operation
df[bool_vec]
Data selection , That is to filter the data according to certain conditions , adopt Pandas The method provided can simulate Excel Filter data , It can flexibly meet the query requirements of various data
import pandas as pd
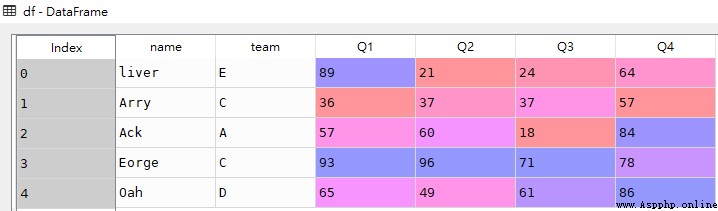
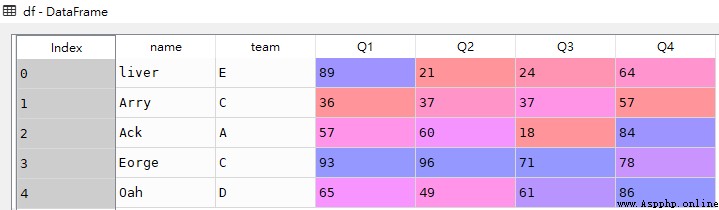
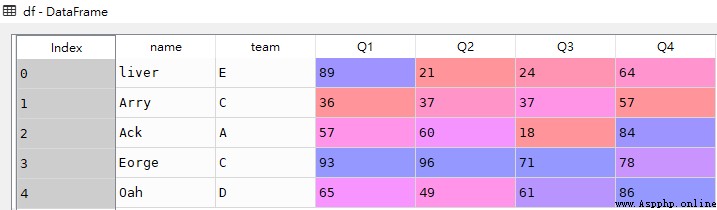
df = pd.DataFrame([['liver','E',89,21,24,64],
['Arry','C',36,37,37,57],
['Ack','A',57,60,18,84],
['Eorge','C',93,96,71,78],
['Oah','D',65,49,61,86]
],
columns = ['name','team','Q1','Q2','Q3','Q4'])
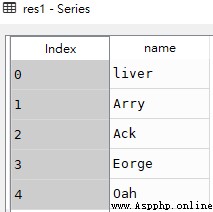
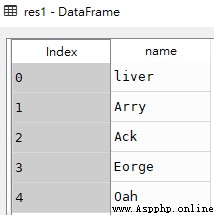
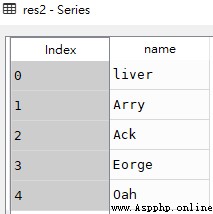
# The following two methods return 'name' Columns of data , The data type obtained is Series
res1 = df['name']
res2 = df.name
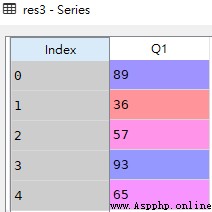
res3 = df.Q1
type(res3) # pandas.core.series.Series
#--------------------------------------------------------------------
print(res1 == res2)
# Output results :
# 0 True
# 1 True
# 2 True
# 3 True
# 4 True
# Name: name, dtype: bool
#--------------------------------------------------------------------
df
 res1
res1
res2
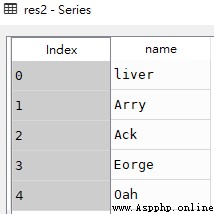
res3
We can use slicing like a list Select some rows The data of ( Index value from 0 Start ), However, it is not supported to index only one piece of data , It should be noted that ,Pandas Use sliced logic and Python The logic of the list is the same , The index value on the right is not included
import pandas as pd
df = pd.DataFrame([['liver','E',89,21,24,64],
['Arry','C',36,37,37,57],
['Ack','A',57,60,18,84],
['Eorge','C',93,96,71,78],
['Oah','D',65,49,61,86]
],
columns = ['name','team','Q1','Q2','Q3','Q4'])
# The first two lines of data
res1 = df[:2]
# The last two lines of data
res2 = df[3:]
# All the data ( Not recommended )
res3 = df[:]
# Take... In steps
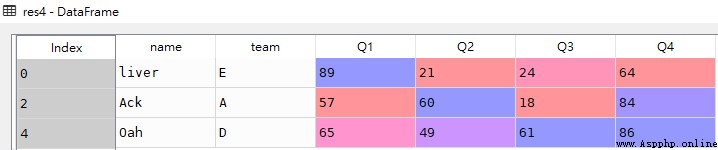
res4 = df[:5:2]
# Inversion order
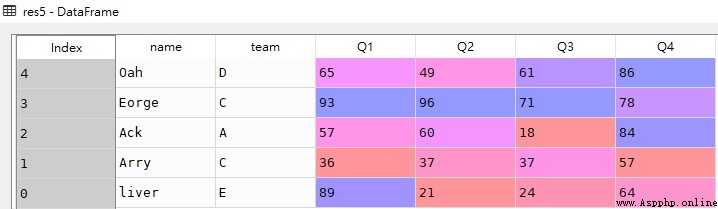
res5 = df[::-1]
# Report errors
res6 = df[2]df
res1

res2

res3

res4
res5
If there is a list of column names in the slice ( form : df[[' Name ',' Name ',...]]), You can filter out multiple columns of data
import pandas as pd
df = pd.DataFrame([['liver','E',89,21,24,64],
['Arry','C',36,37,37,57],
['Ack','A',57,60,18,84],
['Eorge','C',93,96,71,78],
['Oah','D',65,49,61,86]
],
columns = ['name','team','Q1','Q2','Q3','Q4'])
# Screening 'name','team' Two column data
res = df[['name','team']]
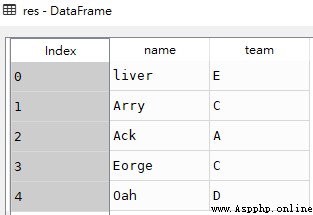
# The difference is , If there is only one column ( Format : df[[' Name ']]), It would be a DataFrame:
res1 = df[['name']]
type(res1) # pandas.core.frame.DataFrame
res2 = df['name']
type(res2) # pandas.core.series.Seriesdf
res
res1
res2
loc: works on labels in the index
By axis label .loc https://blog.csdn.net/Hudas/article/details/123096447?spm=1001.2014.3001.5502
https://blog.csdn.net/Hudas/article/details/123096447?spm=1001.2014.3001.5502
iloc: works on the positions in the index(so it only takes integers)
Index by number .ilochttps://blog.csdn.net/Hudas/article/details/123096447?spm=1001.2014.3001.5502
import pandas as pd
df = pd.DataFrame([['liver','E',89,21,24,64],
['Arry','C',36,37,37,57],
['Ack','A',57,60,18,84],
['Eorge','C',93,96,71,78],
['Oah','D',65,49,61,86]
],
columns = ['name','team','Q1','Q2','Q3','Q4'])
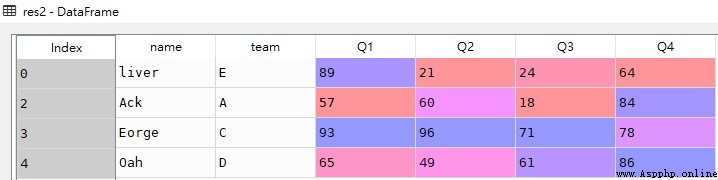
# Q1 be equal to 36
res1 = df[df['Q1'] == 36]
# Q1 It's not equal to 36
res2 = df[~(df['Q1'] == 36)]
# The name is 'Eorge'
res3 = df[df['name'] == 'Eorge']
# Screening Q1 Greater than Q2 The line record of
res4 = df[df.Q1 > df.Q2]df
res1
res2
res3
res4