Catalog
1. Background and significance of the topic 5
2. Analysis of current research situation 5
3. The algorithm of this paper 6
3.1 Description of algorithm 7
3.2 Algorithm formula 、 A word description 8
3.3 Algorithm details 12
4. experimental result 14
5. Discuss and analyze 16
5.1 Results display and comparison 16
5.2 analysis 16
6. Conclusion 19
7. Learning experience and suggestions 19
8. Contribution of team members 19
Chinese abstract
With the rapid growth of network information, it is difficult for people to search for information , The emergence of search engine has solved this problem in time , And in search engines , One of its core parts is the Chinese word segmentation algorithm , The efficiency of Chinese word segmentation algorithm affects the speed of retrieving entries to a certain extent . In this era of rapid development of Internet Information , Efficiency is undoubtedly the core element of competition in the market .
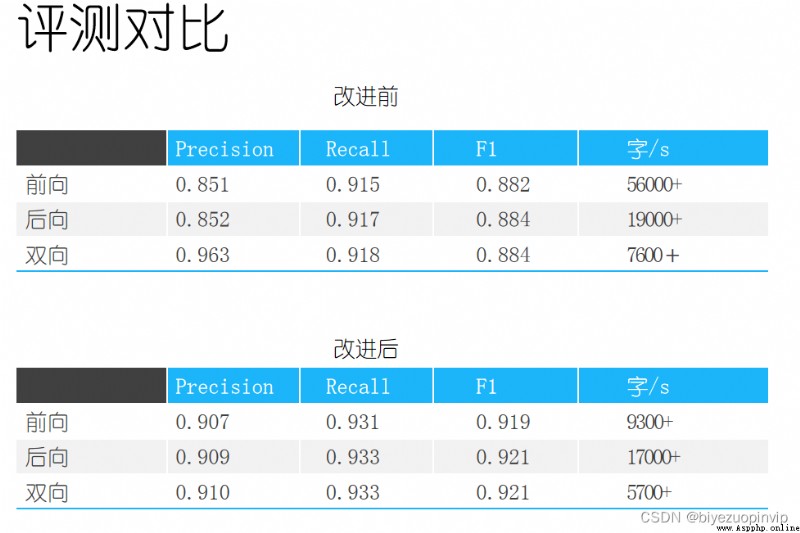
This semester , We learned many Chinese word segmentation algorithms in naturallanguageprocessing class , In this big assignment , We chose three of these algorithms : Three algorithms for maximum matching – positive 、 reverse 、 two-way ; Based on statistics Uni-Gram Model ; Hidden Markov (HMM) Statistical models . First, we will implement the code of these three models according to what we have learned in class , stay PKU The correct word segmentation level set of a dictionary 、 Test set and training set , For the recall rate of their three algorithms 、F1 score、 The accuracy rate is compared with these three indicators , Finally, print out the results , Choose an optimal algorithm as the experimental results .
key word : Chinese word segmentation algorithm 、 Compare 、 Accuracy rate 、 Recall rate 、F1 score
Abstract
With the rapid growth of network information, people have some difficulties in searching information. The emergence of search engine has solved this problem in time. In search engine, one of the most core parts is Chinese word segmentation algorithm. The efficiency of Chinese word segmentation algorithm affects the speed of retrieval entries to a certain extent. In this era of rapid development of Internet information, efficiency is undoubtedly the core element of competition in shopping malls.
This semester, we learned a variety of Chinese word segmentation algorithms in natural language processing class. In this assignment, we selected three of them: three algorithms of maximum matching: forward, backward and bidirectional; uni gram model based on statistics; hidden Markov model (HMM). First of all, we will implement the codes of the three models according to the content learned in class. On the basis of the correct word segmentation level set, test set and training set of PKU dictionary, we will compare the recall rate, F1 score and accuracy rate of the three algorithms. Finally, we will print out the results and select an optimal algorithm as the experimental result.
Key word:Chinese word segmentation algorithm, Comparison, Accuracy, Recall rate, F1 score
1. Background and significance of the topic
There is Chinese word segmentation technology , Because Chinese has its particularity in basic grammar , Specifically, :
1. Compared with Latin languages represented by English , English uses spaces as natural separators , And Chinese is inherited from the tradition of ancient Chinese , There is no separation between words . In ancient Chinese, in addition to continuous words and names of people and places , A word is usually a single Chinese character , So there was no need for word segmentation at that time . However, in modern Chinese, double word or multi word words are in the majority , A word is no longer equivalent to a word .
2. In Chinese ,“ word ” and “ phrase ” The border is blurred
Although the basic expression unit of modern Chinese is “ word ”, And most of them are double word or multi word words , But because of people's different levels of understanding , The boundaries of words and phrases are difficult to distinguish .
for example :“ Punishment for spitting everywhere ”,“ Spitters everywhere ” Is itself a word or a phrase , Different people have different standards , alike “ The sea ”“ Distillery ” wait , Even the same person can make different judgments , If Chinese really needs word segmentation , There is bound to be chaos , It's very difficult. .
The method of Chinese word segmentation is not limited to Chinese application , It is also applied to English processing , Like handwriting recognition , The space between words is not very clear , Chinese word segmentation can help identify the boundaries of English words .
With the rapid growth of network information, it is difficult for people to search for information , How much impact does Chinese word segmentation have on search engines ? For search engines , The most important thing is not to find all the results , Because it doesn't make much sense to find all the results in billions of web pages , No one can finish it , The most important thing is to put the most relevant results at the top , This is also called correlation ranking . The accuracy of Chinese word segmentation , It often directly affects the relevance ranking of search results .