iloc和loc的區別
1.loc是基於索引值的,切片是左閉右閉的
2.iloc是基於位置的,切片是左閉右開的
.loc的格式是df.loc[<行表達式>,<列表達式>],如果<列表達式>不傳,將返回所有列
Series僅支持<行表達式>進行索引的部分
.loc操作通過索引和列的條件篩選出數據,如果僅返回一條數據,則該數據類型為Series
以下示例為單個索引
import pandas as pd
df = pd.DataFrame([['liver','E',89,21,24,64],
['Arry','C',36,37,37,57],
['Ack','A',57,60,18,84],
['Eorge','C',93,96,71,78],
['Oah','D',65,49,61,86]
],
columns = ['name','team','Q1','Q2','Q3','Q4'])
# 選擇索引為0的行
res1 = df.loc[0]
# 選擇索引為4的行
res2 = df.loc[4]
# 如果索引是字符,需要加引號
# 索引為name
# 選擇索引name為Ack的行
res3 = df.set_index('name').loc['Ack']
df
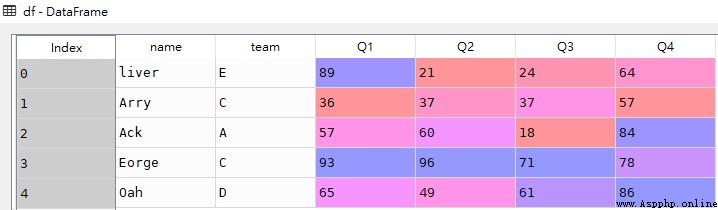
res1
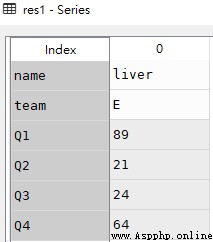
res2
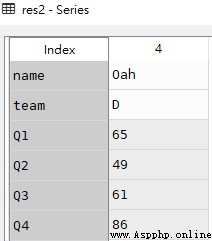
res3
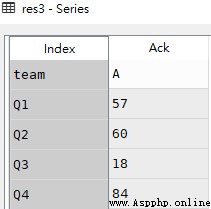
以下示例為列表組成的索引
import pandas as pd
df = pd.DataFrame([['liver','E',89,21,24,64],
['Arry','C',36,37,37,57],
['Ack','A',57,60,18,84],
['Eorge','C',93,96,71,78],
['Oah','D',65,49,61,86]
],
columns = ['name','team','Q1','Q2','Q3','Q4'])
# 指定索引為0,2,4的行
res1 = df.loc[[0,2,4]]
# 索引設置為name,兩位學生
res2 = df.set_index('name').loc[['Arry','Ack']]df

res1
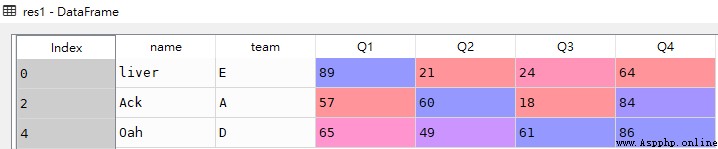
res2
以下示例為帶標簽的切片(包括起始和停止)
import pandas as pd
df = pd.DataFrame([['liver','E',89,21,24,64],
['Arry','C',36,37,37,57],
['Ack','A',57,60,18,84],
['Eorge','C',93,96,71,78],
['Oah','D',65,49,61,86]
],
columns = ['name','team','Q1','Q2','Q3','Q4'])
# 索引切片,代表0~3行,包括3
res1 = df.loc[0:3]
res2 = df.loc[:]df
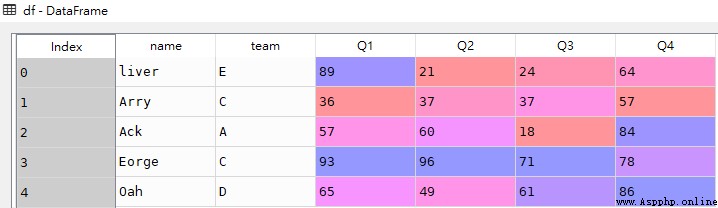
res1
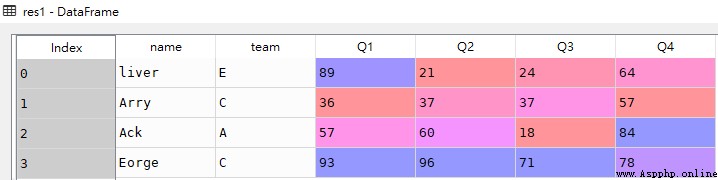
res2
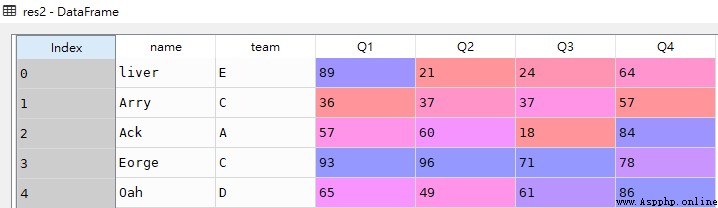
附帶列篩選,必須有行篩選
# 前3行,name和Q2兩列
res3 = df.loc[0:2,['name','Q2']]
# 所有列,Q1和Q2兩列
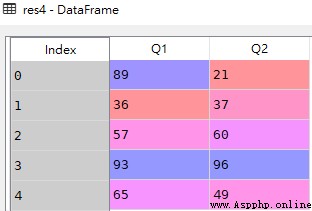
res4 = df.loc[:,['Q1','Q2']]
# 0~2行,Q1後邊所有列
res5 = df.loc[:2,'Q1':]
# 所有內容
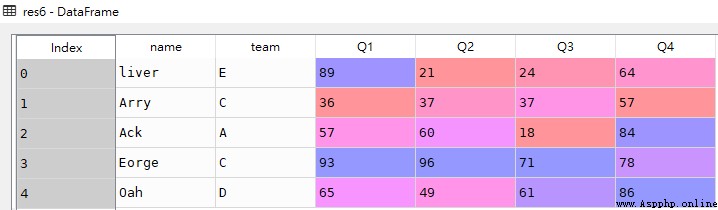
res6 = df.loc[:,:]res3
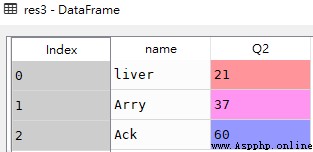
res4
res5

res6
提示
.loc中的表達式支持條件表達式,可以按條件查詢數據
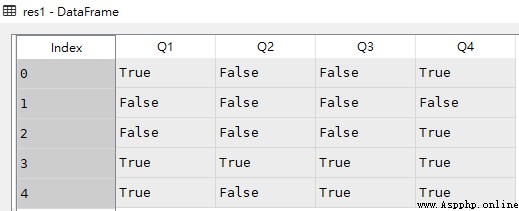
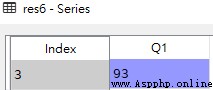
import pandas as pd df = pd.DataFrame([['liver','E',89,21,24,64], ['Arry','C',36,37,37,57], ['Ack','A',57,60,18,84], ['Eorge','C',93,96,71,78], ['Oah','D',65,49,61,86] ], columns = ['name','team','Q1','Q2','Q3','Q4']) # 判斷數值部分的所有值是否大於60 res1 = df.loc[:,'Q1':'Q4'] > 60 # Q1大於90,顯示Q1及其後所有列 res2 = df.loc[df['Q1'] > 90,'Q1':] # and關系 res3 = df.loc[(df.Q1 > 50) & (df.Q2 < 65)] # or關系 res4 = df.loc[(df.Q1 > 90) | (df.Q3 < 30)] # Q1等於36 # res5 = df.loc[df.Q1 == 36] res5 = df.loc[df['Q1'] == 36] # Q1大於90,只顯示Q1 res6 = df.loc[df['Q1'] > 90,'Q1']df
res1
res2
res3
res4
res5
res6
需要注意在進行或(|)、與(&)、非(~)運算時,各個獨立邏輯表達式需要用括號括起來
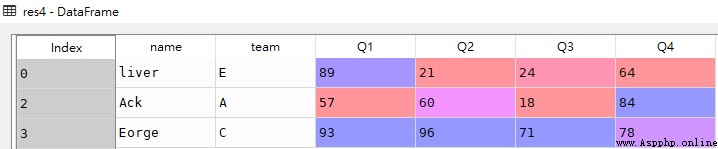
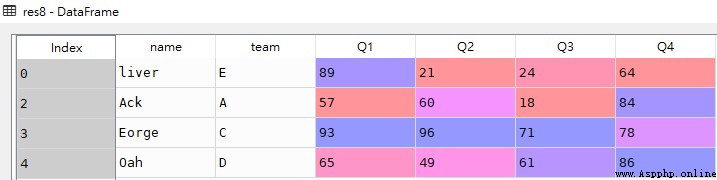
# Q1、Q2成績都超過50分的行記錄 res7 = df[(df.loc[:,['Q1','Q2']] > 50).all(1)] # Q1、Q2成績至少有一個超過50分的行記錄 res8 = df[(df.loc[:,['Q1','Q2']] > 50).any(1)]res7
res8
上述兩例對兩個列整體先做邏輯計算得到一個兩列的布爾序列,然後用all和any在行方向上做邏輯運算
all和any可以傳入axis參數值用於指定判斷方向,默認0為列方向,1為行方向
.iloc的格式是df.iloc[<行表達式>,<列表達式>]
與loc[]可以使用索引和列的名稱不同,iloc[]使用數字索引(行和列的0~n索引)進行數據篩選,意味著iloc[]兩個表達式只支持數字切片形式,其他方面和loc[]是相同的
import pandas as pd
df = pd.DataFrame([['liver','E',89,21,24,64],
['Arry','C',36,37,37,57],
['Ack','A',57,60,18,84],
['Eorge','C',93,96,71,78],
['Oah','D',65,49,61,86]
],
columns = ['name','team','Q1','Q2','Q3','Q4'])
# 前三行(左閉右開)
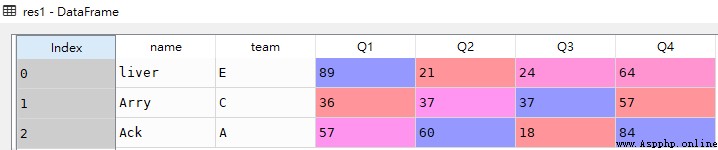
res1 = df.iloc[:3]
# 所有數據
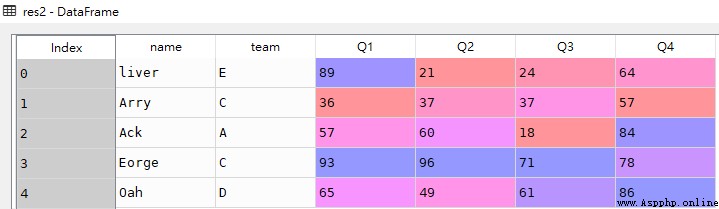
res2 = df.iloc[:]
# 步長為2
res3 = df.iloc[0::2]
# 返回0~2行,前兩列
res4 = df.iloc[:3,[0,1]]
# 返回0~2行,所有列
res5 = df.iloc[:3,:]
# 返回0~2行,從右往左第三列以左的所有列
res6 = df.iloc[:3,:-2]
# 獲取name字段前3個值
res7 = df['name'].iloc[:3]df
res1
res2
res3
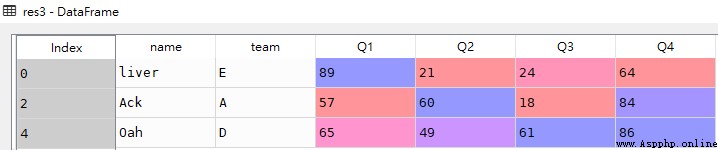
res4
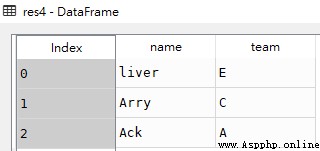
res5
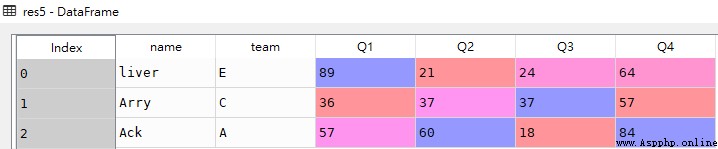
res6
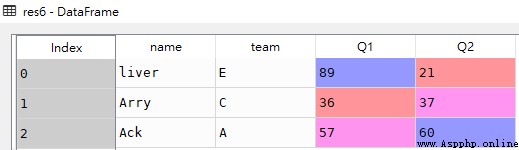
res7
提示
.iloc中的表達式支持條件表達式,可以按條件查詢數據,用法和.loc是相似的,可參考上述.loc按條件查詢數據案例