code / Decoding is essentially a mapping
character a use ascii The encoding is 65, Stored in the computer as 00110101.a Need to decode to 00110101, Can be used by the computer .
code : The correspondence between real characters and binary strings , Real characters → Binary string
decode : The correspondence between binary string and real character , Binary string → Real characters
Such as :
UTF-8 --> decode decode --> Unicode
Unicode --> encode code --> GBK / UTF-8 etc.
ASCII With 1 byte 8 individual bit Bit represents a character , The first is all 0, The character set represented is obviously not enough
unicode The coding system is designed to express any language , To prevent redundancy on storage ( such as , Corresponding ascii The part of the code ), It uses variable length coding , But variable length coding makes decoding difficult , It can't be judged that several bytes represent a character
UTF-8 Is aimed at unicode A prefix for variable length coding design , According to the prefix, it can be judged that several bytes represent a character
Python Default encoding in
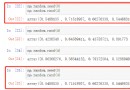
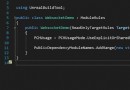
str = ' Hello ' # b'\xe4\xbd\xa0\xe5\xa5\xbd' gbk:b'\xc4\xe3\xba\xc3'
str = 'abc' # b'abc'
str = 'นั่ง' # b'\xe0\xb8\x99\xe0\xb8\xb1\xe0\xb9\x88\xe0\xb8\x87'
str = 'นั่' # b'\xe0\xb8\x99\xe0\xb8\xb1\xe0\xb9\x88'
# str = 2 # 'int' object has no attribute 'encode'
str = '*' # b'*'
a = str.encode('UTF-8')
a = str.encode('gbk')
print(a)
print(type(a)) # <class 'bytes'>
Mainly in the use of raw_unicode_escape code
str = '\xe5\x90\x8d\xe7\xa7\xb0'
str_b = str.encode("raw_unicode_escape") # b'\xe5\x90\x8d\xe7\xa7\xb0'
str_origin = str_b.decode("utf-8") # ' name '
Use urllib library
Reference resources : https://www.cnblogs.com/miaoxiaochao/p/13705936.html
str = ' Hello '
a = urllib.parse.quote(str)
print(a) # %E4%BD%A0%E5%A5%BD
b = urllib.parse.unquote(a) # Hello
b = b''
b += b'a'
b += b' b'
print(b) b'a b'
print (b.decode('utf-8')) # a b
Yizhi 2022-06-24( 5、 ... and )