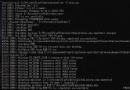
Sometimes used pandas Of read_csv There is no exception when opening the file , For example, below 
But once you use column names to process data , A column name error will appear , But there's no problem with it . For example, as shown below 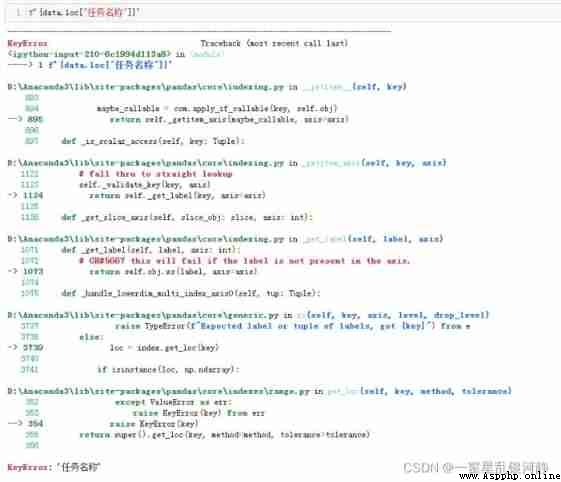
At this time, it is necessary to consider whether there is any format or character that is not displayed , So we print out the column names 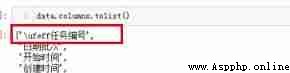
You can see that there is \ufeff The characters of . Open the file through Notepad , Found file format is UTF-8 with BOM.
Source: Baidu Encyclopedia :
UTF-8: Take byte as encoding unit , Its byte order is the same in all systems , There is no problem with byte order , And so it doesn't really need BOM(“ByteOrder Mark”). however UTF-8 with BOM namely utf-8-sig Need to provide BOM
Byte order mark ( English :byte-order mark,BOM) It's at the code point U+FEFF The name of the Unicode character .
UTF-8 There is no byte order issue ,UTF-8 The encoded byte order mark is used to indicate that it is UTF-8 The file of , It's only used to mark one UTF-8 The file of , It's not about byte order . Many windows programs ( Including Notepad ) Will add a byte order mark to UTF-8 file . However , In the class Unix System ( Use a lot of text files , For file formats , For interprocess communication ) in , This approach is not recommended . Because it gets in the way of the interpreter script at the beginning of Shebang And so on . So it will also affect the ability to recognize his language .
The byte order is marked in UTF-8 Is represented as a sequence EF BB BF
Found the problem , That's it
Only when reading the file . Use utf-8-sig That's all right. .
pd.read_csv(data,encoding='utf-8-sig')