '
print(a.find('h')) #0
Returns the first occurrence of the subscript
and in almost ,in The return is a Boolean value
a = ' hello world'
print(a.find('hello')) #4
print('hello' in a) #True
Replace substring ( Remember that strings are immutable objects , Only new strings can be generated ). replace function
a= 'hello world'
print(a.replace('world','python')) #hello python
print(a) #hello world Strings are immutable objects , Only new strings can be generated
Determine whether the string is a letter / Numbers isalpha function and isdigit function
a = 'hello 1'
print(a.isalpha()) #False
a = '1234'
print(a.isdigit()) #True
Convert case lower and upper function
a = 'Hello world'
print(a.lower()) #hello world
print(a.upper()) #HELLO WORLD
Did you learn C Language students , May ask , Python Whether or not the string of ‘\0’ And so on ?
A string can only consist of characters , And immutable ; however The list can contain any type of object , More flexible to use .
a = [1,2,3,4]
a[0] = 100
print(a) #[100,2,3,4]
hold append As an element
a = [1,2,3]
a.append('a')
print(a) #[1,2,3,'a']
Be careful : Use append: Is to insert elements as a whole
a = [1,2]
a.append([3,4]) # What is inserted is a whole
print(a) #[1,2,[3,4]] 2 d list
print(len(a)) #3
a = [1,2,3]
del(a[0])
print(a) #[2,3]
a = [1,2,3]
a.remove(1)
print(a) #[2, 3]
# If the element does not exist , You're going to report a mistake
a.remove(4) # Report errors ValueError: list.remove(x): x not in list
== != To determine that all elements are equal , The list is equal ;
< <= > >= Two lists start with the first element Compare in turn , Until one side wins . Compare... In order
a = ['abc',12]
b = ['acb',123]
c = ['abc',11]
print(a<c) #False
print(b<c) #False
print(b >c and a > c) #True
a = [1,2,3]
b = [3,2,1]
print(a <b) #True In order ratio
a = [1,2,3]
b = ['a','b']
print(a<b) # Report errors :TypeError: '<' not supported between instances of 'int' and 'str'
Time complexity O(N)
a = [1,2,3,'a']
print('a' in a) #True
print(4 in a) #False
a and b All the same , Generate new objects
a = [1,'a']
b = [2,'b']
print(a+b) #[1, 'a', 2, 'b']
If you use append: Is to insert elements as a whole
a = [1,2]
a.append([3,4]) # What is inserted is a whole
print(a) #[1,2,[3,4]]
print(len(a)) #3
Use extend
Can be interpreted as += ( List does not support += Operator )
a = [1,2]
a.extend([3,4])
print(a) #[1,2,3,4]
print(len(a)) #4
a = [1,2]
print(a*3) #[1, 2, 1, 2, 1, 2]
If the subscript is large , Insert at the back
insert no return value :
a =[1,2,3]
print(a.insert(0,0)) #None
Example :
a=[1,2,3]
a.insert(0,0) # stay 0 Insert at subscript position 0
a.insert(100,100) # In subscript 100 Position insert 100
print(a) #[0, 1, 2, 3, 100]
a = [1,2,3,'ac']
a.reverse()
print(a) #['ac', 3, 2, 1]
You can also flip by slicing a[::-1] and reverse The difference between flipping :
Slice flipping does not modify the original object , Generate new objects , reverse Flip to modify the original object
This is the built-in member function of the list , and sorted Different
for example , Sort . When we talked about the sequence , There is a built-in function sorted, sorted A new ordered sequence is generated . The list itself has a member function sort, Is based on their own modifications , No new objects are generated .

a = [4,3,2,1]
sorted(a)# Built-in functions sorted
print(a)#[4, 3, 2, 1] a Don't change
a.sort()# Member functions sort
print(a)#[1, 2, 3, 4]
a.sort(reverse=True) # Flip
print(a) #[4,3,2,1]
About sort Method , By default, the derived algorithm of merge sort is used . The time complexity is O(N*log(N))
a = [4,3,2,1,2,4,2]
print(a.count(2)) # 3
print(a.count(5)) # 0
a = [4,3,2,1]
print(a.index(4)) #0
print(a.index(5)) # Report errors ValueError: 5 is not in list
Subscript delete , The default value is -1, Delete the last element
If the list is empty, it will pop up , You're going to report a mistake
a =[1]
print(a) #[1]
a.pop()
print(a) #[]
a.pop() # If the list is empty, it will pop up , Report errors :IndexError: pop from empty list
You can also delete the subscript : If the subscript is out of bounds, an error will be reported
a = [1,2,3,4]
a.pop(3) # Delete the subscript as 3 The elements of
print(a) #[1,2,3]
a.pop(6) # Report errors IndexError: pop index out of range
The list itself is a mutable object , So some methods are Modify your own , The method in this case does not return a value ,
This and the string operation must generate a new object , Is not the same .
Let's review... In the data structure Stack , This is a kind of Last in, first out Data structure of . You can easily use lists to simulate
a = [] # An empty list
a.append(1) #push operation Insert an element at the top of the stack
print(a[-1]) #top operation Get the stack top element
a.pop() #pop operation Pop up top element
Let's review... In the data structure queue , This is a kind of fifo Data structure of . You can also easily use list emulation
a = [] # An empty list
a.append(1) #push operation Insert elements at the end of the queue
print(a[0]) #top operation Get the team leader element
a.pop(0) #pop operation Pop team leader element
# Define a list object a.
a = [100, [1, 2]]
# be based on a, Created in three ways b, c, d
b = a
c = list(a)
d = a[:]
print(id(a), id(b), id(c), id(d)) #a and b Same as ,c,d Different b and a It's actually the same object . and c and d Are new list objects .
a[0] = 1
print(a, b, c, d) #a and b be affected c and d Unaffected
a[1][0] = 1000
print(a, b, c, d) # All four are affected
print(id(a[1]), id(c[1]), id(d[1])) # All the same
# Execution results
140541879626136 140541879626136 140541879655672 140541879655744
[1, [1, 2]] [1, [1, 2]] [100, [1, 2]] [100, [1, 2]]
[1, [1000, 2]] [1, [1000, 2]] [100, [1000, 2]] [100, [1000, 2]]
139973004362816 139973004362816 139973004362816
The result is a little complicated , Let's analyze it bit by bit
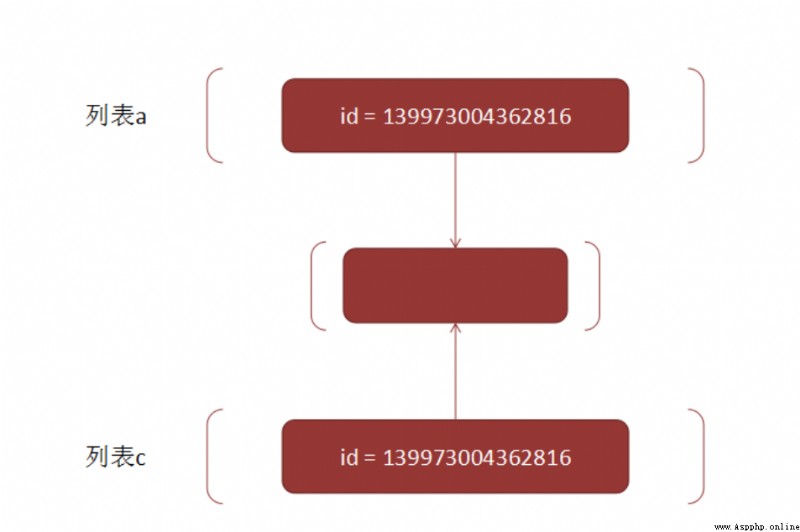
copy.deepcopy To complete Be careful : Deep copy Can only be used for mutable objects
Make a deep copy : Import required copy modular
import copy
a = [100, [1, 2]]
b = copy.deepcopy(a)
print(id(a[1]), id(b[1]) )
# Execution results
139818205071552 139818205117400
This time we see , a[1] and b[1] Is no longer an object .
import copy
a = (100, 'aaa')
b = copy.deepcopy(a)
print(id(a[0]), id(a[1]), id(b[0]), id(b[1]))
# Execution results
6783664 140700444542616 6783664 140700444542616
Think about why ?
The purpose of making a deep copy : Prevent one of the data from changing , Will affect the results of other data
Deep copy is to change one to another , But if it's an immutable object , No modification is allowed , There are no requirements ,
Because the contents of tuples cannot be modified , Deep copy is not necessary !
Many operations of tuples are consistent with lists . The only difference is that the contents of tuples are read-only .
Slicing operation : Same as list
Comparison operator , The rules are the same as the list
Connection operation (+), Repeat (*), Determine whether the element exists (in/not in) Are the same as the list .
** Because tuples are immutable , So it doesn't support append, extend, sort,[], And so on .** Yes, of course , Deep copy is not supported
Recall the awesome code we used to exchange the values of two elements .
x, y = y, x
Actually , x, y It's a tuple . adopt y, x This tuple creates a new tuple
x = 1
y = 2
x,y = y,x
print(type((x,y))) #<class 'tuple'>
a = ([1,2],[3,4])
a[0][0] = 100
print(a) #([100, 2], [3, 4])
Tuples : use
,Commas separate elements
a = (10) # Because it could be (10+2)*2 This expression , therefore a Is an integer , It's not a tuple
print(type(a)) #<class 'int'>
a = (10,2)
print(type(a)) #<class 'tuple'>
Be careful :
The tuple repetition operator is used here (*) The concept of .
a = (10+20,) *3 # There is no comma here ,a Namely 90
print(a) #(30, 30, 30)
print(type(a)) #<class 'tuple'> Tuples
“ immutable ” It's really necessary ? If we just use a list , Can you cope with all application scenarios ?
The answer is No . since Python The designer of provides the object of tuple , Then there must be some cases , Only tuples can do , But the list is not up to it .
reason 1: Using tuples when passing parameters to a function can avoid modifying the contents outside the function
You have a list , Now you need to call a API Do some processing . But you don't specifically confirm this API Whether it will mess up your list data . So it's much safer to pass a tuple at this time .
a = [1,2,3]
def func(input_list):
input_list[0] = 100
func(a)
print(a) #[100,2,3] The list can be modified
# If you use tuples :
a = (1,2,3)
def func(input_list):
input_list[0] = 100
func(a) # Report errors :TypeError: 'tuple' object does not support item assignment
print(a)
reason 2: Tuples are hashable , Tuples can be used as a dictionary key, And the list is variable , A list cannot be used as a dictionary key
The dictionary we're going to talk about , Is a key value pair structure . The key of the dictionary must be “ can hash object ” ( A dictionary is essentially a hash surface ). And one can hash The premise of an object is immutability . Therefore, tuples can be used as keys of dictionaries , But the list doesn't work .
a = (1,2,3)
b = {
a:100
}
print(b) # {(1, 2, 3): 100}
# If it's a list : Report errors
a = [1,2,3]
b = {
a:100 #TypeError: unhashable type: 'list'
}
print(b)
Python The dictionary is a mapping type of data . The data is Key value pair . Python Our dictionary is based on hash Table implementation .
Be careful : The types of keys and values of the dictionary , It doesn't need to be the same
Different key values use , Comma split
a = {
10:20,
'key':'value',
'a':True
}
print(a) #{10: 20, 'key': 'value', 'a': True}
Dictionary key Must be hashable , Immutable is changeable hash Necessary conditions
print(hash((10,20))) # Tuples can be hashed 3713074054217192181
print(hash([1,2])) # List cannot be hashed Report errors :TypeError: unhashable type: 'list'
a = {
'name':"Mango",'age':20}
print(a) #{'name': 'Mango', 'age': 20}
Use factory methods dict
use Tuples as parameters , Each parameter of a tuple is a list , There are two values in the list : One is the key. One is the value.
a = dict((['name',"Mango"],['age',20]))
print(a) #{'name': 'Mango', 'age': 20}
a = {
}.fromkeys(('name',"Ename"),"Mango")
print(a) #{'name': 'Mango', 'Ename': 'Mango'}
a = {
}.fromkeys(('name'),"Mango")
print(a) #{'n': 'Mango', 'a': 'Mango', 'm': 'Mango', 'e': 'Mango'}
Be careful : The types of keys and values of the dictionary , It doesn't need to be the same .
a = {
'name':"Mango",'age':20}
print(a['name']) #Mango
print(a['age']) #20
a = {
'name':"Mango",'age':20}
for item in a: #item Equivalent to each key
print(item,a[item]) # Print key and value
# Execution results :
name Mango
age 20
Be careful : Key value pairs in the dictionary , The order is uncertain ( memories hash The data structure of the table , There is no demand for key Orderly ).
Use [] You can add / Modify dictionary elements . -> If key non-existent , Will add ; If it already exists , Will modify .
a = {
} # An empty dictionary
a['name'] ="Mango"
print(a) #{'name': 'Mango'}
a['name'] = "Lemon"
print(a) #{'name': 'Lemon'}
a = {
'name':"Mango",'age':20}
del a['name']
print(a) #{'age': 20}
a = {
'name':"Mango",'age':20}
a.clear()
print(a) #{} An empty dictionary
a = {
'name':"Mango",'age':20}
b = a.pop('name')
print(a) # {'age': 20}
print(b) # Mango
Be careful : Dictionaries are also variable objects . But the key value is right key It can't be modified
** Decide on a key Is it in the dictionary ** ( The judgment is key, No value)
a = {
'name':"Mango",'age':20}
print('name' in a) #True
print('Mango' in a) #False
len: The number of key value pairs in the dictionary
a = {
'name':"Mango",'age':20}
print(len(a)) #2
hash: Determine whether an object can hash. If you can hash, Then return to hash After that hashcode. Otherwise, it will run wrong .
print(hash(())) #3527539 Tuples are immutable , Can hash
print(hash([])) #TypeError: unhashable type: 'list' List variable , Do not hash
Return a list , Contains all the of the dictionary key
a = {
'name':"Mango",'age':20}
print(a.keys()) #dict_keys(['name', 'age'])
Return a list , Contains all of the value
a = {
'name':"Mango",'age':20}
print(a.values()) #dict_values(['Mango', 20])
Return a list , Every element is a tuple , Contains key and value
a = {
'name':"Mango",'age':20}
print(a.items()) #dict_items([('name', 'Mango'), ('age', 20)])
A collection is a data structure implemented based on a dictionary . The set data structure realizes many intersection in mathematics , Combine , Difference set and other methods , It is very convenient to perform these operations .
Be careful !! Master assembly operation , For our follow-up exam questions, interview questions , Will be of great help .
Sets and lists are different , The order of the set has no effect
a = set([1,2,3])
b = set([3,2,1])
print(a == b) #True
print(a,b) #{1, 2, 3} {1, 2, 3}
a = set([1, 2, 3])
b = set([1, 2, 3, 4])
print(a & b) # intersect
print(a | b) # Union and collection
print(b - a) # Take the difference set
print(a ^ b) # Take the symmetric difference set ( Item in a In or in b in , But not both a and b in )
# Execution results
{
1, 2, 3}
{
1, 2, 3, 4}
{
4}
{
4}
a =set( [1, 1, 2, 2, 3, 3])
print(a) #{1,2,3}
a = [1,2,1,11,1,1,2]
b = set(a)
print(a) #[1, 2, 1, 11, 1, 1, 2]
print(b) #{1, 2, 11}