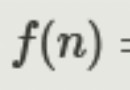import pandas as pd
import numpy as np
dates=pd.date_range('20130101',periods=6)// For from 20130101 Start For the next six days dates in
//DatetimeIndex(['2013-01-01', '2013-01-02', '2013-01-03', '2013-01-04',
'2013-01-05', '2013-01-06'],
dtype='datetime64[ns]', freq='D')
Be careful : It is superimposed by days
Yes dates Further treatment of
df=pd.DataFrame(np.arange(24).reshape(6,4),index=dates,columns=['A','B','C','D'])
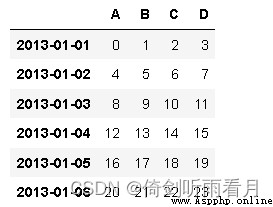
The result after indexing by period is shown in the figure .
The next step is to access the processed object .
print(df['A'])Or print(df.A) Are extracted by column , What is extracted here is A Column
2013-01-01 0
2013-01-02 4
2013-01-03 8
2013-01-04 12
2013-01-05 16
2013-01-06 20
Freq: D, Name: A, dtype: int32
print(df[0:3]) or print(df[20100101:20100106]) This slicing operation is to operate on the index , Is to extract the row to row
A B C D
2013-01-01 0 1 2 3
2013-01-02 4 5 6 7
2013-01-03 8 9 10 11
Higher end indexes :loc
print(df.loc['20130102'])
A 4
B 5
C 6
D 7
Name: 2013-01-02 00:00:00, dtype: int32
pfint(df.loc[:,['A']]) All of the line ,A Column
A
2013-01-01 0
2013-01-02 4
2013-01-03 8
2013-01-04 12
2013-01-05 16
2013-01-06 20
pfint(df.loc['20130102':,['A']]) 20130102 To the end ,A Column
A
2013-01-02 4
2013-01-03 8
2013-01-04 12
2013-01-05 16
2013-01-06 20
Higher end indexes :iloc (index local Abbreviation )
print(df.iloc[3,1]) // The number in the first column of the third row
print(df.iloc[3:5,1:3]) // Cooperate with slicing operation
print(df.iloc[[1,3,5],1:3]) // The first 1,3,5 OK, No 1-3 Column
Higher end indexes Can be loc and iloc Mixed use ix
print(df.ix[:3,['A','B']]) //0-3 That's ok (iloc) Of A,B Column (loc)
Higher end indexes :Boolean
print(df[df.A>8])// select df pass the civil examinations A Column to column ratio 8 Big data
Data preparation stage :
dates=pd.date_range('20130101',periods=6)
df=pd.DataFrame(np.arange(24).reshape(6,4),index=dates,columns=['A','B','C','D'])
A B C D
2013-01-01 0 1 2 3
2013-01-02 4 5 6 7
2013-01-03 8 9 10 11
2013-01-04 12 13 14 15
2013-01-05 16 17 18 19
2013-01-06 20 21 22 23
use iloc Access and modify :
df.iloc[2,2]=1111 // Notice the third row and the third column
A B C D
2013-01-01 0 1 2 3
2013-01-02 4 5 6 7
2013-01-03 8 9 1111 11
2013-01-04 12 13 14 15
2013-01-05 16 17 18 19
2013-01-06 20 21 22 23
df.loc['20130101','A']=2222
A B C D
2013-01-01 2222 1 2 3
2013-01-02 4 5 6 7
2013-01-03 8 9 1111 11
2013-01-04 12 13 14 15
2013-01-05 16 17 18 19
2013-01-06 20 21 22 23
df[df.A>8]=0 //A The column is greater than 8 All the numbers in that line of are set to zero
A B C D
2013-01-01 0 0 0 0
2013-01-02 4 5 6 7
2013-01-03 8 9 1111 11
2013-01-04 0 0 0 0
2013-01-05 0 0 0 0
2013-01-06 0 0 0 0
df.B[df.A>8]// A The column is greater than 8 Which line of B The number in the column is set to 0
Data preparation stage :
import pandas as pd
import numpy as np
dates=pd.date_range('20130101',periods=6)// For from 20130101 Start For the next six days dates in
//DatetimeIndex(['2013-01-01', '2013-01-02', '2013-01-03', '2013-01-04',
'2013-01-05', '2013-01-06'],
dtype='datetime64[ns]', freq='D')
Be careful : It is superimposed by days
Yes dates Further treatment of
df=pd.DataFrame(np.arange(24).reshape(6,4),index=dates,columns=['A','B','C','D'])
Add an empty column
df['E']=np.nan
Add columns with initial values
df['F']=pd.Series([1,2,3,4,5,6],index=pd.date_range('20130101',periods=6))
Data preparation stage :
import pandas as pd
import numpy as np
dates=pd.date_range('20130101',periods=6)// For from 20130101 Start For the next six days dates in
//DatetimeIndex(['2013-01-01', '2013-01-02', '2013-01-03', '2013-01-04',
'2013-01-05', '2013-01-06'],
dtype='datetime64[ns]', freq='D')
Be careful : It is superimposed by days
Yes dates Further treatment of
df=pd.DataFrame(np.arange(24).reshape(6,4),index=dates,columns=['A','B','C','D'])
Simulate data loss
df.iloc[0,1]=np.nan
df.iloc[1,2]=np.nan
programme 1: Discard data
pfint(df.dropna(axis=0 or 1,how='any' or 'all')) axis be equal to 0 When Search from top to bottom ,how be equal to any Represents that there is nan The line of is deleted immediately ,all It means only this line is full of nan I only deleted this line when
programme 2: Fill in the data
print(df.fillna(value=0))
programme 3: Check if it is empty
print(df.isnull())
Or I want to know if there is any space in my pile of data
print(np.any(df.isnull()==True)
import pandas as pd
import numpy as np
Read in the data ( It is best to csv Format )
data=pd.read_csv(' File path ')
Save the data
data.to_ File format (' File path ')