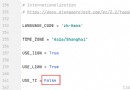
tunm It is a kind of benchmarking JSON Binary protocol , Support JSON All types of dynamic combinations of
Types of basic support "u8", "i8", "u16", "i16", "u32", "i32", "u64", "i64", "varint", "float", "string", "raw", "array", "map"
The following figure shows the text format JSON And tunm Comparison of
In high-performance scenarios , Or where traffic transmission is sensitive , Usually, binary is chosen to replace text protocol for communication , Such as RPC, REST, Games, etc .
be relative to google protobuf, It requires a well-defined process , For example, the client version 1, Server version 2, There is a greater possibility of incompatibility , It will be difficult to keep pace with those whose requirements change frequently .
tunm be relative to JSON, If the first edition is
{
"name": "tunm", "version": 1
}
At this point, the second edition needs to add the user's id, Can be very convenient to become
{
"name": "tunm", "version": 2, "id": 1
}
On the client side 1 Come on , Just one more id Field of , There will be no damage , Upgrade the version without any impact
The data protocol is divided into three parts ( Name of agreement , String index area , Data area ( The default is array ))
For example, the data protocol is named cmd_test_op, The data is ["tunm_proto", {"name": "tunm_proto", "tunm_proto": 1}]
ByteBuffer It has the function of assembling byte stream , For example, write a string , write in int, There is also a string index area inside
class ByteBuffer(object):
def __init__(self):
# Byte buffer
self.buffer = bytearray([00]*1024)
# The index number of the written position
self.wpos = 0
# Read the position index number
self.rpos = 0
# Size end format
self.endianness = "little"
# Index array and string index number for quick query
self.str_arr = []
self.str_map = {}
ByteBuffer Source code address
@enum.unique
class TP_DATA_TYPE(IntEnum):
TYPE_NIL = 0,
TYPE_BOOL = 1,
TYPE_U8 = 2,
TYPE_I8 = 3,
TYPE_U16 = 4,
TYPE_I16 = 5,
TYPE_U32 = 6,
TYPE_I32 = 7,
TYPE_U64 = 8,
TYPE_I64 = 9,
TYPE_VARINT = 10,
TYPE_FLOAT = 11,
TYPE_DOUBLE = 12,
TYPE_STR = 13,
TYPE_STR_IDX = 14,
TYPE_RAW = 15,
TYPE_ARR = 16,
TYPE_MAP = 17,
@staticmethod
def encode_varint(buffer: ByteBuffer, value):
'''
If the original value is a positive number, the original value is changed to value*2
If the original value is negative, the original value is changed to -(value + 1) * 2 + 1
amount to 0->0, -1->1, 1->2,-2->3,2->4 To deal with
Because small numbers are commonly used , Therefore, ensure that small numbers and negative small numbers occupy as few bits as possible
'''
if type(value) == bool:
value = 1 if value else 0
real = value * 2
if value < 0:
real = -(value + 1) * 2 + 1
for _i in range(12):
# The highest bit of each byte indicates whether there is a next bit , If the highest order is 0, Is completed
b = real & 0x7F
real >>= 7
if real > 0:
buffer.write_u8(b | 0x80)
else:
buffer.write_u8(b)
break
@staticmethod
def encode_str_idx(buffer: ByteBuffer, value):
'''
Write string index value , All strings in the value field will be written as index values by default
If the string is repeated, the same index value will be returned (varint)
'''
idx = buffer.add_str(value)
TPPacker.encode_type(buffer, TP_DATA_TYPE.TYPE_STR_IDX)
TPPacker.encode_varint(buffer, idx)
@staticmethod
def encode_field(buffer: ByteBuffer, value, pattern=None):
'''
Write the value of the type first (u8), Write the data corresponding to the type according to the type
'''
if not pattern:
pattern = TPPacker.get_type_by_ref(value)
if pattern == TP_DATA_TYPE.TYPE_NIL:
return None
elif pattern == TP_DATA_TYPE.TYPE_BOOL:
TPPacker.encode_type(buffer, pattern)
TPPacker.encode_bool(buffer, value)
elif pattern >= TP_DATA_TYPE.TYPE_U8 and pattern <= TP_DATA_TYPE.TYPE_I8:
TPPacker.encode_type(buffer, pattern)
TPPacker.encode_number(buffer, value, pattern)
elif pattern >= TP_DATA_TYPE.TYPE_U16 and pattern <= TP_DATA_TYPE.TYPE_I64:
TPPacker.encode_type(buffer, TP_DATA_TYPE.TYPE_VARINT)
TPPacker.encode_varint(buffer, value)
elif pattern == TP_DATA_TYPE.TYPE_FLOAT:
TPPacker.encode_type(buffer, pattern)
TPPacker.encode_number(buffer, value, pattern)
elif pattern == TP_DATA_TYPE.TYPE_DOUBLE:
TPPacker.encode_type(buffer, pattern)
TPPacker.encode_number(buffer, value, pattern)
elif pattern == TP_DATA_TYPE.TYPE_STR:
TPPacker.encode_str_idx(buffer, value)
elif pattern == TP_DATA_TYPE.TYPE_RAW:
TPPacker.encode_type(buffer, pattern)
TPPacker.encode_str_raw(buffer, value)
elif pattern == TP_DATA_TYPE.TYPE_ARR:
TPPacker.encode_type(buffer, pattern)
TPPacker.encode_arr(buffer, value)
elif pattern == TP_DATA_TYPE.TYPE_MAP:
TPPacker.encode_type(buffer, pattern)
TPPacker.encode_map(buffer, value)
else:
raise Exception("unknow type")
@staticmethod
def encode_arr(buffer: ByteBuffer, value):
'''
Write the length of the array , Then write the values of each element
'''
TPPacker.encode_varint(buffer, len(value))
for v in value:
TPPacker.encode_field(buffer, v)
@staticmethod
def encode_map(buffer: ByteBuffer, value):
'''
write in map The length of , Then write... Separately map Of each element key, value value
'''
TPPacker.encode_varint(buffer, len(value))
for k in value:
TPPacker.encode_field(buffer, k)
TPPacker.encode_field(buffer, value[k])
@staticmethod
def encode_proto(buffer: ByteBuffer, name, infos):
'''
Write the protocol name , Then write the string index area ( It's an array of strings ), Then write the detailed data of the protocol
'''
sub_buffer = ByteBuffer()
TPPacker.encode_field(sub_buffer, infos)
TPPacker.encode_str_raw(buffer, name, TP_DATA_TYPE.TYPE_STR)
TPPacker.encode_varint(buffer, len(sub_buffer.str_arr))
for val in sub_buffer.str_arr:
TPPacker.encode_str_raw(buffer, val, TP_DATA_TYPE.TYPE_STR)
buffer.write_bytes(sub_buffer.all_bytes())
tunm Source code address
Protocol address https://github.com/tickbh/TunmProto