Recently, I received a paid Q & A in Zhihu , Although the paid Q & a function has been opened , But I haven't answered the questioner's question for a long time .
Due to limited time and energy , I can't spare the whole time to answer the questioner's questions , And don't want to fool the students who ask questions in a few words , Just don't answer .
however , A few days ago, a classmate paid me to consult ” How to use Python hold 3 individual PDF The files are merged together in cross order ?“
You bet ,PDF、Word As a document format often encountered in work and study , It's hard to avoid dealing with them , today , Let's introduce how to use Python Complete common PDF、Word Editing function , You don't have to pay for this simple thing anymore !
PDF file
PDF Is a portable file format , It contains text 、 Images 、 Charts, etc. .
Unlike plain text files , It is a method that contains ".pdf" File with extension , from Adobe The company invented .
This type of file is compatible with any platform such as software 、 Hardware has nothing to do with the operating system .
Installation kit
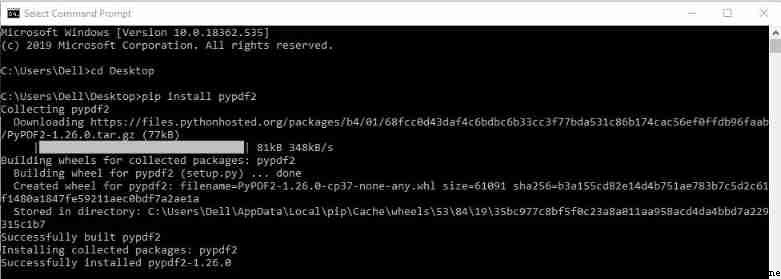
You need to install one called
pypdf2 Software package , It can handle files with extensions ".pdf " The file of :
pip install pypdf2
Installation successful , You'll see the following :
Read PDF File and extract data
We can only pdf Extract text content from file , because PyPDF2 There is a limitation when extracting multimedia content ,logo、 Pictures, etc. cannot be extracted from .
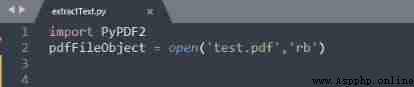
In the code above
import The statement gets PyPDF2 modular . You need to use
open('pdfFileName' , 'openMode'), among
pdfFilename It's the name of the file ,
openMode yes
rb, That is, only binary formats are read .

PyPDF2 There is one named "PdfFileReader" Methods , It receives newly created objects "pdfFileObject". You can start from now on "pdfFileObject " The access name in is "numPages" Properties of , It can return the total number of pages .
You can use pdfReaderObject Inside 'getPage(0)' Method to get the 1 page . Then store the results in 'firstPageObject' in , By using 'extractText()' Method can print out all the text in the specific page .

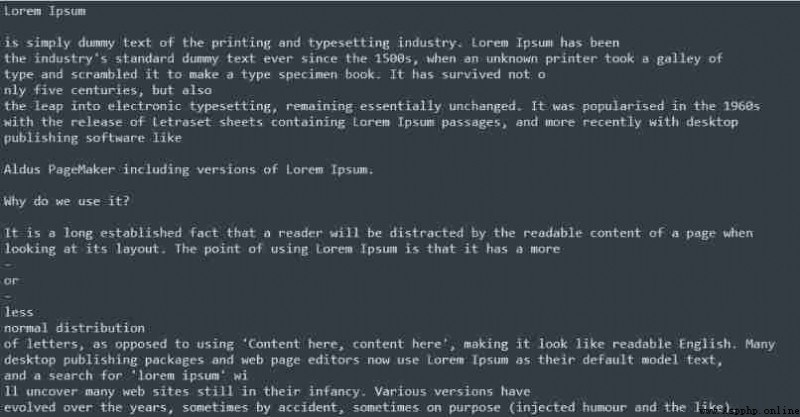
The code above gives pdf All text of the file . however , The image is not displayed on the terminal , This is useful pyPDF2 Yes, we can't get it .
Merge PDF
You will put two different pdf Merge the files into one pdf file , First you need to get 2 One for testing PDF file .
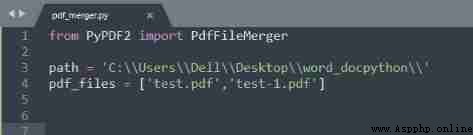
We need to go from PyPDF2 Import PdfFileMerger modular , It can be used to merge pdf file .
Appoint 'path', It indicates the path of the folder where the file is located . in addition , To merge pdf The file is contained in 'pdf_files' List of .
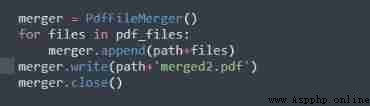
First , Need to pass through
PdfFileMerger Create a merge object , Then the traversal of each file in the list , The merger is through 'append' Method to pass the path and file .
Last , By using 'merger.write()' You can get the final output , Here you can get the merged content and new PDF file name .

The image above shows a 'merged.pdf', It consists of 'test.pdf' and 'test-1.pdf' Merge the contents of .
Word file
Word The file is defined by the... At the end of the file name ".docx " The extension consists of . These files do not contain only text like plain text files , It includes rich text files . Rich text files contain different structures of files , These structures have sizes 、 alignment 、 Color 、 picture 、 Font, etc. .
If you have one for processing Word Document application , That would be the best . Apply to Windows and Mac The popular application of the operating system is Microsoft Word, But it's a paid subscription Software .
Of course , There is also a free alternative , Such as "LibreOffice", It is a pre installed in Linux Applications in . These applications can be found in Windows and Mac Download from the operating system .
this paper , How to pass Python Free operation Word file .
Installation kit
You need to install one called "python-docx" Software package , It can handle files with extensions ".docx " Of word file .

edit Word file

You can see in the first line above "document" The module is from "docx " Imported from package .
The second line of code passes Document Object generates a new word file .
Use 'document.save()', The file name is saved as 'first.docx'.
Add the title
The above code contains a
Document() Open a new file ,
document.save('addHeader.docx') Used to create a new edit docx file .
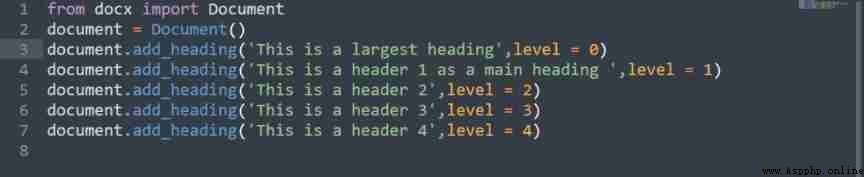
You can go through
add_heading('text,' level=number) Method to add a title , This method takes the text as the title , The title level is from 0 To 4 Start .

The output given by the above code is a newly created 'addedHeader.docx' file , among 0 The title of the level is the horizontal line below the text , and 1 The title of the level is the main title .
similarly , Other titles are subtitles , The font size decreases in turn .
Add paragraph
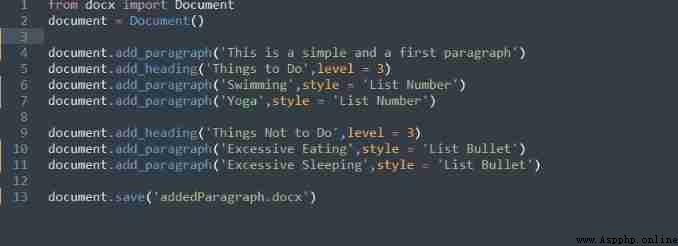
The above code contains a
Document(), It opens a new document file ,
document.save('addParagraph.docx') Used to create a new edit docx file . You can go through
add_paragraph('text,' style='required_style') Method to add a title , This method receives text , meanwhile
style Is an optional parameter , have access to 'List Number' and 'List Bullet'.
The output given by the above code is a newly created
addedParagraph.docx file , There is a simple paragraph on the first line .
Again , There is a title , Below it is an ordered list , Contains a number 1 and 2 Project .
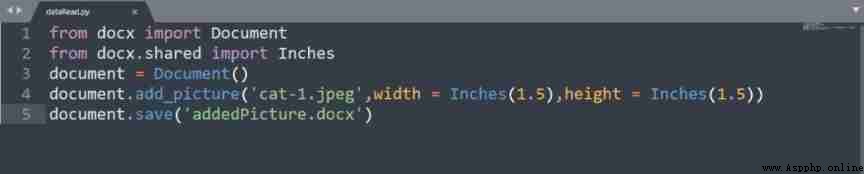
Add images

The above code contains a
Document(), It creates a new document file ,
document.save('addPicture.docx') Used to create a new edit docx file .
You can use
add_picture() To add pictures , The first parameter it contains is
cat-1.jpeg Is the path of the picture of the cat .

Width and height are optional parameters , The default is
72 dp, But we used... For our purposes
Inches.
The output given by the above code is a newly created
addedPicture.docx file , It contains an image of a cat , The width and height of the image are 1.25 Inch .
Read Word file
Next , We use Python Read a word file .
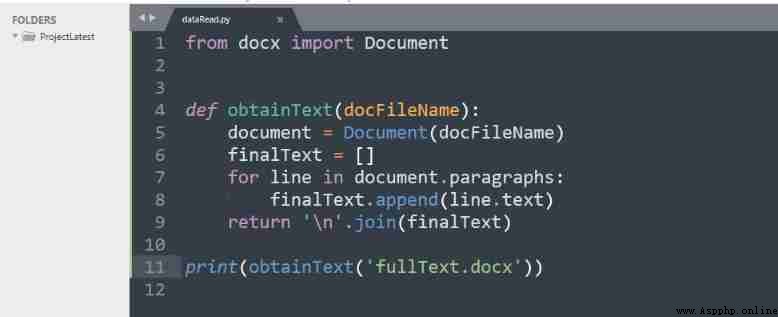
The first line of code starts with
docx Import in module Document, Used to transfer the required document files , And create an object .
obtainText It's a function , Receive the file
fullText.docx. The loop is for each paragraph , These paragraphs are composed of
document.parages visit , And use
append Method is inserted into an empty list .
Last , This function returns a value in ” Another line “ List of ending paragraphs .
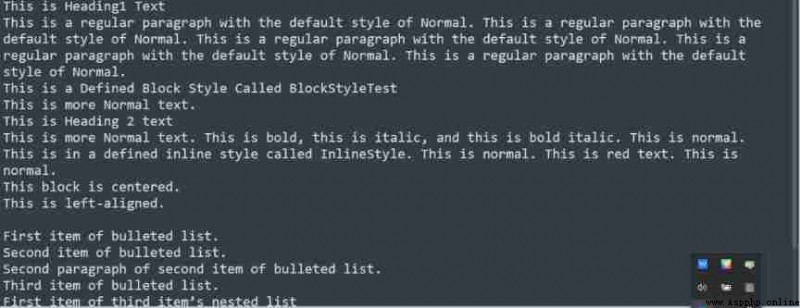
The output above shows that there are no styles 、 Plain text in color .
Next , You can free your hands , Use Python Done automatically PDF、Word Document operation !
 Second: python+pytest+jenkins+gitee+allure is implemented using git drop-down code and local code (based on Windows)
Second: python+pytest+jenkins+gitee+allure is implemented using git drop-down code and local code (based on Windows)