近期收到了電子工業出版社贈送的一本網絡安全書籍《python黑帽子》,書中一共24個實驗,今天復現第10個實驗(http流量圖片還原),我的測試環境是mbp電腦+conda開發環境。訪問一個http網站,就能抓取該網站的所有圖片,實際測試效果一般,不僅抓不全,而且抓的圖片存在大量重復,備注:有可能是我選的網站不好~
1、訪問一個有圖片的http網站,注意是80端口的http,不是https,然後開啟wireshark抓包,保存為pcap.pcap
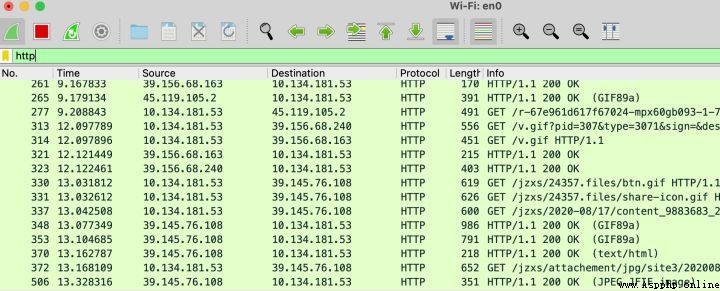
2、在mbp上啟動腳本,請忽略告警
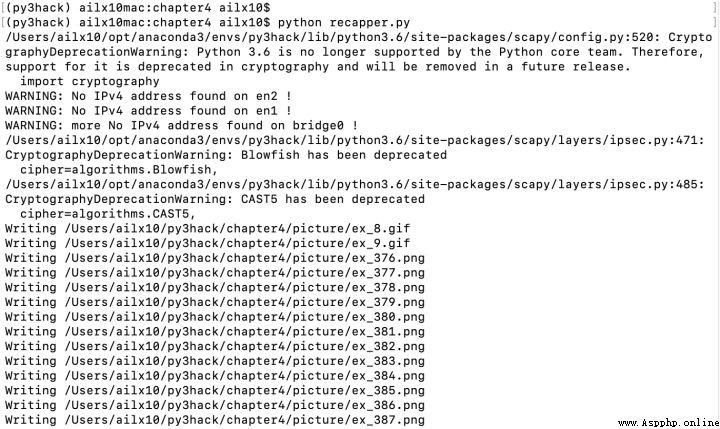
3、查看通過流量還原的圖片
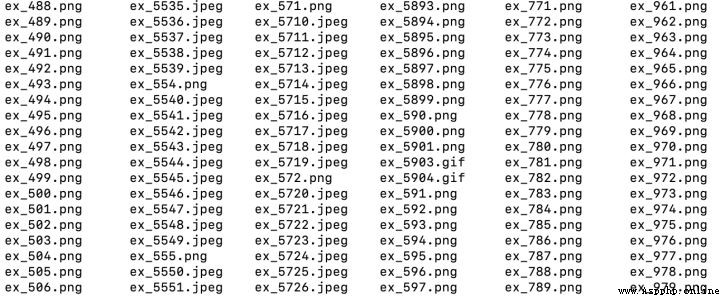
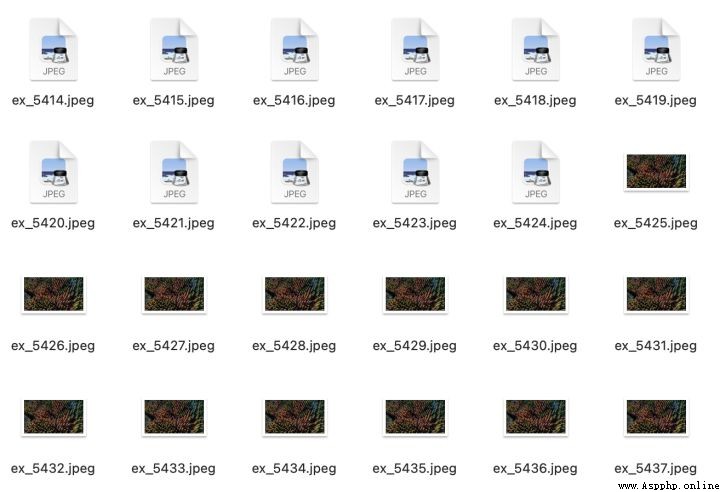
參考代碼:
# -*- coding: utf-8 -*-
# @Time : 2022/6/13 6:56 PM
# @Author : ailx10
# @File : recapper.py
from scapy.all import rdpcap
from scapy.layers.inet import TCP
import collections
import os
import re
import sys
import zlib
OUTDIR = "/Users/ailx10/py3hack/chapter4/picture"
PCAPS = "/Users/ailx10/py3hack/chapter4/download"
Response = collections.namedtuple("Response",["header","payload"])
def get_header(payload):
try:
header_raw = payload[:payload.index(b"\r\n\r\n")+2]
except ValueError:
sys.stdout.write("-")
sys.stdout.flush()
return None
header = dict(re.findall(r"(?P<name>.*?):(?P<value>.*?)\r\n",header_raw.decode()))
if "Content-Type" not in header:
return None
return header
def extract_content(Response,content_name="image"):
content,content_type = None,None
if content_name in Response.header["Content-Type"]:
content_type = Response.header["Content-Type"].split("/")[1]
content = Response.payload[Response.payload.index(b"\r\n\r\n")+4:]
if "Content-Encoding" in Response.header:
if Response.header["Content-Encoding"] == "gzip":
content = zlib.decompress(Response.header,zlib.MAX_WBITS | 32)
elif Response.header["Content-Encoding"] == "deflate":
content = zlib.decompress(Response.payload)
return content,content_type
class Recapper:
def __init__(self,fname):
pcap = rdpcap(fname)
self.sessions = pcap.sessions()
self.response = list()
def get_responses(self):
for session in self.sessions:
payload = b""
for packet in self.sessions[session]:
try:
if packet[TCP].dport == 80 or packet[TCP].sport == 80:
payload += bytes(packet[TCP].payload)
except IndexError:
sys.stdout.write("x")
sys.stdout.flush()
if payload:
header = get_header(payload)
if header is None:
continue
self.response.append(Response(header=header,payload=payload))
def write(self,content_name):
for i,response in enumerate(self.response):
content,content_type = extract_content(response,content_name)
if content and content_type:
fname = os.path.join(OUTDIR,f"ex_{i}.{content_type}")
print(f"Writing {fname}")
with open(fname,"wb") as f:
f.write(content)
if __name__ == "__main__":
pfile = os.path.join(PCAPS,"pcap.pcap")
recapper = Recapper(pfile)
recapper.get_responses()
recapper.write("image")