The procedure is demonstrated as follows :
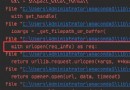
import requests
import re
def parse_page(url):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
response = requests.get(url , headers = headers)
text = response.text
titles = re.findall(r'<div\sclass="cont">.*?<b>(.*?)</b>' ,text , re.DOTALL) #re.DOTALL Give Way . Can match newline \n
authors = re.findall(r'<p class="source">.*?<a.*?>(.*?)</a>',text , re.DOTALL)
dynasties = re.findall(r'<p class="source".*?<a.*?>.*?<a.*?>(.*?)</a>', text ,re.DOTALL) # Because the dynasty was p The second under the label a label , So write two with two a label
contents_tags = re.findall(r'<div class="contson".*?>(.*?)</div>',text,re.DOTALL)
contents = []
for content in contents_tags:
x = re.sub(r'<.*?>' ,'',content)
contents.append(x.strip()) #.strip() Remove the line break
poems = []
for value in zip(titles,dynasties,authors,contents):
title,dynastie,author,content = value
poem = {
'title':title,
'author':author,
'dynastie':dynastie,
'content':content
}
poems.append(poem)
for poem in poems:
print(poem)
print('='*40)
def main():
url = 'https://www.gushiwen.cn/default_1.aspx'
for x in range(1,5):
url = 'https://www.gushiwen.cn/default_%s.aspx' %x
parse_page(url)
if __name__ == '__main__':
main()
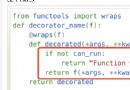
summary :re A regular expression is nothing more than a html All tags and web content are transformed into text for location extraction
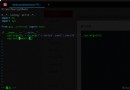
Used in the project zip The following procedure demonstrates :
#zip function :
a = [1,2]
b = [3,4]
c = zip(a,b)
c = [
(1,3),
(2,4)
]
value =(1,2,3)
a,b,c=value
a=1
b=2
c=3