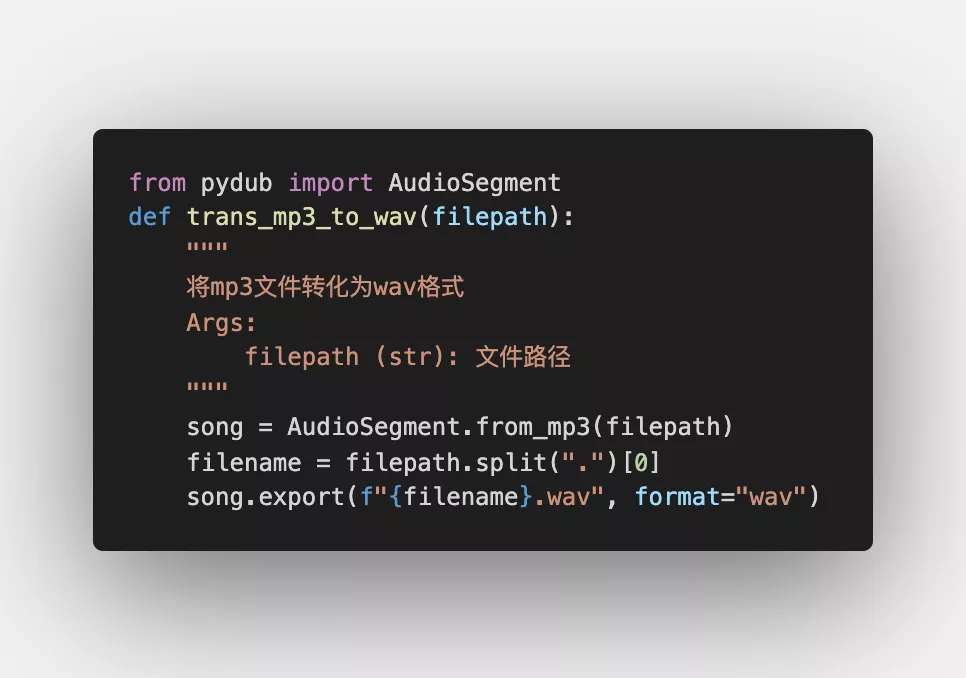
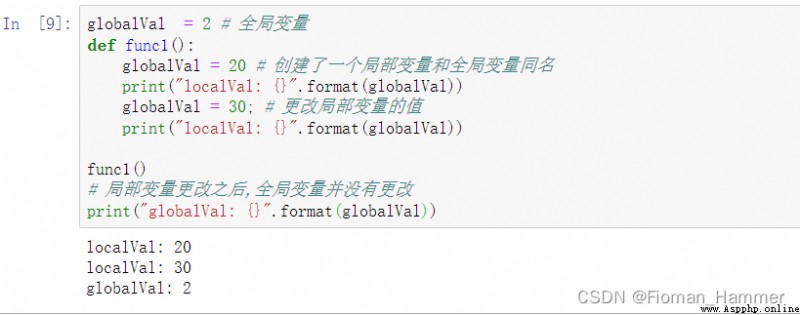
- Global variables are variables declared outside the function
- The variables declared in the function body are local variables .
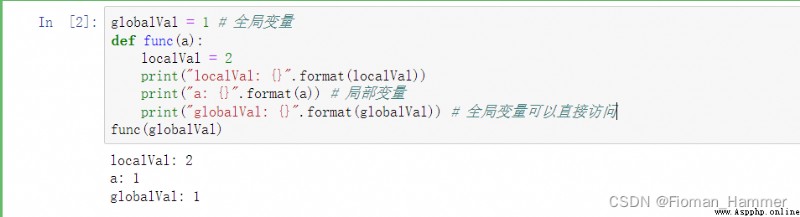
- You can access global variables directly
- But it can't be assigned directly , When assigning values directly , The compiler will think it has recreated a local variable , Only the local variable and the global variable have the same name , Then the global variables will be overwritten .
- Need help
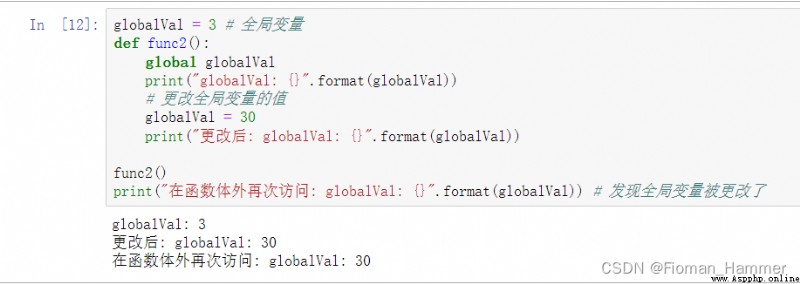
globalKeyword declarationglobalThe declaration tells the compiler , This variable is a global variable , Then it will be used as a global variable when using and compiling .
Method 1: The first reaction is pop
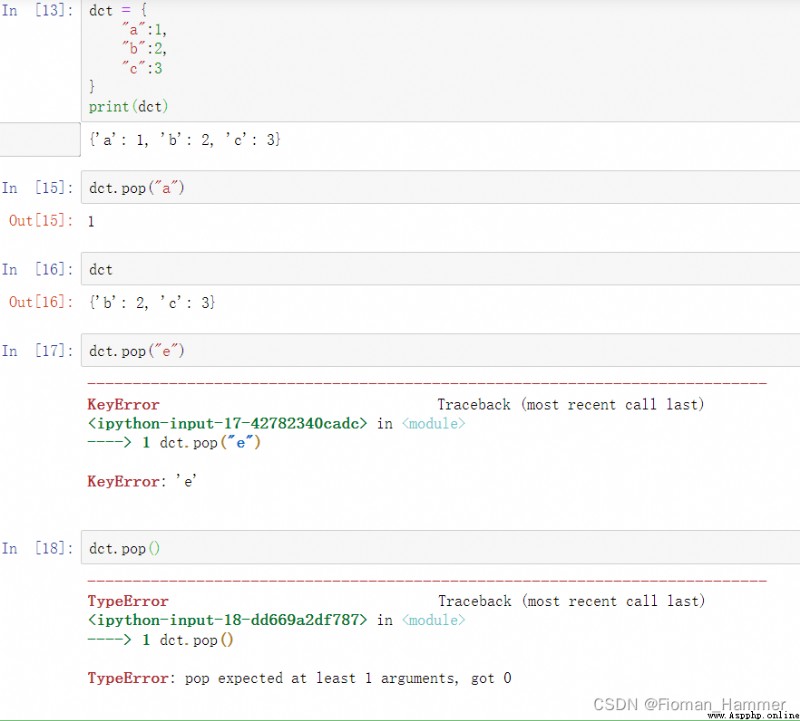
As can be seen from the above example , Dictionary pop(key) You can really delete the key of the dictionary , But there are two requirements
pop(key)Function has no default arguments , You must provide a parameter key .pop(key)Parameters key Must be a key present in the dictionary , Otherwise you will report an error
solution 2: The second reaction is remove, Not sure remove Can you , Try it .
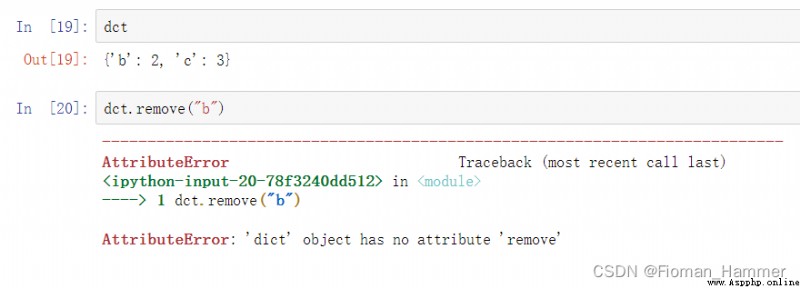
The attempt failed , There is no... In the dictionary remove Method , And then use dir(dict) Look at some attribute methods of the dictionary : as follows 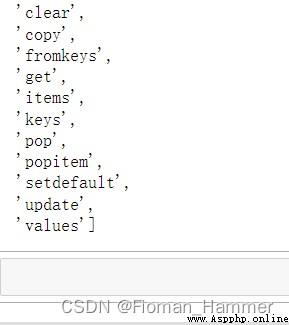
Notice that there is a
popitemMethod , This method andpopWhat's the difference ? Let's see what the official explanation says ?
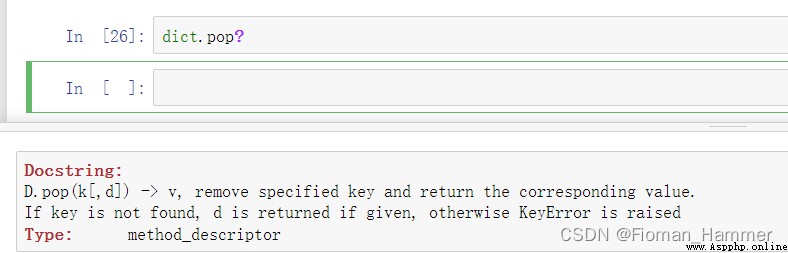
Translate :
The general meaning is to remove certain key( Parameters passed in ), And return its corresponding value. If key non-existent , If default values are provided , Return the default value , If not provided , Report on KeyError
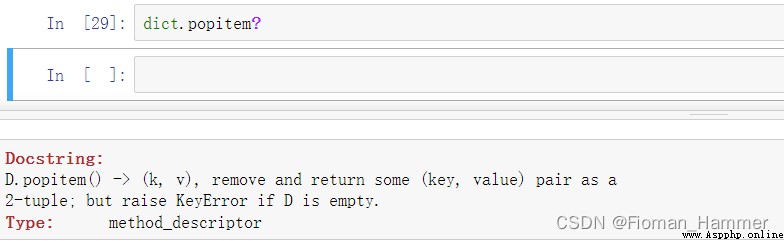
You can see it popitem() There is no parameter requirement , It removes a key value pair , And back to , But it is not clear which key value team to remove . If the dictionary is empty , Report on KeyError
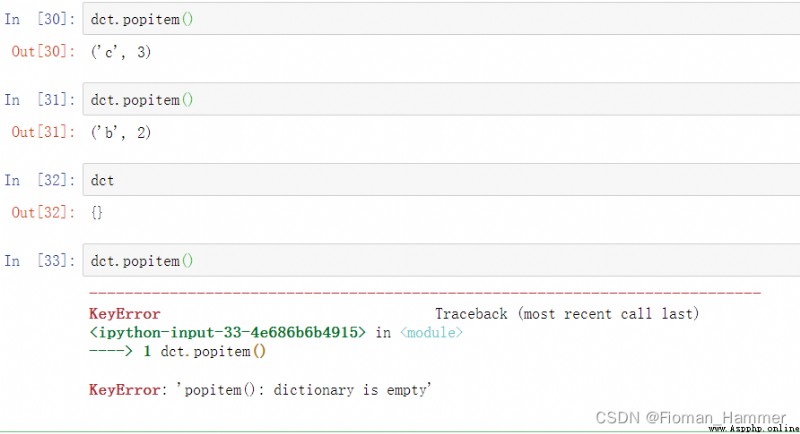
The third reaction : del
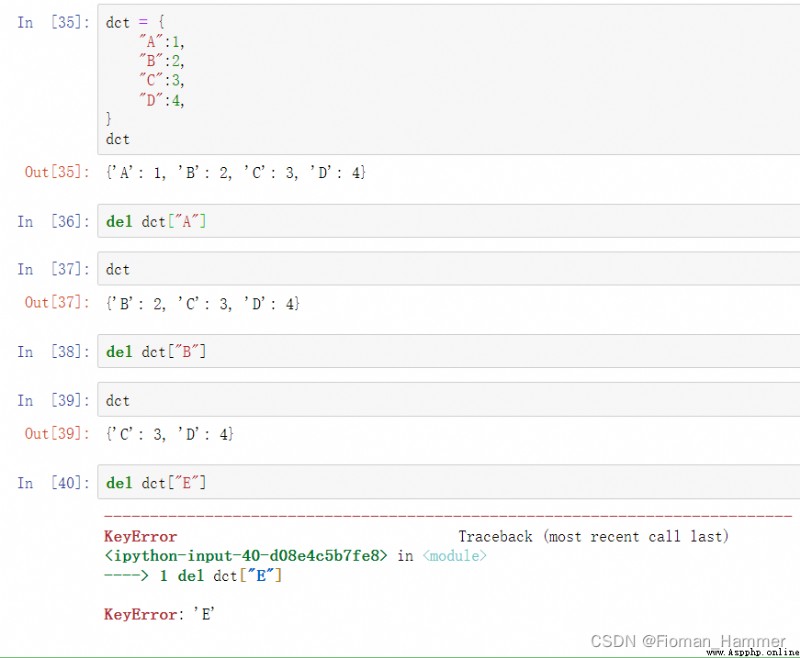
del dct[key] You can also delete the key of the dictionary , stay key It also reports an error when it does not exist . The return value is None
Method 1: There is a in my memory update Method to merge dictionaries , But the specific application is not very clear . Let's see what the document says ?
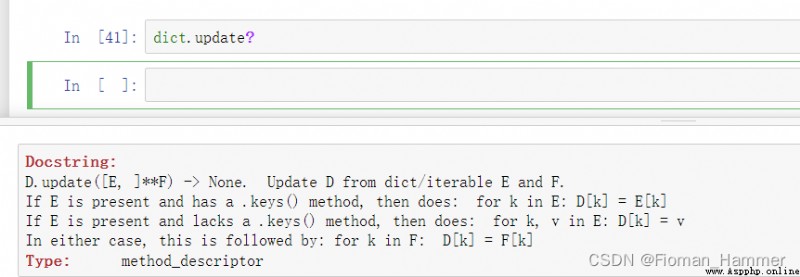
[E,]**F -> None. What is this ? Don't worry , Encounter this kind of thing , I also feel very upset , Why do other people write documents , We don't understand . Take your time first .
[E,] This kind of bracketed [] All of them indicate that this parameter is optional , Can provide , It is also possible not to provide , There are default parameters in the definition of this function .**F Express It receives a variable number of key parameters as F.
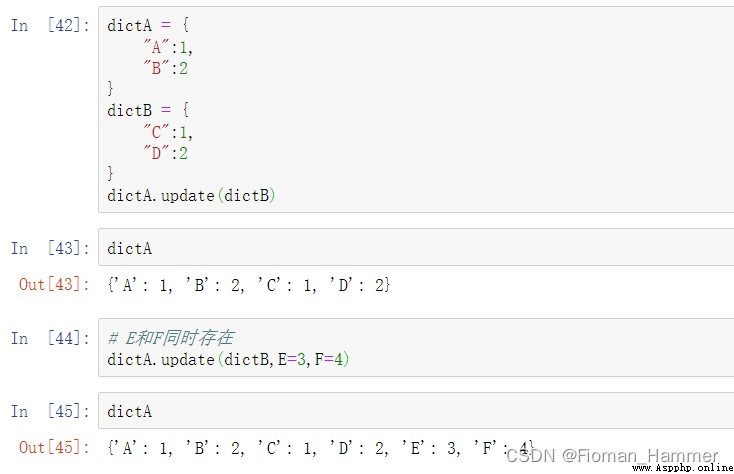
If E Provides and has a keys() Method , And then go through it , Assign a value to D
If E Yes, but no keys() Method , And then it goes through k,v, Assign a value
Either way , It will be carried out for k in F: D[k] = F[k]
First of all, there are only E And E and F In the meantime :
Look again, only F The situation of : 
Method 3: Constructors dict(d1,**d2)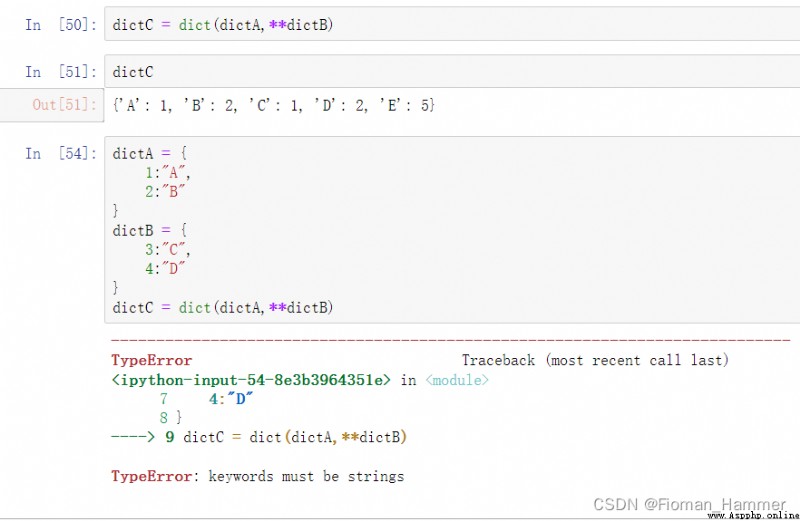
Obvious , This approach has one limitation , That is, the second dictionary must be a string as a key .
Method 4: Dictionary derivation

Be careful : This dictionary derivation is double nested , Because you have to traverse two dictionaries first , Then each dictionary uses a derivation to derive the assignment .
Method 5: Element stitching , Splice through the list , Then convert to a dictionary
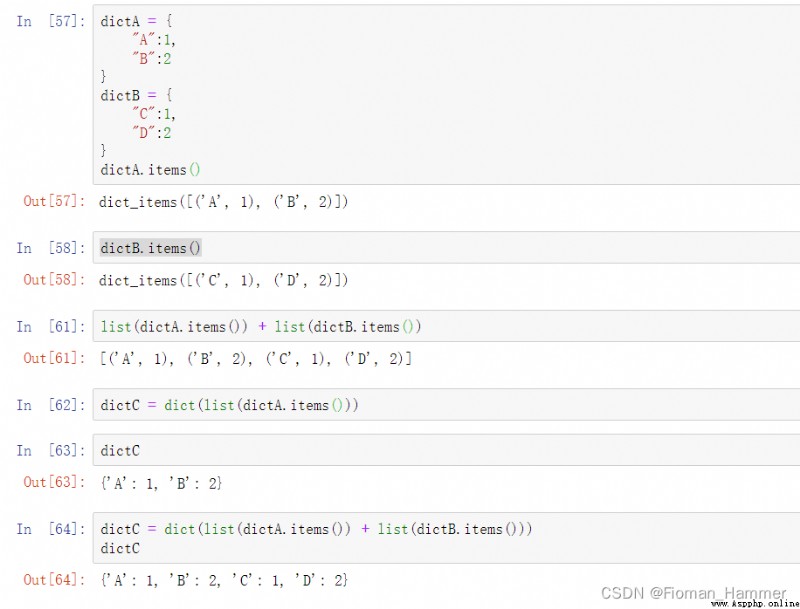
Method 6: Dictionary splitting , Through curly braces {}, It can directly form a new dictionary
newDict = {**d1,**d2,**d3,...}

__init__ and __new__ The difference between ? There are two main differences : Functionally speaking :
__init__It is mainly used to initialize objects , It calls on the premise that__new__When the current object is returned ,__init__Will be called .__new__When constructing objects , adopt__new__To create an instance of the current object .
The timing and conditions of the call :
__new__Generally, there is no need to define , It is automatically created by the compiler , When creating objects , First call__new__.__init__Generally, you need to define yourself , Used to specify your own personalized initialization , When creating objects , First call__new__, Normally this__new__An instance of the current object will be returned , If an instance of the current object is returned, it will automatically call__init__Method , If not__init__Method will not be called
Parameter and return value :
__new__()At least oneclsParameters , Represents the current class , This parameter is instantiated byPythonThe interpreter automatically recognizes . Generally, you need to return the current instance .__init__()At least one parameterself, ThisselfIn fact, that is__new__The returned instance . It's usually back to None
Look at if __new__ The current instance is not returned , And that is __new__ This parameter cls What is it ?
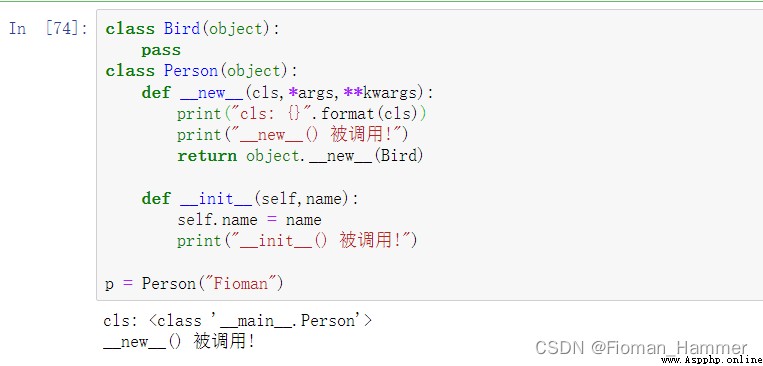
You can see __new__() This one of them cls In fact, it's time Person class , But what we return above is not Person Instance object of , therefore __init__ There is no call at all .

You can see that if you use Person Class to instantiate an object ,__init__ It will be called . It's directly used here object.__new__(Person) Actually sum super().__new__(cls) It is equivalent. .
Open the file without with Writing : 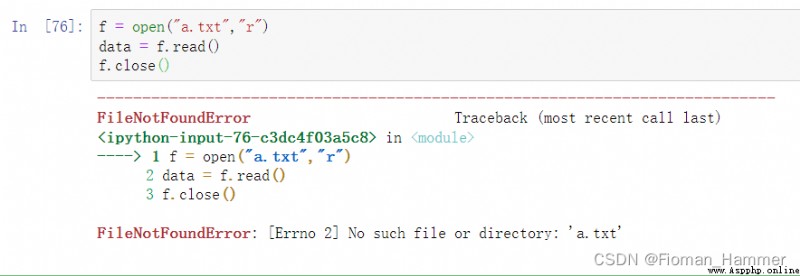
Be careful : here a.txt An exception is reported if it cannot exist . So we added try catch, And because you have to close the file stream anyway , Let's add another finally.
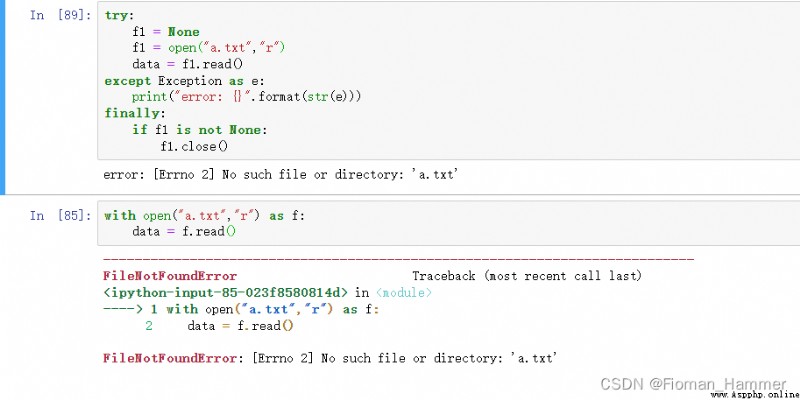
As you can see from the example above with Statement does something .
1) Throw an exception .2) Close file stream .with The principle of statement implementation :
withThe statement is implemented byContext managerRealized , Not all methods can be implemented with sentence , Only those that implement the context management protocol can be usedwithsentence .
Context Manager Protocol
__enter__(self)Method ,withWhen the statement starts running , Will be called on the context manager__enter__Method , This function usually returns an object , It's usually self , The return value of this function is assigned to the variablefollowing asOn the next variable .__with__At the end of the statement , Called on the context management object__exit__(self,exc_type,exc_value,traceback)Method , In order to playfinallyThe role of the clause . Let's see what these three parameters areexc_type,exc_val, exc_tb
Write a context manager , Then see how it works .
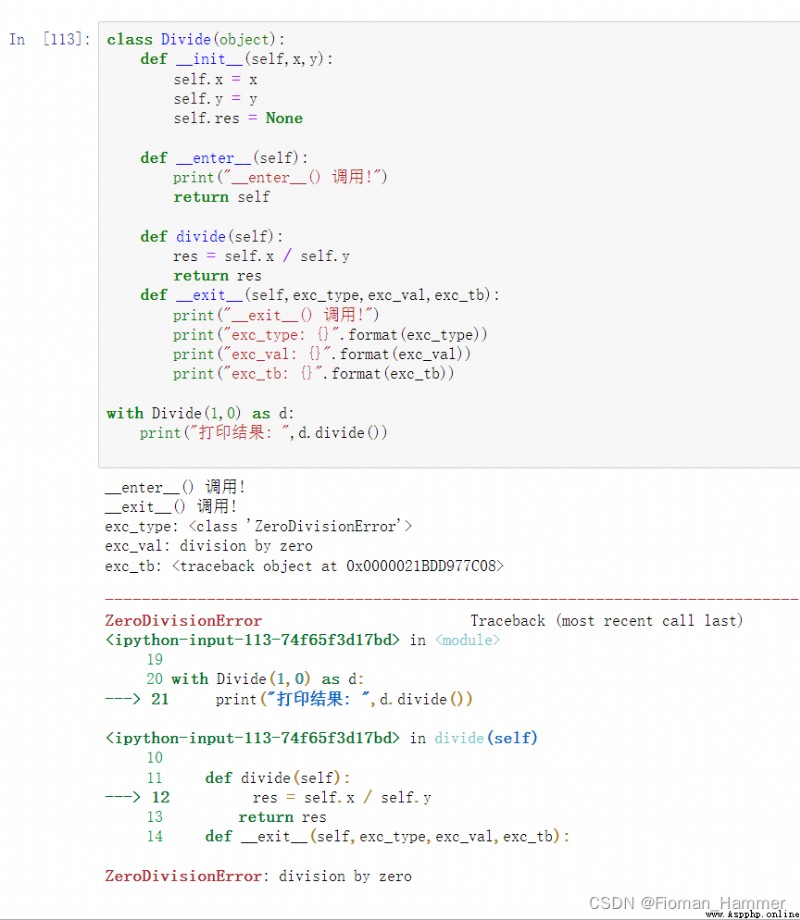
Essentially , If an exception is thrown from anywhere within the block , Will __exit__() Call the function of the object . As you can see , The type associated with the exception thrown , Values and stack traces are passed to this function . under these circumstances , You can see ZeroDivisionError Throw an exception . The person who implements the library can __exit__() Function to write cleanup resources , Close the file and other codes .
My first reaction map It's a mapping function , The front is an iteratable sequence , The following is the corresponding mapping method , It should look like this map(iterable,somefunction)
Let's test it :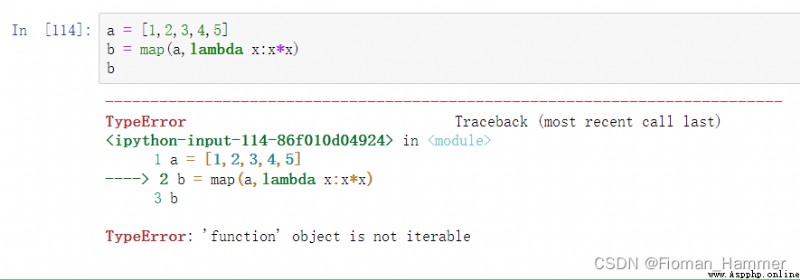
This is obviously wrong , Say that functions cannot be iterated . Is it because I remember it backwards , The previous is the mapping method , Then there are iteratable objects , I'll try again .
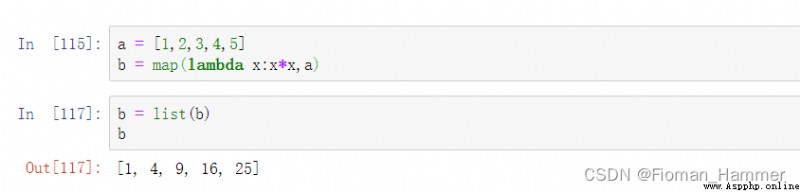
Sure enough , It's a mistake . The previous is the mapping method , Then there is the iteratable object , So when I was doing this problem , Just extend a thought , Why can't I have an iteratable object in front of me , The following is the mapping method ?
The answer is simple , Because there may be more than one iteratible object , But mapping methods can only have 1 individual , Take a look at the following example of mapping with two iteratable objects :

What if the number of iteratible objects is different , As long as one iteration ends , The mapping ends .
And then when we get here , Actually, I'm still curious , If the number of iteratible objects , When it is greater than the number of mapped parameters , What's going to happen ?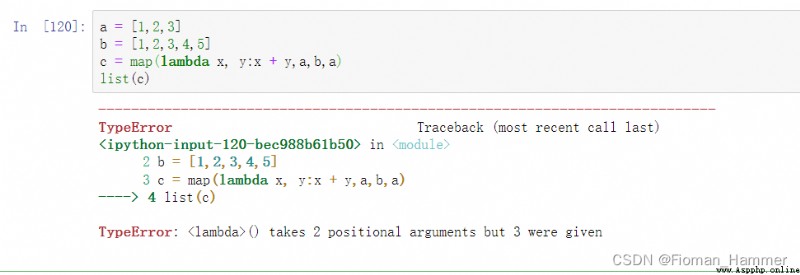
You can see that the report is wrong , Empathy , If there are too few parameters , It's also a mistake .
So I know map Usage of , The answer above is easy to solve , It can be solved directly by finding another layer of conditional list derivation .

The first thing I think of is this , Generate random integers . Right or wrong , Let's go and have a look at , Under test .
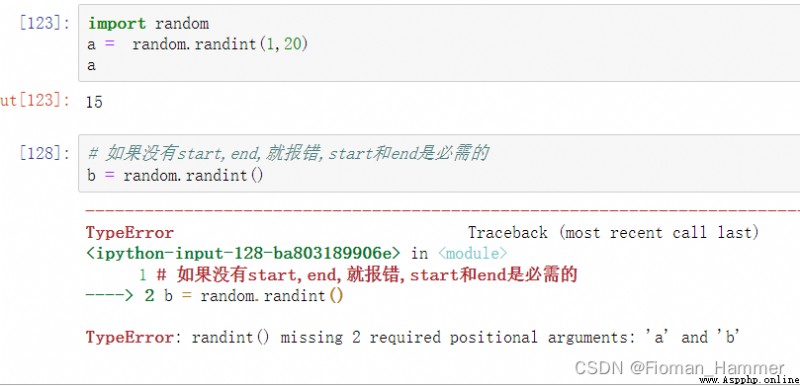
Okay , Now let's take a look at the description of this function :
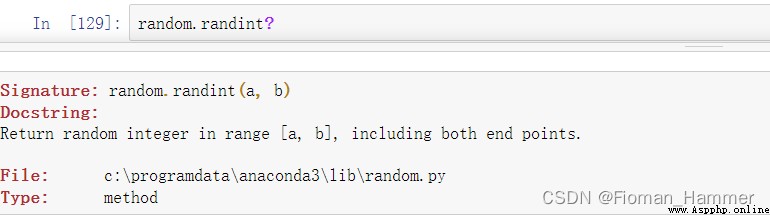
Translate for you :
Is to return to a [a,b] An integer between , contain a and b. If you verify , contain a and b Well

I have the impression that there is such a function to generate decimals , Is there , We still need to verify .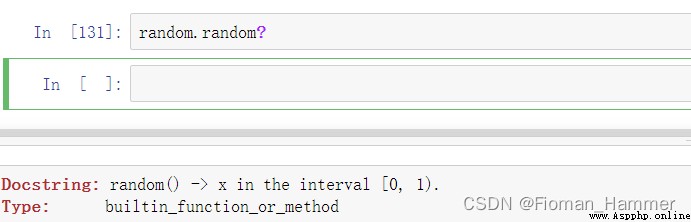
Sure enough , This function returns [0,1) A floating-point number of , Note that this category does not include 1, But it includes 0.
I remember this function , But I don't remember very clearly , Go and verify :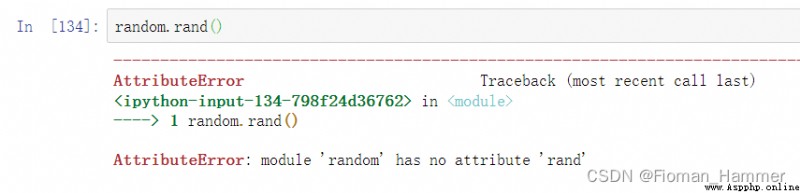
The fact proved that , There is no , What exactly is the function ? We use dir(random) look down

There are many functions in it , Let's see which one is more like what we're looking for . Let's see randrange() What is it ?

Translate, translate :
Get a random integer , from range(start,stop[,step]) Within the scope of , This solves randint() It contains the question of the last point . Sometimes , It may not be necessary for the last point to be randomly assigned to , You can use this method .

Although this is also a random number , But it's obviously not the way we're looking for to find random decimals , Let's move on to the next .
sample() Does it look similar? ? I really have no impression here , Just look at the documentation .

ah , So long , It's like giving up , But now that I have met , Just study what this thing is ? In translation .......
The simple explanation is from population Select from this sequence or set k A unique random element .
Returns a new list containing from population Elements selected in , And maintain population The elements in the do not change .
The list of results is arranged in order , So all the sub slices are valid random samples .
This allows the winner of the raffle ( This sample ) It can be partitioned , Divided into first prize and second prize ( Child Columns )
The data in the sample set does not have to be hashable or unique , If the sample contains duplicate elements , Then each of the repeating elements may be the choice of the sample . This uncertain .
To select a sample within an integer range , Please use range() As a parameter . From a Total sampling , This is particularly fast and space efficient .

After getting here , In fact, I don't quite understand the first prize and the second prize , I think the general meaning is that its subsequence can still be regarded as a complete random sequence .
Then go and see that uniform() function , I found this when I checked the data , This is how to generate random decimals in the range .
Look at what the official documents say ?
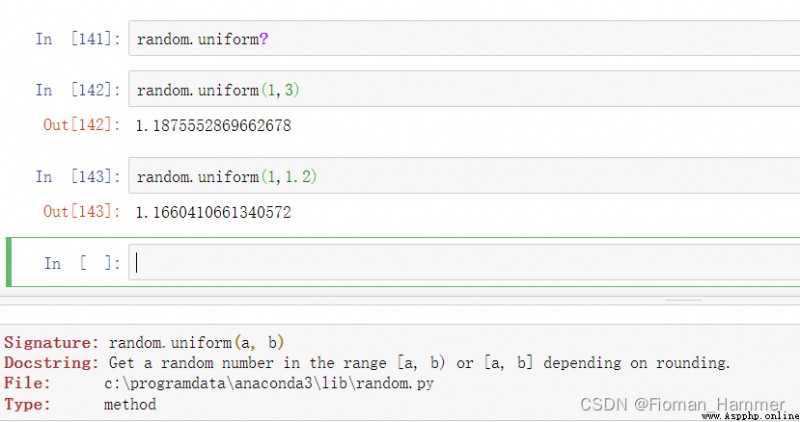
Obtain by rounding [a,b] perhaps [a,b) The random number , It can also be a random decimal .