One 、 Use pip management Python package
1.pip install Install the specified package
2.pip uninstall Uninstall the specified package
3.pip list Show installed packages
4.pip freeze Display installed packages and versions
[ notes ]: modify pip Download source
- Alibaba cloud :https://mirrors.aliyun.com/pypi/simple/
- douban :http://pypi.douban.com/simple/( recommend )
- Tsinghua University :https://pypi.tuna.tsinghua.edu.cn/simple/
- China University of science and technology :https://pypi.mirrors.ustc.edu.cn/simple/
Two 、Python File access mode 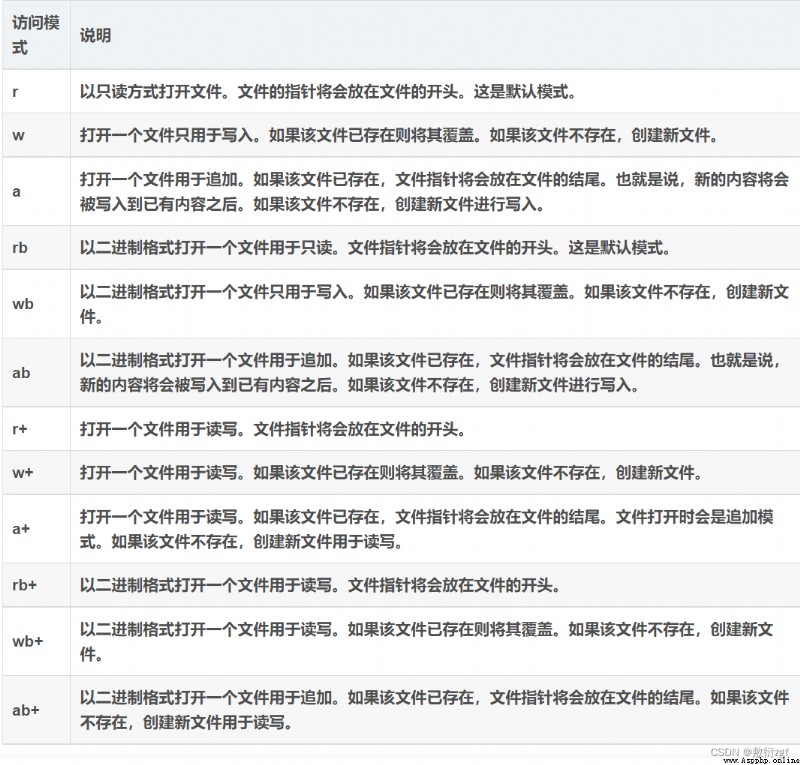
3、 ... and 、 File serialization and deserialization
1. serialize
(1)dumps Use
import json
fp = open('test.txt','w')
name_list = ['zs','ls']
# serialize
#1.json.dumps() take Python The object becomes json The character sequence of
names = json.dumps(name_list)
print(type(names))
fp.write(names)
fp.close()
(2)dump Use
While converting an object to a string , Specify a file object to write the converted String to the file
import json
fp = open('test.txt','w')
name_list = ['zs','ls']
json.dump(name_list,fp)
fp.close()
2. Deserialization
(1)loads Use
## Deserialization
# take json The string becomes a Python object
fp = open('test.txt','r')
content = fp.read()
# print(content)
import json
# take json String becomes python object
resoult = json.loads(content)
print(resoult)
print(type(resoult))
(2)load Use
fp = open('test.txt','r')
import json
resoult = json.load(fp)
print(resoult)
print(type(resoult))
fp.close()
Four 、 Internet crawler
What is a reptile :1. Through a program , according to Url Do web crawling , Get useful information ;2. Use the program to simulate the browser , To send a request to the server , Get response information .
5、 ... and 、urllib Basic use of
1. Get all the source code of Baidu web page
# Use urllib Get the source code of Baidu home page
import urllib.request
# 1. Definition url
url = 'http://www.baidu.com'
# 2. Simulate the browser to send a request to the server
response = urllib.request.urlopen(url)
# 3. Get the source code of the page in the response
# read() Method Returns a binary number in bytes
# Convert binary numbers to strings
# Binary system ——》 character string decode decode(' Encoding format ')
content = response.read().decode('utf-8')
# 4. Print the content
print(content)
2. One type and six methods
import urllib.request
url = 'http://www.baidu.com'
# Simulate the browser to send a request to the server
response = urllib.request.urlopen(url)
# One type and six methods
# response yes HTTPResponse type
# print(type(response))
# One 、read() Method
# 1. Read in one byte
content = response.read()
print(content)
# 2. read-only X Bytes read(X)
content = response.read(5)
print(content)
# Two 、readline() Method Read a line
content = response.readline()
print(content)
# 3、 ... and 、readlines() Method Read in units of behavior , Until the end of reading
content = response.readlines()
print(content)
# Four 、getcode() Method
# Return status code , if 200 The logic is correct
print(response.getcode())
# 5、 ... and 、geturl() Method
# return url Address
print(response.geturl())
# 6、 ... and 、getheaders() Method
# Get status information
print(response.getheaders())
3.urllib Download resources
import urllib.request
# 1. Download Web page
url_page = 'http://www.baidu.com'
# url Represents the download path filename Represents the name of the document
# stay python You can write the name of the variable in , You can also write values
urllib.request.urlretrieve(url_page,'baidu.html')
# 2. Download the pictures
url_img = 'https://tse1-mm.cn.bing.net/th/id/OIP-C.zgBWxADXwdw-seRK5cLy-wHaMR?w=194&h=321&c=7&r=0&o=5&dpr=1.5&pid=1.7' urllib.request.urlretrieve(url=url_img,filename='img.jpg')
# 3. Download Video
url_video = 'https://kn-cdn.codemao.cn/creation/lesson/4_kitten_public/lesson01.mp4'
urllib.request.urlretrieve(url_video,'video.mp4')