tunm是一種對標JSON的二進制協議, 支持JSON的所有類型的動態組合
基本支持的類型 "u8", "i8", "u16", "i16", "u32", "i32", "u64", "i64", "varint", "float", "string", "raw", "array", "map"
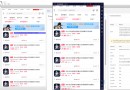
下圖是文本格式JSON與tunm的對比
在高性能的場景下, 或者需要流量傳輸比較敏感的地方, 通常會選擇二進制來代替文本協議來做為通訊的, 如RPC, REST, 游戲等情況。
相對於google protobuf, 它需要比較完善的預定義過程, 就比如客戶端版本1, 服務端版本2, 就有比較大的可能造成不兼容, 對需求經常變化的就會比較難與同步。
tunm相對於JSON, 若第一版是
{
"name": "tunm", "version": 1
}
此時第二版需要加入用戶的id, 就可以很方便的變成
{
"name": "tunm", "version": 2, "id": 1
}
而對客戶端1來說, 只是多一個id的字段, 不會有任何的破壞, 做到版本升級而無影響
數據協議分為三部分(協議名稱, 字符串索引區, 數據區(默認為數組))
如數據協議名為cmd_test_op, 數據為["tunm_proto", {"name": "tunm_proto", "tunm_proto": 1}]
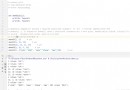
ByteBuffer具有組裝字節流的功能, 比如寫入字符串, 寫入int, 還有裡面存儲字符串索引區
class ByteBuffer(object):
def __init__(self):
# 字節緩沖區
self.buffer = bytearray([00]*1024)
# 寫入的位置索引號
self.wpos = 0
# 讀出的位置索引號
self.rpos = 0
# 大小端格式
self.endianness = "little"
# 索引的數組及快速查詢的字符串索引號
self.str_arr = []
self.str_map = {}
ByteBuffer源碼地址
@enum.unique
class TP_DATA_TYPE(IntEnum):
TYPE_NIL = 0,
TYPE_BOOL = 1,
TYPE_U8 = 2,
TYPE_I8 = 3,
TYPE_U16 = 4,
TYPE_I16 = 5,
TYPE_U32 = 6,
TYPE_I32 = 7,
TYPE_U64 = 8,
TYPE_I64 = 9,
TYPE_VARINT = 10,
TYPE_FLOAT = 11,
TYPE_DOUBLE = 12,
TYPE_STR = 13,
TYPE_STR_IDX = 14,
TYPE_RAW = 15,
TYPE_ARR = 16,
TYPE_MAP = 17,
@staticmethod
def encode_varint(buffer: ByteBuffer, value):
'''
如果原數值是正數則將原數值變成value*2
如果原數值是負數則將原數值變成-(value + 1) * 2 + 1
相當於0->0, -1->1, 1->2,-2->3,2->4來做處理
因為小數值是常用的, 所以保證小數值及負數的小數值盡可能的占少位
'''
if type(value) == bool:
value = 1 if value else 0
real = value * 2
if value < 0:
real = -(value + 1) * 2 + 1
for _i in range(12):
# 每個字節的最高位來表示有沒有下一位, 若最高位為0, 則已完畢
b = real & 0x7F
real >>= 7
if real > 0:
buffer.write_u8(b | 0x80)
else:
buffer.write_u8(b)
break
@staticmethod
def encode_str_idx(buffer: ByteBuffer, value):
'''
寫入字符串索引值, 在數值區裡的所有字符串默認會被寫成索引值
如果重復的字符串則會返回相同的索引值(varint)
'''
idx = buffer.add_str(value)
TPPacker.encode_type(buffer, TP_DATA_TYPE.TYPE_STR_IDX)
TPPacker.encode_varint(buffer, idx)
@staticmethod
def encode_field(buffer: ByteBuffer, value, pattern=None):
'''
先寫入類型的值(u8), 則根據類型寫入類型對應的的數據
'''
if not pattern:
pattern = TPPacker.get_type_by_ref(value)
if pattern == TP_DATA_TYPE.TYPE_NIL:
return None
elif pattern == TP_DATA_TYPE.TYPE_BOOL:
TPPacker.encode_type(buffer, pattern)
TPPacker.encode_bool(buffer, value)
elif pattern >= TP_DATA_TYPE.TYPE_U8 and pattern <= TP_DATA_TYPE.TYPE_I8:
TPPacker.encode_type(buffer, pattern)
TPPacker.encode_number(buffer, value, pattern)
elif pattern >= TP_DATA_TYPE.TYPE_U16 and pattern <= TP_DATA_TYPE.TYPE_I64:
TPPacker.encode_type(buffer, TP_DATA_TYPE.TYPE_VARINT)
TPPacker.encode_varint(buffer, value)
elif pattern == TP_DATA_TYPE.TYPE_FLOAT:
TPPacker.encode_type(buffer, pattern)
TPPacker.encode_number(buffer, value, pattern)
elif pattern == TP_DATA_TYPE.TYPE_DOUBLE:
TPPacker.encode_type(buffer, pattern)
TPPacker.encode_number(buffer, value, pattern)
elif pattern == TP_DATA_TYPE.TYPE_STR:
TPPacker.encode_str_idx(buffer, value)
elif pattern == TP_DATA_TYPE.TYPE_RAW:
TPPacker.encode_type(buffer, pattern)
TPPacker.encode_str_raw(buffer, value)
elif pattern == TP_DATA_TYPE.TYPE_ARR:
TPPacker.encode_type(buffer, pattern)
TPPacker.encode_arr(buffer, value)
elif pattern == TP_DATA_TYPE.TYPE_MAP:
TPPacker.encode_type(buffer, pattern)
TPPacker.encode_map(buffer, value)
else:
raise Exception("unknow type")
@staticmethod
def encode_arr(buffer: ByteBuffer, value):
'''
寫入數組的長度, 再寫入各各元素的值
'''
TPPacker.encode_varint(buffer, len(value))
for v in value:
TPPacker.encode_field(buffer, v)
@staticmethod
def encode_map(buffer: ByteBuffer, value):
'''
寫入map的長度, 再分別寫入map各元素的key, value值
'''
TPPacker.encode_varint(buffer, len(value))
for k in value:
TPPacker.encode_field(buffer, k)
TPPacker.encode_field(buffer, value[k])
@staticmethod
def encode_proto(buffer: ByteBuffer, name, infos):
'''
寫入協議名稱, 然後寫入字符串索引區(即字符串數組), 然後再寫入協議的詳細數據
'''
sub_buffer = ByteBuffer()
TPPacker.encode_field(sub_buffer, infos)
TPPacker.encode_str_raw(buffer, name, TP_DATA_TYPE.TYPE_STR)
TPPacker.encode_varint(buffer, len(sub_buffer.str_arr))
for val in sub_buffer.str_arr:
TPPacker.encode_str_raw(buffer, val, TP_DATA_TYPE.TYPE_STR)
buffer.write_bytes(sub_buffer.all_bytes())
tunm源碼地址
協議地址https://github.com/tickbh/TunmProto