微信公眾號:創享日記
發送關鍵詞:病情預測
獲取訓練集文件d_ train.csv、f_train.csv+測試集d_ test.csv、f_test.csv以及兩個預測模型文件(Python)
一、題目
●本實驗旨在通過某種患病病人的臨床數據和體檢指標來預測人群指示病情程度的指標。
●需要設計高效,且解釋性強的算法來精准預測病情指標。
●全部編程實現。
二、數據-任務I
●實驗任務數據為訓練集文件d_train.csv, 測試集d_test.csv
●每個文件第一行是字段名,之後每一行代表一個個體。
●訓練集文件共包含42個字段,包含數值型、字符型、日期型等眾多數據類型,部分字段內容在部分人群中有缺失,其中第一列為個體id號。
●訓練集文件的最後一列為標簽列, 既需要預測的目標值。
●測試集文件的標簽列為空,需要將預測結果上傳至Kaggle。
●提交說明:提交一個d_model.py即預測的模型文件。
二、數據-任務II
●實驗任務丌數據為訓練集文件f_train.csv, 測試集文件f_test.csv
●每個文件第一行是字段名,之後每一行代表一個個體,部分字段名已做脫敏處理。
●訓練集文件共包含85個字段,部分字段內容在部分人群中有缺失,其中第一列為個體id號。
●訓練集文件的最後一列為標簽列, 既需要預測的是否患病的類標。
●測試集文件的標簽列為空,需要將預測結果上傳至Kaggle。
●提交說明:提交一個f_ model.py即預測的模型文件。
三、評估指標一任務I
●對於任務I,需要提交對每個人的指標預測結果,以小數形式表示,保留小數點後三位。該結果將與個體實際檢測到的結果進行對比,以均方誤差為評價指標,結果越小越好,均方誤差計算公式如下: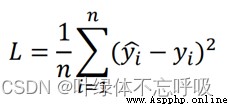
●其中n為總人數, yi^為預測的第i個人的指標值, yi為第i個人的實際指標檢測值。
三、評估指標一任務II
●對於任務II,需要提交對每個人是否患病的預測結果,以整數形式表示類別,取值為0或者1。該結果將與個體實際檢測到的是否患病情況進行對比,以F1為評價指標,結果越大越好,F1計算公式如下:
●其中P為准確率,計算公式如下:
●R為召回率,計算公式如下:
其中正樣本數定義為數值為1的樣本數。