操作系統:Ubuntu 20.04
Spark版本:3.2.1
Hadoop 版本:3.3.1
Python 版本:3.8.10
Java 版本:1.8.202
from pyspark import SparkConf, SparkContext
conf = SparkConf().setAppName("WordCount").setMaster("local")
sc = SparkContext(conf=conf)
inputFile = "hdfs://localhost:9000/user/way/word.txt"
textFile = sc.textFile(inputFile)
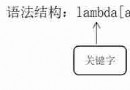
wordCount = textFile.flatMap(lambda line : line.split(" ")).map(lambda word : (word, 1)).reduceByKey(lambda a, b : a + b)
wordCount.foreach(print)
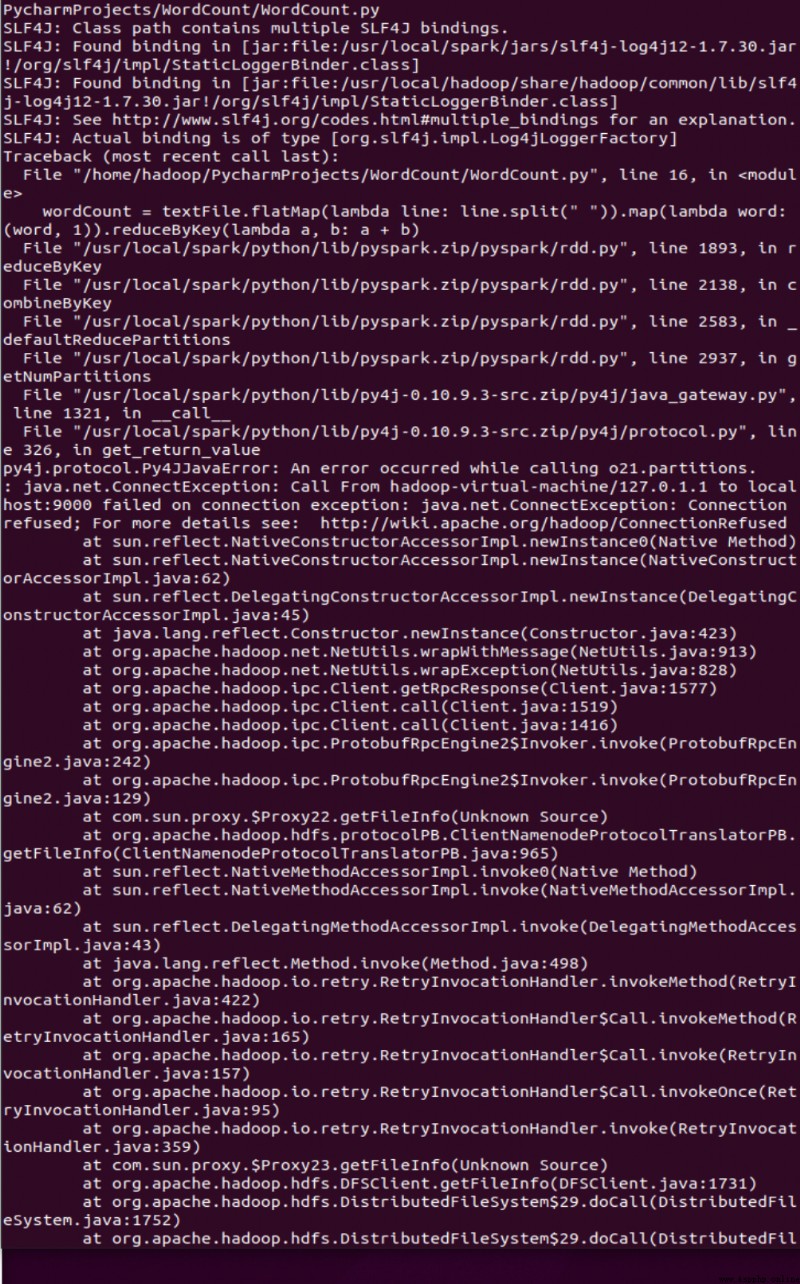
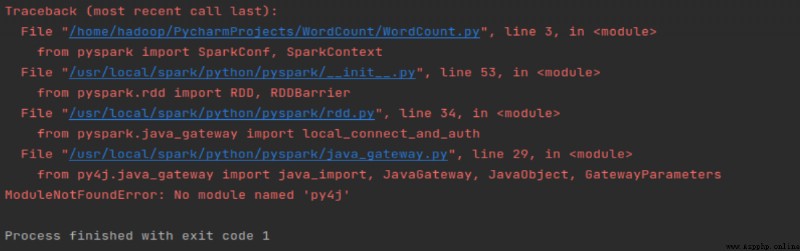
Process finished with exit code 1
我以為是py4j文件目錄有問題,後來發現不是;後來看pycharm報錯是導入包文件的問題可能是版本兼容性問題
正常運行代碼