問題:(主要是第七個空真的不會)
漢語中結構助詞主要表示附加成分和中心語之間的結構關系,在書面語裡結構助詞習慣寫成三個字:“的”、“地”、“得”。這樣可以使書面語裡的結構關系更清楚。請統計 sefile104.txt
文件中的結構助詞的種類,並把每種結構助詞按個數從少到多排列,然後把個數輸出到屏幕,格式要求:寬度為 5 個字符,減號字符-填充,右對齊。注意 sefile104.txt 文件的編碼為 UTF-8(UTF-8 使用大寫),程序中的字符串全部使用雙引號
""表示。
請把編號(1)~(10)和對應下劃線刪除,填空完成程序中的語句,不能修改已有的代碼。
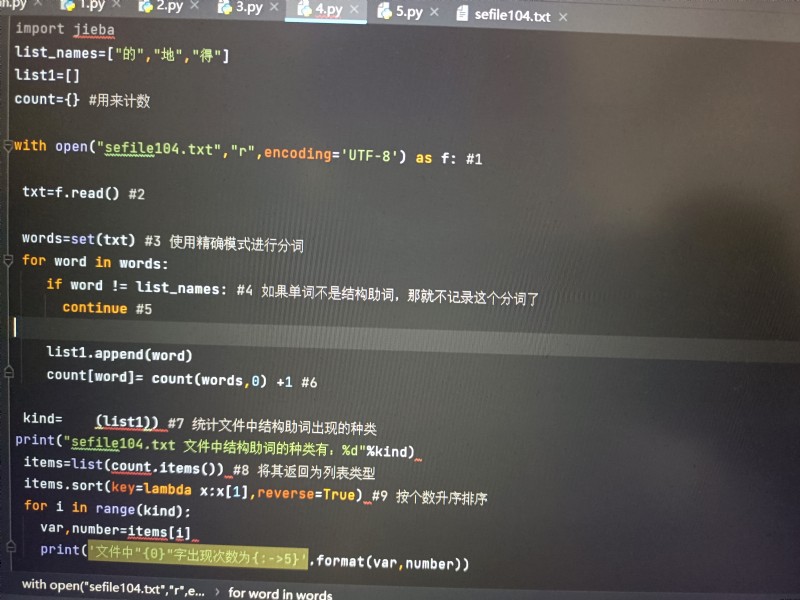
import jieba
list_names=["的","地","得"]
list1=[]
count={} #用來計數
with open("sefile104.txt","r",(1)) as f: #1
txt=f.(2) #2
words=(3)(txt) #3 使用精確模式進行分詞
for word in words:
if word (4) list_names: #4 如果單詞不是結構助詞,那就不記錄這個分詞了
(5) #5
list1.append(word)
count[word]= (6)+1 #6
kind=(7)_(list1)) #7 統計文件中結構助詞出現的種類
print("sefile104.txt 文件中結構助詞的種類有:%d"%kind)
items=(8)_(count.items()) #8 將其返回為列表類型
items.sort(key=lambda x:x[1],(9)__) #9 按個數升序排序
for i in range(kind):
var,number=items[i]
print('文件中"{0}"字出現次數為{ (10) }'.format(var,number)) #10