- 全局變量就是在函數體外聲明的變量
- 函數體內聲明的變量是局部變量.
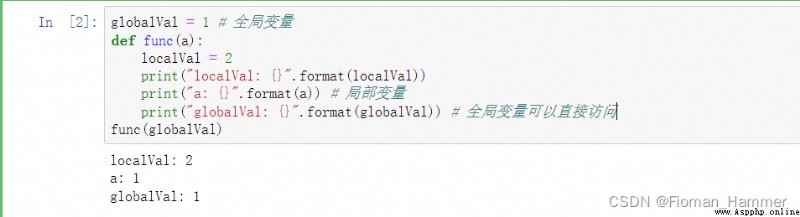
- 可以直接訪問全局變量
- 但是不能直接賦值,直接賦值的時候,編譯器會認為是重新創建了一個局部變量,只是這個局部變量和全局變量重名,然後會把全局的變量覆蓋掉.
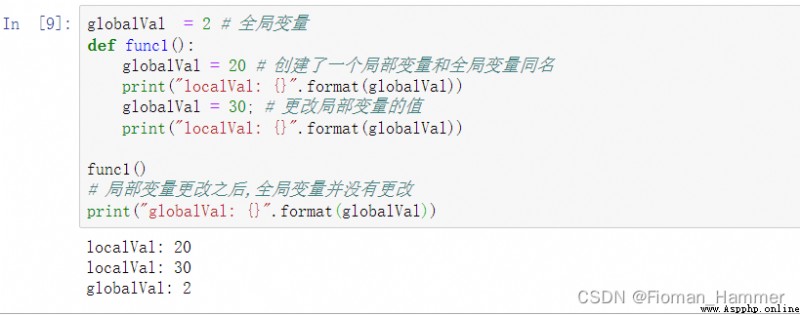
- 需要借助
global關鍵字聲明global聲明會告訴編譯器,這個變量是全局變量,然後在使用和編譯的時候就會當成全局變量來使用.
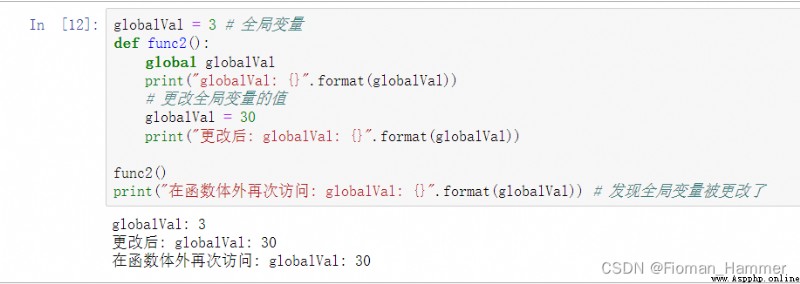
方法1: 第一反應是pop
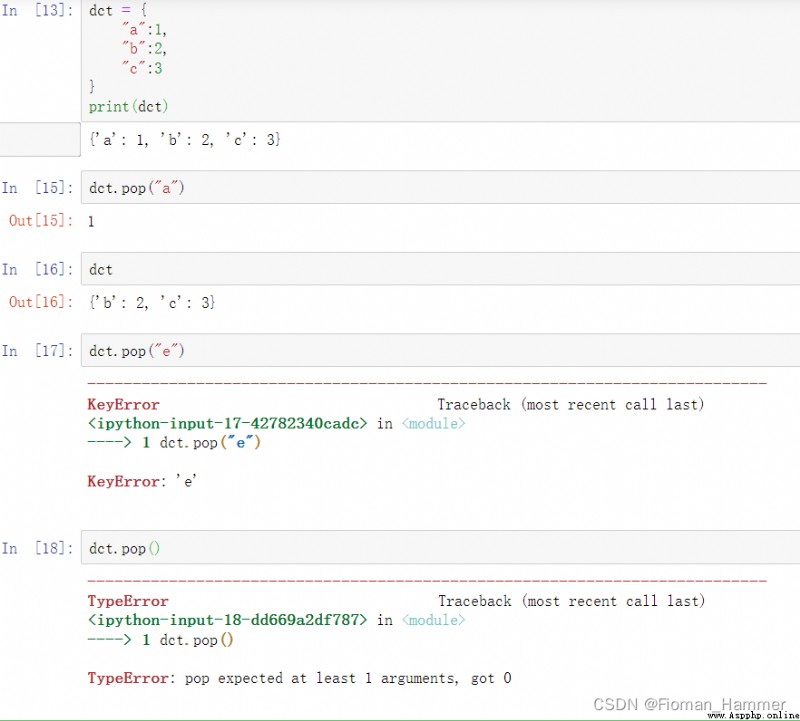
從上面的示例可以看出來,字典的pop(key)確實可以刪除字典的鍵,但是有兩個要求
pop(key)函數沒有默認參數,必須提供一個參數鍵.pop(key)參數key必須是字典中存在的鍵,否則就會報錯
解法2: 第二反應是remove,不確定remove可不可以,嘗試一下.
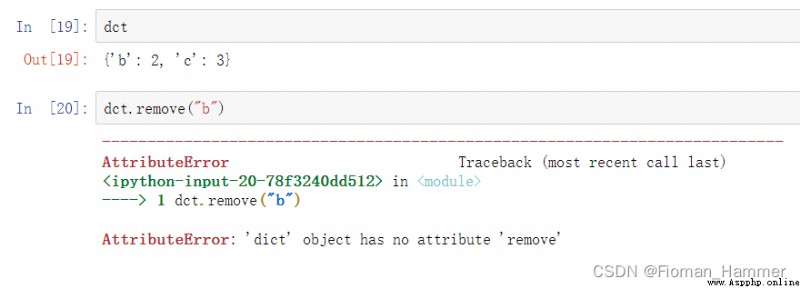
嘗試失敗,字典中沒有remove方法,然後使用dir(dict)看看字典的一些屬性方法:如下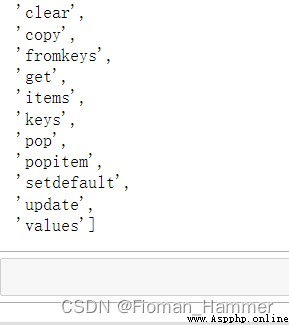
注意看這裡有一個
popitem方法,這個方法和pop有什麼區別呢? 我們看看官方的解釋怎麼說?
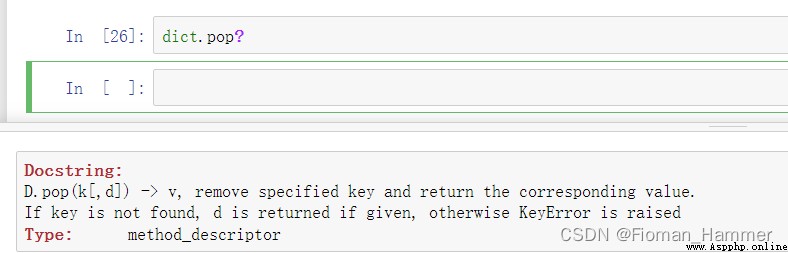
翻譯一下:
大概的意思就是移除掉確定的key(參數傳遞進來的),並且返回它對應的value.如果key不存在,如果提供了默認值,就返回默認值,如果沒有提供,就報KeyError
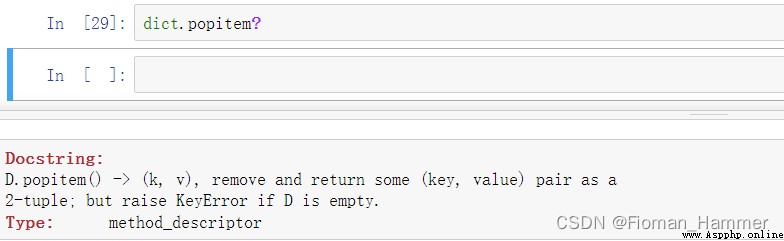
可以看出來 popitem()是沒有參數要求的,它是移除掉一個鍵值對,並且返回,但是具體移除哪個鍵值隊不能明確.如果字典為空,就報KeyError

第三反應: del
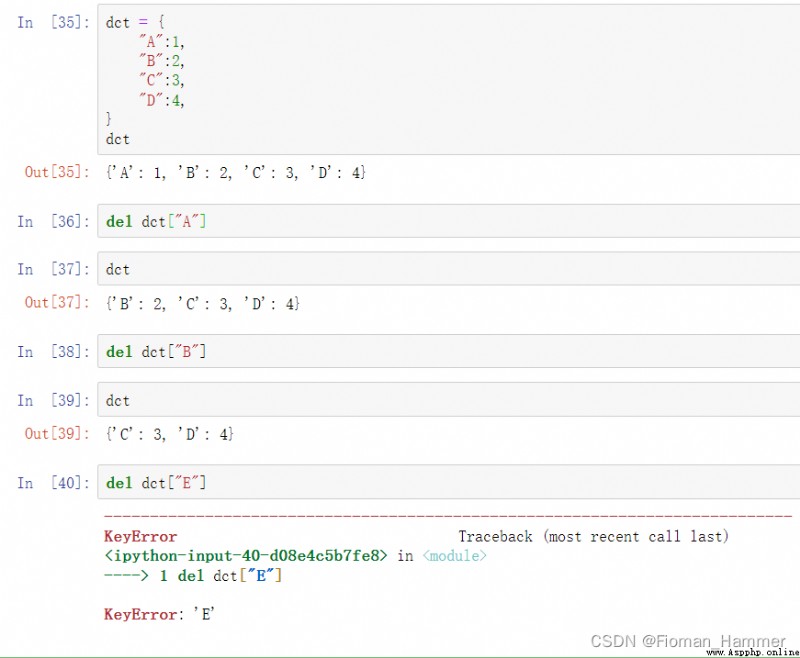
del dct[key] 的方式也可以刪除字典的鍵,在key不存在的時候也報錯.返回值是None
方法1: 記憶中有個update方法用來合並字典的,但是具體的應用不是很清晰了.我們看下文檔怎麼說?
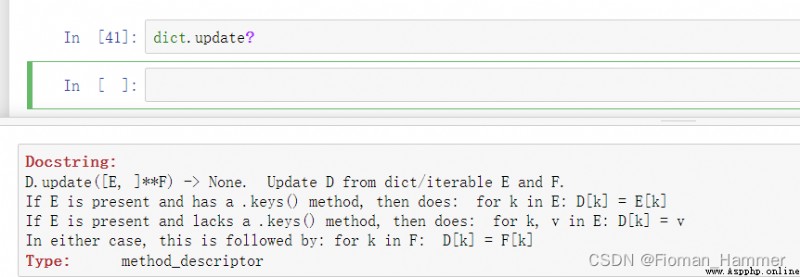
[E,]**F -> None. 這是個啥? 不要急,遇到這種事情,我也感覺很煩躁,為啥別人寫的文檔,我們看不懂.先慢慢看.
[E,] 這種帶中括號[]的都表示這個參數是可選參數,可以提供,也可以不提供,就是這個函數的定義中有默認的參數了.**F 表示 它接收數量可變的關鍵字參數作為F.
如果E提供了並且有一個keys()方法, 然後就遍歷它,賦值給D
如果E提供了但是沒有keys()方法,然後就遍歷k,v,進行賦值
無論是哪種情況,都會執行 for k in F: D[k] = F[k]
先看看只有E的情況以及E和F同時存在的情況:
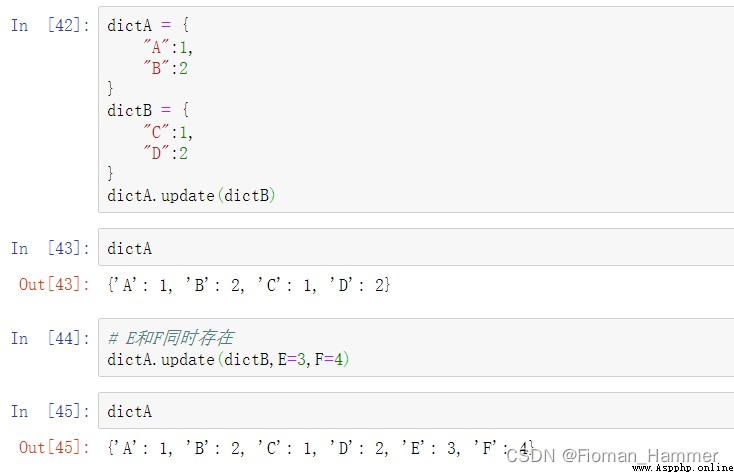
再看看只有F的情況: 
方法3: 構造函數 dict(d1,**d2)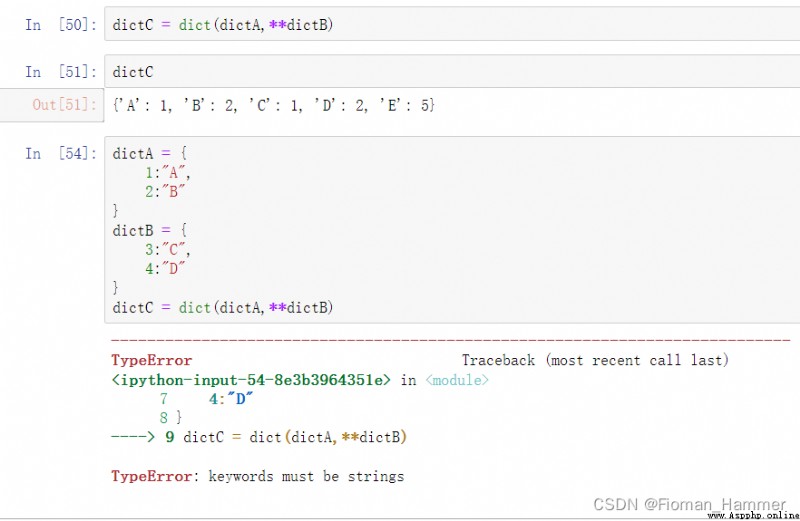
顯而易見,這種方式有一個局限,那就是第二個字典必須是字符串作為鍵才行.
方法4: 字典推導式

注意: 這個字典推導式是雙層的嵌套的,因為要先遍歷兩個字典,然後每個字典分別使用推導式來進行賦值推導.
方法5: 元素拼接,通過列表拼接,然後轉換為字典
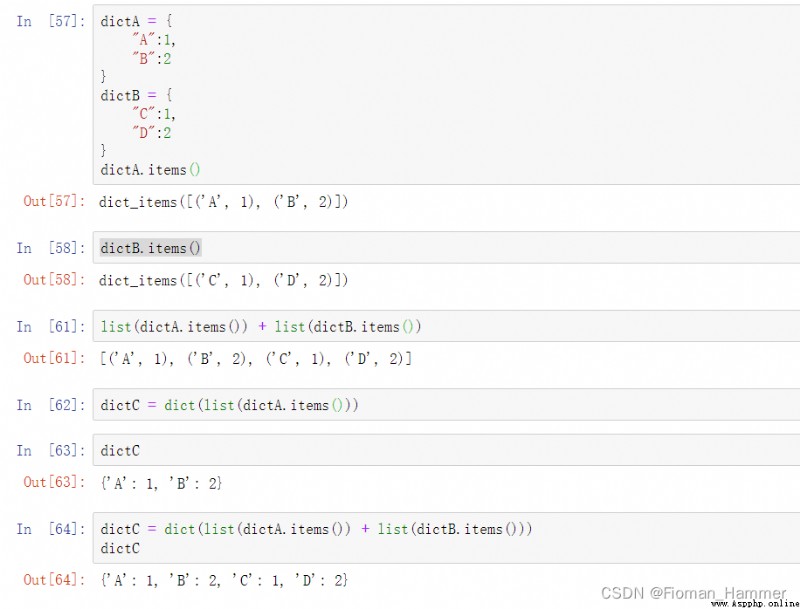
方法6: 字典拆分法,通過大括號{},可以直接組成新字典
newDict = {**d1,**d2,**d3,...}

__init__和__new__的區別?區別主要從兩個方面來說:功能上來講:
__init__主要是用來初始化對象,它調用的前提是必需__new__返回了當前的對象的時候,__init__才會被調用.__new__對象構造的時候,通過__new__來創建一個當前對象的實例.
調用的時機和條件:
__new__一般是不需要定義的,它由編譯器自動創建,在創建對象的時候,先調用__new__.__init__一般需要自己定義,用來指定自己的個性化初始化,在創建對象的時候,先調用__new__,正常來講這個__new__會返回一個當前對象的實例,如果返回了當前對象的實例會自動調用__init__方法,如果沒有則__init__方法不會被調用
參數和返回值:
__new__()至少要有一個cls參數,代表當前的類,此參數在實例化的時候由Python解釋器自動識別.一般是要返回當前的實例.__init__()至少要有一個參數self,這個self其實就是__new__返回的實例.一般是返回None
看下如果__new__沒有返回當前實例的情況,還有就是__new__這個參數cls到底是個什麼東西?
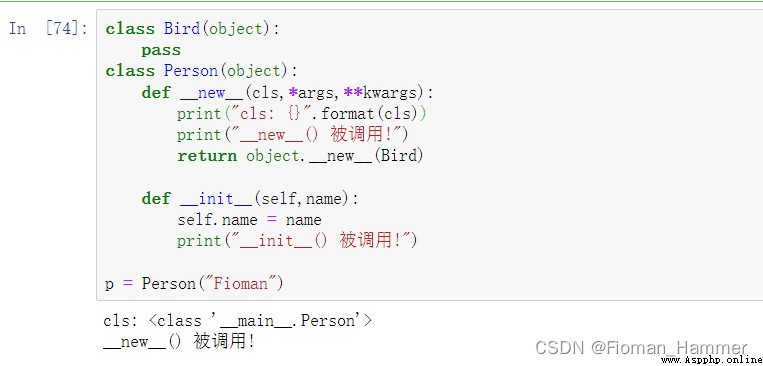
可以看到 __new__()當中的這個cls其實就時Person類,但是上面我們返回的不是Person的實例對象,所以__init__根本就沒有調用.

可以看到如果使用Person類去實例化對象,__init__就會被調用. 這裡直接用object.__new__(Person) 其實和 super().__new__(cls)是等價的.
打開文件不用with的寫法: 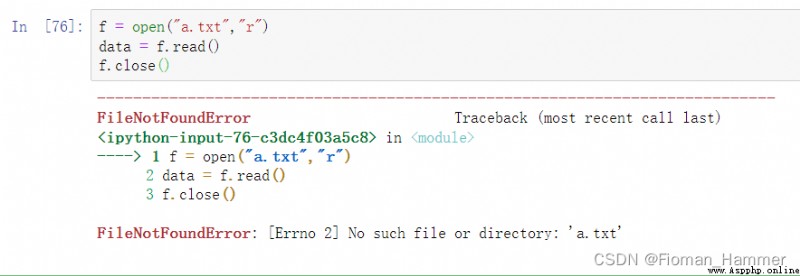
注意: 這裡a.txt不能存在就報了異常.所以我們加入了try catch,又因為最後無論如何都要關閉文件流,我們再加一個finally.
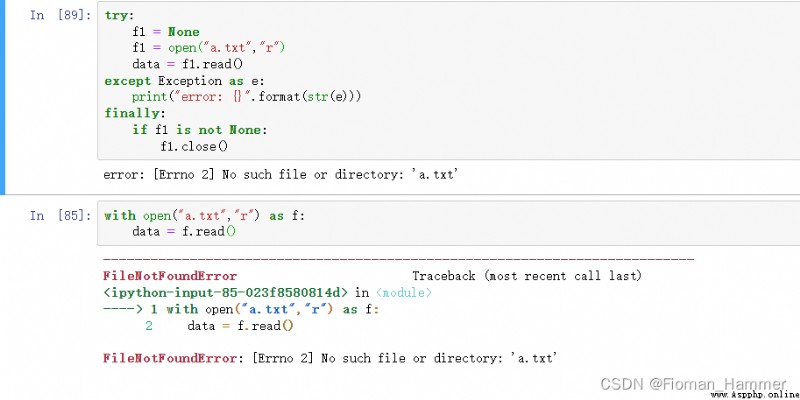
從上面的示例中可以看到with語句做了什麼事情.
1) 拋出異常.2) 關閉文件流.with語句的實現原理:
with語句的實現是通過上下文管理器來實現的,不是所有的方法都可以實現with語句,只有那種實現了上下文管理協議的才能使用with語句.
上下文管理器協議
__enter__(self)方法,with語句開始運行的時候,會在上下文管理器上調用__enter__方法,這個函數一般返回一個對象,一般是自身,此函數的返回值分配給變量following as後面的那個變量上面.__with__語句運行結束的時候,會在上下文管理對象上調用__exit__(self,exc_type,exc_value,traceback)方法,以此扮演finally子句的角色.我們看看這三個參數到底是個什麼玩意exc_type,exc_val, exc_tb
寫一個上下文管理器,然後看看怎麼運行的.
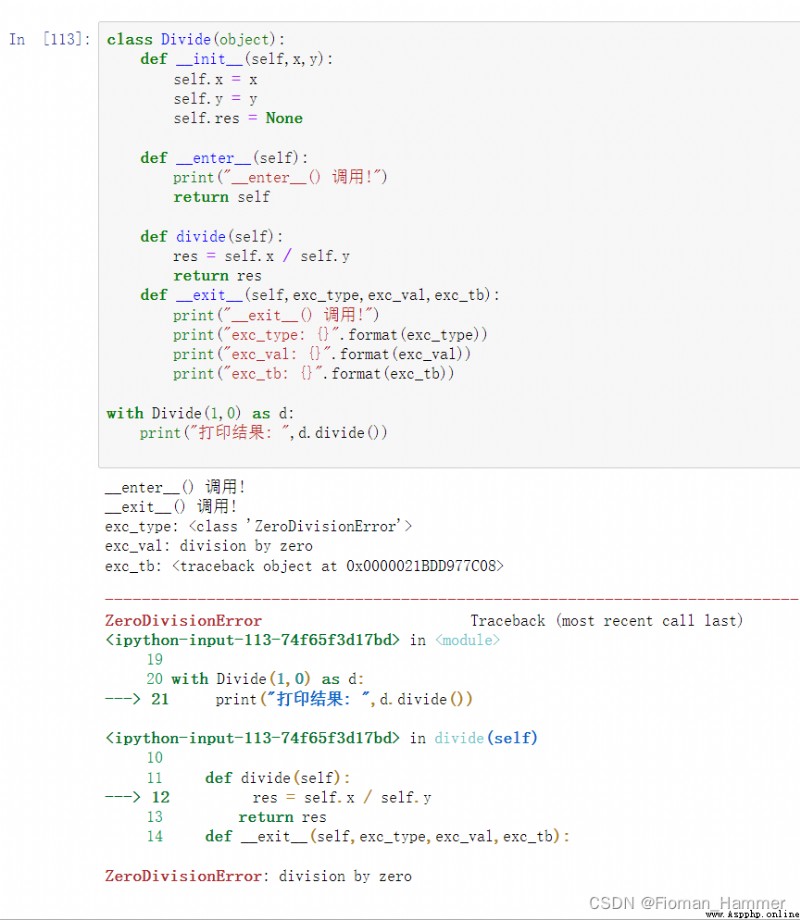
本質上,如果從塊內的任何地方拋出了異常,則將__exit__()調用該對象的函數.如您所見,與引發的異常關聯的類型,值和堆棧跟蹤將傳遞給此函數.在這種情況下,您可以看到ZeroDivisionError拋出異常.實現庫的人員可以在其__exit__()功能中編寫清理資源,關閉文件等代碼.
我的第一反應map是一個映射函數,前面是一個可迭代的序列,後面是對應的映射方法,應該是長這個樣子的map(iterable,somefunction)
下面測試下: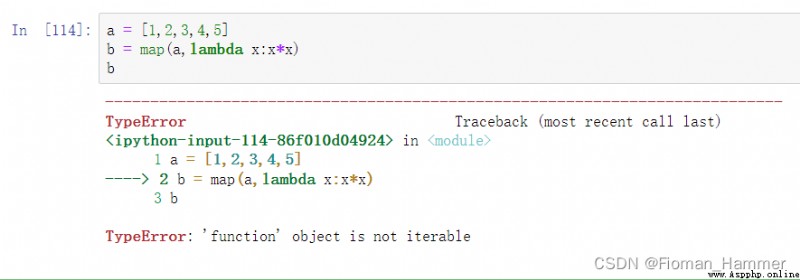
這裡明顯不對,說函數是不可以迭代的. 難道是我記反了,前面是映射方法,後面是可迭代對象,我再試試.
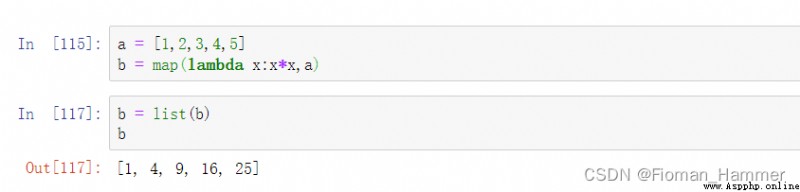
果然,是記錯了.前面是映射的方法,後面才是可迭代對象,所以我在做這個題的時候,就引申出來一個思考,為啥不能前面是可迭代對象,後面是映射方法呢?
答案是很簡單的,因為可迭代對象可能有多個,但是映射方法只能有1個,看下下面的用兩個可迭代對象進行映射的例子:

如果多個可迭代對象的個數不一樣呢,只要有一個迭代結束,映射就結束.
然後研究到這裡的時候,其實我還是很好奇,如果可迭代對象的個數,大於映射的參數的個數的時候,會發生什麼?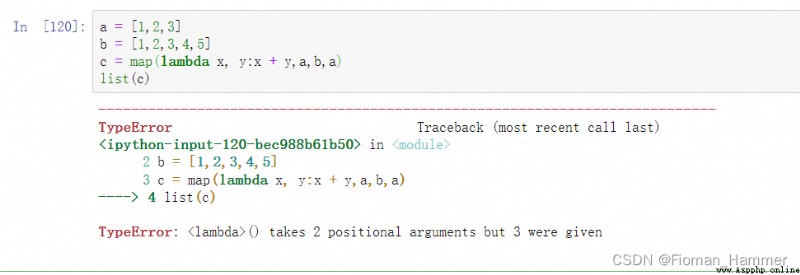
可以看到報錯了,同理,如果參數太少,也是會報錯.
所以知道了map的用法,上面的答案就容易搞定了,就是直接用帶條件的列表推導式再求一層就能解決.

我首先想到的是這個,生成隨機的整數.具體對不對,我們去看看,測試下.
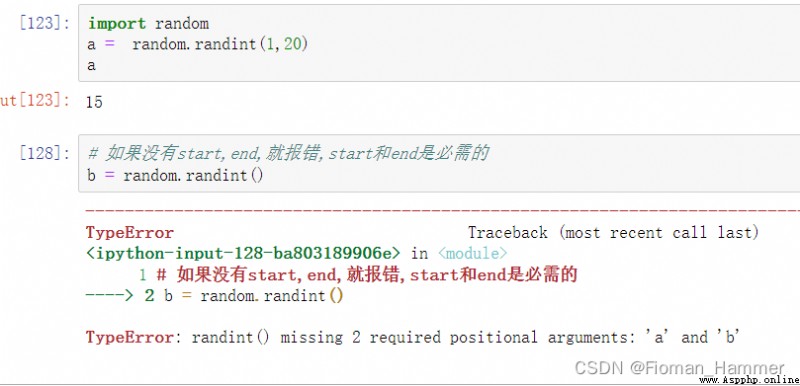
好了,現在我們查看一下這個函數的說明:
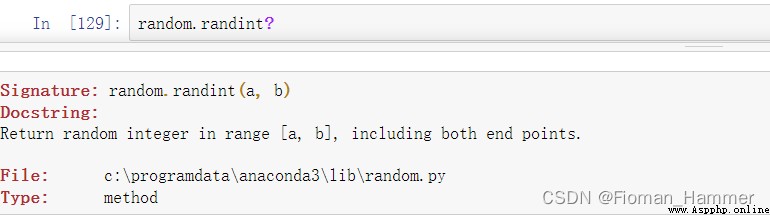
翻譯君給大家翻譯一下:
就是返回一個[a,b]之間的一個整數,包含a和b. 如果驗證,包含a和b呢

我印象中生成小數的有一個這樣的函數,到底有沒有,還是要去驗證一下.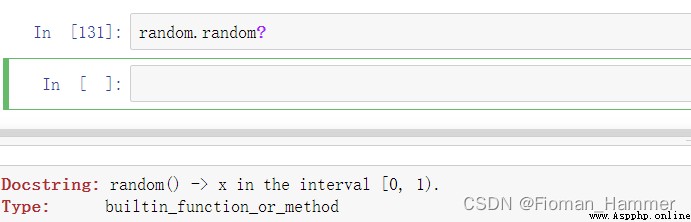
果然有,這個函數返回的是[0,1)的一個浮點數,注意這類不包括1,但是包括0.
我記得好像有這個函數,但是記得不太清楚了,去驗證一下: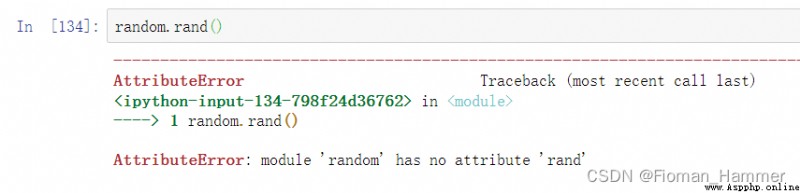
事實證明,是沒有的,具體有什麼函數呢? 我們使用dir(random)看下

這裡面有很多的函數,我們先看看哪個比較像我們找的.我們先看看randrange()是個什麼東西?

翻譯君翻譯一下:
得到一個隨機整數,從range(start,stop[,step])范圍內,這個解決了randint()中包含最後那個點的問題.有些時候,可能不需要最後那個點被隨機到,就可以使用這種方法.

這個雖然也是求隨機數,但是明顯不是我們要找的那個求隨機小數的方法,我們繼續看下一個.
sample()像不像?這裡我真的沒什麼印象,就直接看文檔吧.

啊,好長,突然就像放棄了,但是既然遇到了,就研究下這個東西是個啥吧?翻譯君翻譯中.......
簡單的解釋就是從 population這個序列或者是集合當中選擇k個唯一的隨機元素.
返回一個新的列表包含從population中選取的元素,並且維持population中的元素不變.
結果列表按照順序排列,所以所有的子片都是有效的隨機樣本.
這允許抽獎獲勝者(本樣本)可以進行分區,分成一等獎和二等獎(子列)
樣本集合中的數據不必是可哈希或者是唯一的,如果樣本中包含重復的元素,那麼重復的元素的每一個都可能是樣本的選擇.這個不確定的.
要在整數范圍內選擇一個樣本,請使用range()作為參數.對於從a總采樣,這是特別快速和節省空間的.

搞到了這裡之後,其實我對於那個一等獎和二等獎還不是很理解,我想大概意思就是它的子序列依舊可以當成一個完整的隨機序列的意思.
然後去看看那個 uniform()函數,這個是在查資料的時候發現的,這個就是生成范圍內隨機小數的.
看看官方文檔怎麼說?
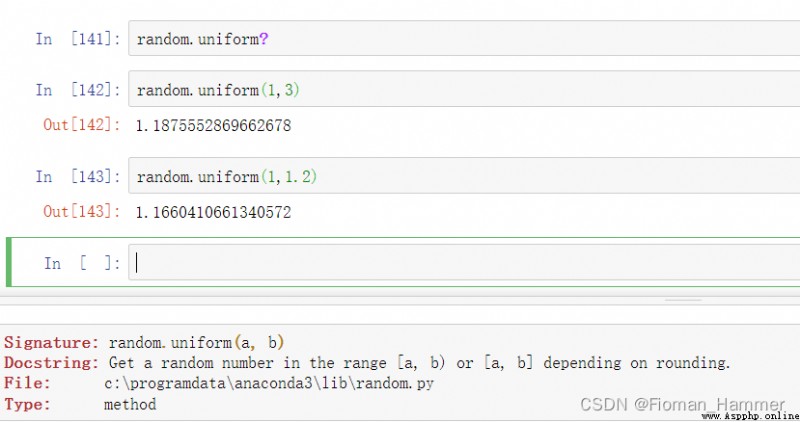
根據四捨五入的情況獲取[a,b]或者[a,b)的隨機數,也可能是隨機小數.