WeChat official account : Chuangxiang diary
Send keywords : Prediction of illness
Get training set file d_ train.csv、f_train.csv+ Test set d_ test.csv、f_test.csv And two prediction model files (Python)
One 、 subject
● The purpose of this experiment is to predict the indicators indicating the degree of illness of the population through the clinical data and physical examination indicators of a certain patient .
● Need to design efficiently , And a highly interpretive algorithm to accurately predict disease indicators .
● All programming .
Two 、 data - Mission I
● The experimental task data is the training set file d_train.csv, Test set d_test.csv
● The first line of each file is the field name , Then each line represents an individual .
● The training set file contains 42 A field , Include numerical type 、 Character 、 Date type and so on , Some fields are missing from some people , The first column is the individual id Number .
● The last column of the training set file is the label column , It is necessary to predict the target value .
● The label column of the test set file is empty , The forecast results need to be uploaded to Kaggle.
● Submit instructions : To submit a d_model.py That is, the predicted model file .
Two 、 data - Mission II
● The experimental task data is a training set file f_train.csv, Test set file f_test.csv
● The first line of each file is the field name , Then each line represents an individual , Some field names have been desensitized .
● The training set file contains 85 A field , Some fields are missing from some people , The first column is the individual id Number .
● The last column of the training set file is the label column , Both need to predict whether the class of disease .
● The label column of the test set file is empty , The forecast results need to be uploaded to Kaggle.
● Submit instructions : To submit a f_ model.py That is, the predicted model file .
3、 ... and 、 Evaluation index task I
● For the task I, It is necessary to submit the index prediction results for each person , In decimal form , Keep three decimal places . This result will be compared with the result actually detected by the individual , Taking the mean square error as the evaluation index , The smaller the result, the better , The mean square error is calculated as follows :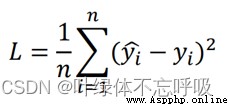
● among n Is the total number of people , yi^ For the predicted second i Individual indicator value , yi For the first time i Personal actual index test value .
3、 ... and 、 Evaluation index task II
● For the task II, It is necessary to submit the prediction results of whether everyone is ill , Express the category as an integer , The value is 0 perhaps 1. This result will be compared with whether the individual actually detects the disease , With F1 For the evaluation index , The bigger the result, the better ,F1 The calculation formula is as follows :
● among P For accuracy , The calculation formula is as follows :
●R For the recall rate , The calculation formula is as follows :
The number of positive samples is defined as the number of 1 The number of samples .