操作
df[bool_vec]
數據選擇,即按照一定的條件對數據進行篩選,通過Pandas提供的方法可以模擬Excel對數據的篩選操作,可靈活應對各種數據的查詢需求
import pandas as pd
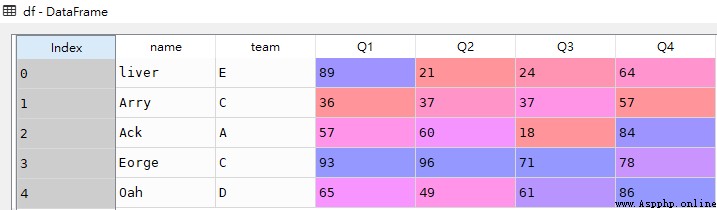
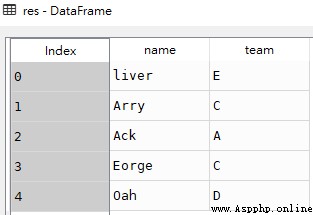
df = pd.DataFrame([['liver','E',89,21,24,64],
['Arry','C',36,37,37,57],
['Ack','A',57,60,18,84],
['Eorge','C',93,96,71,78],
['Oah','D',65,49,61,86]
],
columns = ['name','team','Q1','Q2','Q3','Q4'])
# 以下兩種方法會返回'name'列的數據,得到的數據類型為Series
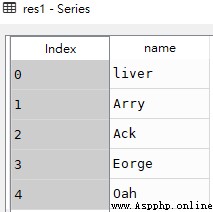
res1 = df['name']
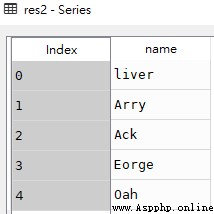
res2 = df.name
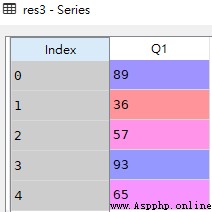
res3 = df.Q1
type(res3) # pandas.core.series.Series
#--------------------------------------------------------------------
print(res1 == res2)
# 輸出結果:
# 0 True
# 1 True
# 2 True
# 3 True
# 4 True
# Name: name, dtype: bool
#--------------------------------------------------------------------
df
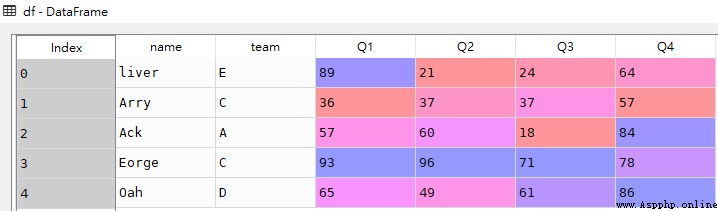 res1
res1
res2
res3
我們可以像列表那樣利用切片功能選擇部分行的數據(索引值從0開始),但是不支持僅索引一條數據,需要注意的是,Pandas使用切片的邏輯與Python列表的邏輯一樣,不包括右邊的索引值
import pandas as pd
df = pd.DataFrame([['liver','E',89,21,24,64],
['Arry','C',36,37,37,57],
['Ack','A',57,60,18,84],
['Eorge','C',93,96,71,78],
['Oah','D',65,49,61,86]
],
columns = ['name','team','Q1','Q2','Q3','Q4'])
# 前兩行數據
res1 = df[:2]
# 後兩行數據
res2 = df[3:]
# 所有數據(不推薦)
res3 = df[:]
# 按步長取
res4 = df[:5:2]
# 反轉順序
res5 = df[::-1]
# 報錯
res6 = df[2]df
res1

res2

res3
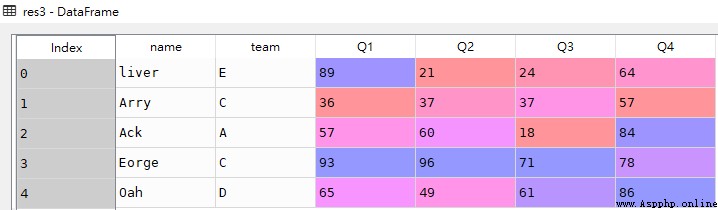
res4
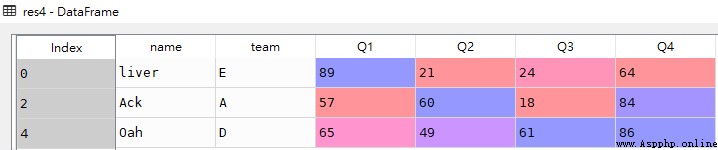
res5
如果切片裡是一個列名組成的列表(形式: df[['列名','列名',...]]),則可以篩選出多列數據
import pandas as pd
df = pd.DataFrame([['liver','E',89,21,24,64],
['Arry','C',36,37,37,57],
['Ack','A',57,60,18,84],
['Eorge','C',93,96,71,78],
['Oah','D',65,49,61,86]
],
columns = ['name','team','Q1','Q2','Q3','Q4'])
# 篩選'name','team'兩列數據
res = df[['name','team']]
# 需要區別的是,如果只有一列(格式: df[['列名']]),則會是一個DataFrame:
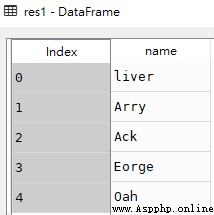
res1 = df[['name']]
type(res1) # pandas.core.frame.DataFrame
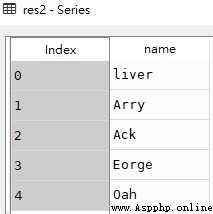
res2 = df['name']
type(res2) # pandas.core.series.Seriesdf
res
res1
res2
loc: works on labels in the index
按軸標簽.loc https://blog.csdn.net/Hudas/article/details/123096447?spm=1001.2014.3001.5502
https://blog.csdn.net/Hudas/article/details/123096447?spm=1001.2014.3001.5502
iloc: works on the positions in the index(so it only takes integers)
按數字索引.ilochttps://blog.csdn.net/Hudas/article/details/123096447?spm=1001.2014.3001.5502
import pandas as pd
df = pd.DataFrame([['liver','E',89,21,24,64],
['Arry','C',36,37,37,57],
['Ack','A',57,60,18,84],
['Eorge','C',93,96,71,78],
['Oah','D',65,49,61,86]
],
columns = ['name','team','Q1','Q2','Q3','Q4'])
# Q1等於36
res1 = df[df['Q1'] == 36]
# Q1不等於36
res2 = df[~(df['Q1'] == 36)]
# 姓名為'Eorge'
res3 = df[df['name'] == 'Eorge']
# 篩選Q1大於Q2的行記錄
res4 = df[df.Q1 > df.Q2]df
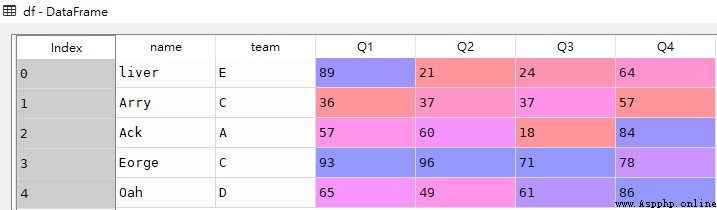
res1

res2
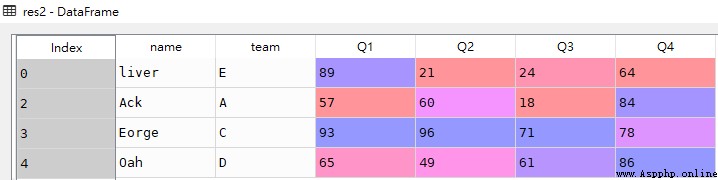
res3

res4