Translating pictures into words is generally called optical character recognition (Optical Character Recognition,OCR). Can achieve OCR There are not many underlying Libraries , At present, many libraries use several common bottom layers OCR library , Or customize it .
easyocr Is based on torch Deep learning module
easyocr Occurs after the installation is invoked. opencv Version incompatibility problem , So give it up .
advantage : The deployment of fast , Lightweight , Available offline , free
shortcoming : The recognition rate of the built-in Chinese library is low , You need to build your own data for training
Tesseract It's a OCR library , At present by Google sponsorship (Google It is also a family with OCR And machine learning technology ).Tesseract Is currently recognized as the best 、 The most accurate open source OCR System .
In addition to high accuracy ,Tesseract It also has high flexibility . It can recognize any font through training ( As long as the style of these fonts remains the same ), You can also identify any Unicode character .
python Recognize the number on the picture , Use pytesseract Library extracts text from images , And identify The engine uses tesseract-ocr.
pytesseract yes python Wrappers , It provides for executable files pythonic API.
pip install pillow
pip install pytesseract
Download address of latest version : https://github.com/UB-Mannheim/tesseract/wiki 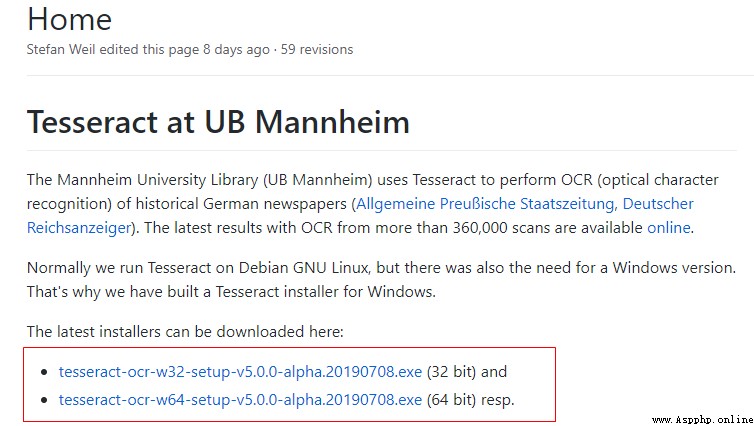
Or more tesseract Download address :https://digi.bib.uni-mannheim.de/tesseract/
After the installation , need take Tesseract Add to system variable in .
environment variable : My computer -> attribute -> Advanced system setup -> environment variable -> System variables , stay path Add The installation path .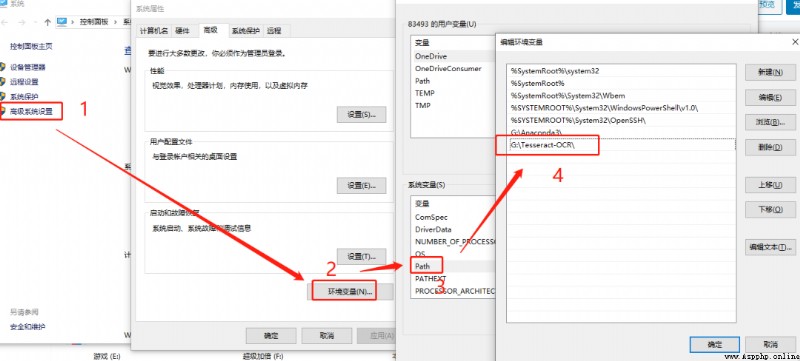
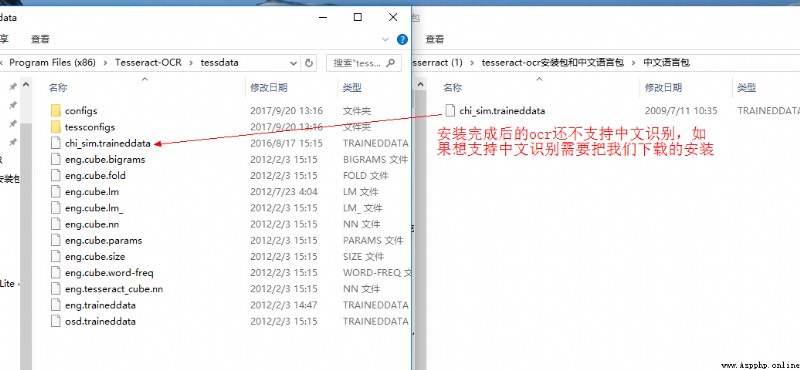
And the trained model file chi_sim.traineddata Put it in this directory , This completes the installation .
In command line WIN+R Input cmd : Input tesseract -v , Version information appears , Then the configuration is successful .

tesseract-ocr Chinese recognition is not supported by default . Support Chinese recognition .png
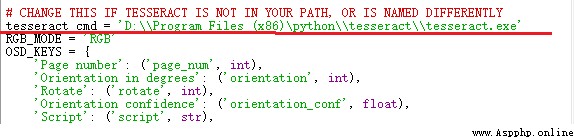
In the self installed pytesseract In bag , find pytesseract.py file 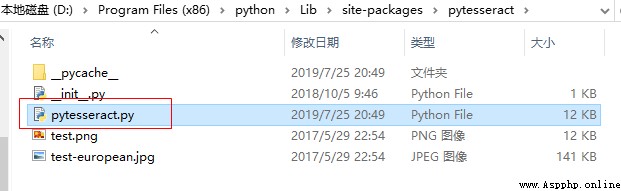
open pytesseract.py file , modify tesseract_cmd Value :tesseract.exe Installation path for .
To avoid other mistakes , Use double backslashes , Or slashes
import pytesseract
from PIL import Image
if __name__ == '__main__':
text = pytesseract.image_to_string(Image.open("D:\\test.png"),lang="eng")
# If you want to try Tesseract Identifying Chinese , Just put the... In the code eng Change it to chi_sim that will do
print(text)
The test image :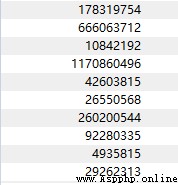
Output results :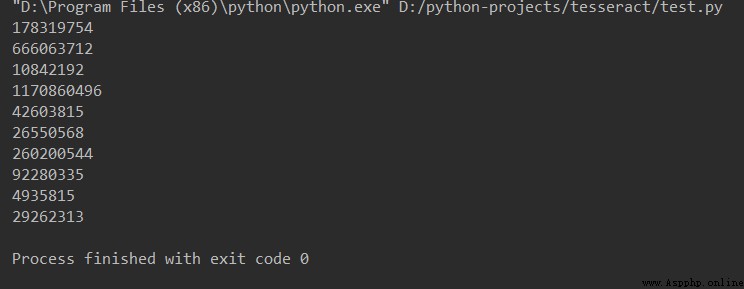
use Tesseract Can recognize the text with standard format , It has the following characteristics :



Then there is a slightly slanted text picture th.jpg, The identification is as follows :

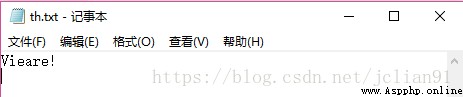
You can see that the recognition is not as good as the standard font , But it can also recognize most of the letters in the picture .
The last is to recognize simplified Chinese , You need to install the simplified Chinese language pack in advance , Download at :https://github.com/tesseract-ocr/tessdata/find/master/chi_sim.traineddata , Let's talk about it again chi_sim.traineddata Put it in C:\Program Files (x86)\Tesseract-OCR\tessdata Under the table of contents . We use pictures timg.jpg For example :

Enter the command :
tesseract E://figures/other/timg.jpg E://figures/other/timg.txt -l chi_sim
The results are as follows :

Only one wrong word was recognized , The recognition rate is good .
Add one last sentence ,Tesseract The recognition effect of color pictures is not as good as that of black-and-white pictures .
pytesseract yes Tesseract About Python The interface of , have access to pip install pytesseract install . After the installation , Can Use Python call Tesseract 了 , however , You need one more Python Image processing module , Can install pillow.
Enter the following code , The same as the above can be achieved Tesseract The same effect as command :
import pytesseract
from PIL import Image
pytesseract.pytesseract.tesseract_cmd = 'C://Program Files (x86)/Tesseract-OCR/tesseract.exe'
text = pytesseract.image_to_string(Image.open('E://figures/other/poems.jpg'))
print(text)
The operation results are as follows :

How to use the two tools and their comparative effects .
pip install cnocr
notice Successfully installed xxx The installation is successful .
If you only want to recognize the Chinese in the picture , that cnocr It's a good choice , You just need to install cnocr Bag can .
But if you want to try other languages OCR distinguish ,Tesseract It's a better choice .
cnocr It is mainly aimed at printed words and pictures with simple typesetting , As shown in the screenshot , Scanning copy, etc . At present, the built-in text detection and branch module can not handle complex text typesetting and positioning .
Although it provides single line recognition function and multi line recognition function respectively , But under my actual measurement , The effect of single line recognition function is very bad , Or the requirements are very harsh , Basically, I can't even recognize the words in the screenshot .
But the multiline recognition function is good , The code identified by using this function is as follows :
from cnocr import CnOcr
ocr = CnOcr()
res = ocr.ocr('test.png')
print("Predicted Chars:", res)
Used to identify the text in this picture :
The effect is as follows :
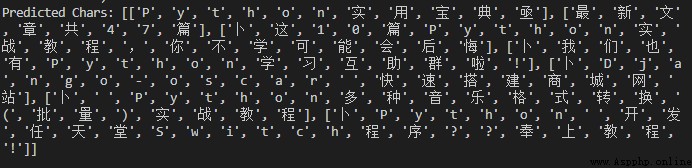
If not very picky , This effect is already very good .
advantage : Easy to use , Powerful
shortcoming : There is a charge for heavy use
Baidu is my own call API The way , Here are my steps :
Register baidu account , establish OCR Application can refer to other tutorials .
Use after purchase python Calling method
Mode one : adopt urllib Call directly , Replace your own api_key and secret_key that will do
# coding=utf-8
import sys
import json
import base64
# Guarantee compatibility python2 as well as python3
IS_PY3 = sys.version_info.major == 3
if IS_PY3:
from urllib.request import urlopen
from urllib.request import Request
from urllib.error import URLError
from urllib.parse import urlencode
from urllib.parse import quote_plus
else:
import urllib2
from urllib import quote_plus
from urllib2 import urlopen
from urllib2 import Request
from urllib2 import URLError
from urllib import urlencode
# prevent https Certificate verification is incorrect
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
API_KEY = 'YsZKG1wha34PlDOPYaIrIIKO'
SECRET_KEY = 'HPRZtdOHrdnnETVsZM2Nx7vbDkMfxrkD'
OCR_URL = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic"
""" TOKEN start """
TOKEN_URL = 'https://aip.baidubce.com/oauth/2.0/token'
""" obtain token """
def fetch_token():
params = {
'grant_type': 'client_credentials',
'client_id': API_KEY,
'client_secret': SECRET_KEY}
post_data = urlencode(params)
if (IS_PY3):
post_data = post_data.encode('utf-8')
req = Request(TOKEN_URL, post_data)
try:
f = urlopen(req, timeout=5)
result_str = f.read()
except URLError as err:
print(err)
if (IS_PY3):
result_str = result_str.decode()
result = json.loads(result_str)
if ('access_token' in result.keys() and 'scope' in result.keys()):
if not 'brain_all_scope' in result['scope'].split(' '):
print ('please ensure has check the ability')
exit()
return result['access_token']
else:
print ('please overwrite the correct API_KEY and SECRET_KEY')
exit()
""" Read the file """
def read_file(image_path):
f = None
try:
f = open(image_path, 'rb')
return f.read()
except:
print('read image file fail')
return None
finally:
if f:
f.close()
""" Call remote service """
def request(url, data):
req = Request(url, data.encode('utf-8'))
has_error = False
try:
f = urlopen(req)
result_str = f.read()
if (IS_PY3):
result_str = result_str.decode()
return result_str
except URLError as err:
print(err)
if __name__ == '__main__':
# obtain access token
token = fetch_token()
# Splicing universal character recognition with high precision url
image_url = OCR_URL + "?access_token=" + token
text = ""
# Read the test picture
file_content = read_file('test.jpg')
# Call the character recognition service
result = request(image_url, urlencode({
'image': base64.b64encode(file_content)}))
# Parsing returns results
result_json = json.loads(result)
print(result_json)
for words_result in result_json["words_result"]:
text = text + words_result["words"]
# Print text
print(text)
Mode two : adopt HTTP-SDK Module
from aip import AipOcr
APP_ID = '25**9878'
API_KEY = 'VGT8y***EBf2O8xNRxyHrPNr'
SECRET_KEY = 'ckDyzG*****N3t0MTgvyYaKUnSl6fSw'
client = AipOcr(APP_ID,API_KEY,SECRET_KEY)
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
image = get_file_content('test.jpg')
res = client.basicGeneral(image)
print(res)
#res = client.basicAccurate(image)
#print(res)
Directly recognize the text on the specified area of the screen
from aip import AipOcr
APP_ID = '25**9878'
API_KEY = 'VGT8y***EBf2O8xNRxyHrPNr'
SECRET_KEY = 'ckDyzG*****N3t0MTgvyYaKUnSl6fSw'
client = AipOcr(APP_ID,API_KEY,SECRET_KEY)
from io import BytesIO
from PIL import ImageGrab
out_buffer = BytesIO()
img = ImageGrab.grab((100,200,300,400))
img.save(out_buffer,format='PNG')
res = client.basicGeneral(out_buffer.getvalue())
print(res)
 Python data visualization Seaborn (II) -- Distributed Data Visualization
Python data visualization Seaborn (II) -- Distributed Data Visualization
This article is Python visuali
 Plotly The express module draws several charts, which is really amazing!!
Plotly The express module draws several charts, which is really amazing!!
author | Junxin source | Abou