iloc and loc The difference between
1.loc Is based on index values , The slice is left closed and right closed
2.iloc It's location-based , The slice is left closed and right open
.loc The format is df.loc[< Row expression >,< List expression >], If < List expression > Don't pass on , All columns will be returned
Series Support only < Row expression > Indexed section
.loc The operation passes Index and column conditions Filter out the data , If only one piece of data is returned , Then the data type is Series
The following example is Single index
import pandas as pd
df = pd.DataFrame([['liver','E',89,21,24,64],
['Arry','C',36,37,37,57],
['Ack','A',57,60,18,84],
['Eorge','C',93,96,71,78],
['Oah','D',65,49,61,86]
],
columns = ['name','team','Q1','Q2','Q3','Q4'])
# Select index as 0 The line of
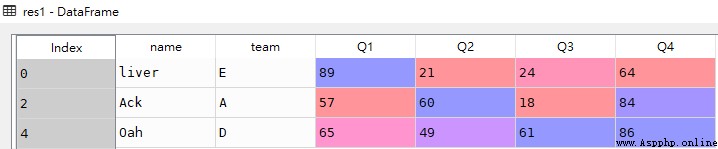
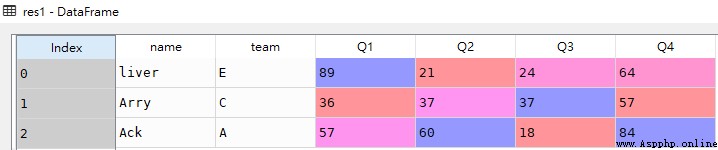
res1 = df.loc[0]
# Select index as 4 The line of
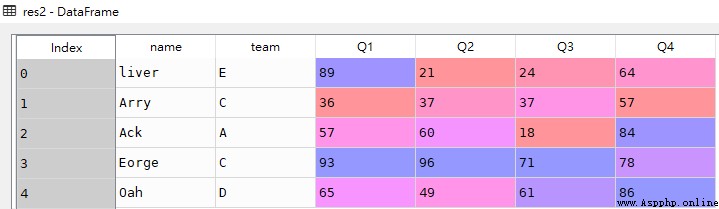
res2 = df.loc[4]
# If the index is a character , Quotes required
# The index for name
# Choose the index name by Ack The line of
res3 = df.set_index('name').loc['Ack']
df

res1

res2
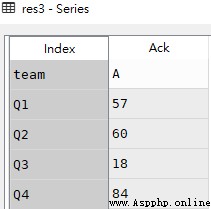
res3
The following example is An index of lists
import pandas as pd
df = pd.DataFrame([['liver','E',89,21,24,64],
['Arry','C',36,37,37,57],
['Ack','A',57,60,18,84],
['Eorge','C',93,96,71,78],
['Oah','D',65,49,61,86]
],
columns = ['name','team','Q1','Q2','Q3','Q4'])
# Specify the index as 0,2,4 The line of
res1 = df.loc[[0,2,4]]
# The index is set to name, Two students
res2 = df.set_index('name').loc[['Arry','Ack']]df

res1
res2
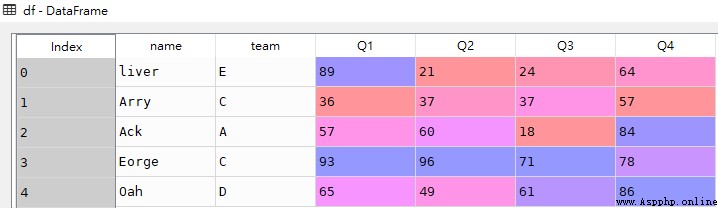
The following example is Slice with label ( Including start and stop )
import pandas as pd
df = pd.DataFrame([['liver','E',89,21,24,64],
['Arry','C',36,37,37,57],
['Ack','A',57,60,18,84],
['Eorge','C',93,96,71,78],
['Oah','D',65,49,61,86]
],
columns = ['name','team','Q1','Q2','Q3','Q4'])
# Index slice , representative 0~3 That's ok , Include 3
res1 = df.loc[0:3]
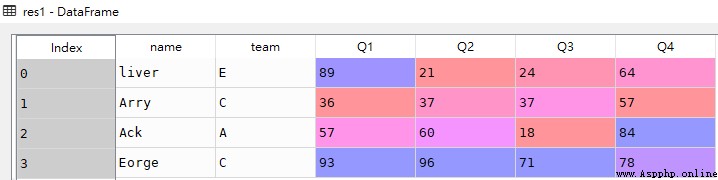
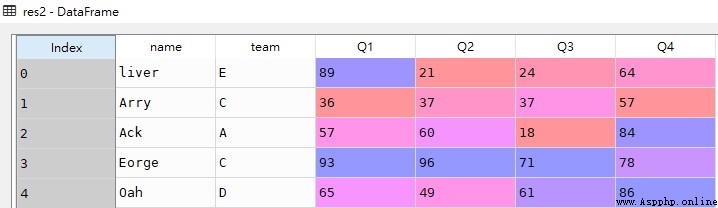
res2 = df.loc[:]df
res1
res2
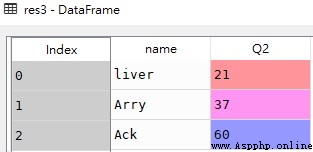
With column filter , There must be a row filter
# front 3 That's ok ,name and Q2 Two
res3 = df.loc[0:2,['name','Q2']]
# All columns ,Q1 and Q2 Two
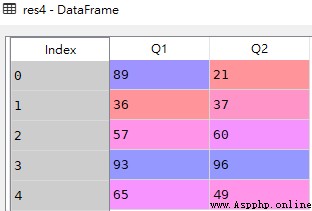
res4 = df.loc[:,['Q1','Q2']]
# 0~2 That's ok ,Q1 All columns behind
res5 = df.loc[:2,'Q1':]
# All contents
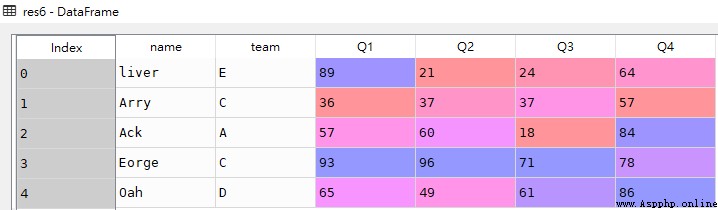
res6 = df.loc[:,:]res3
res4
res5
res6
Tips
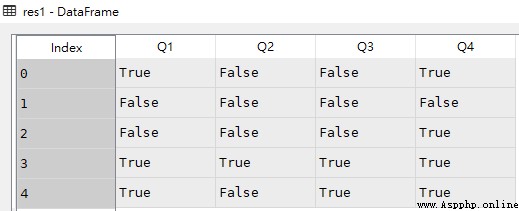
.loc The expression in supports conditional expressions , You can query data by criteria
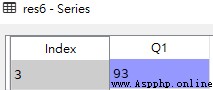
import pandas as pd df = pd.DataFrame([['liver','E',89,21,24,64], ['Arry','C',36,37,37,57], ['Ack','A',57,60,18,84], ['Eorge','C',93,96,71,78], ['Oah','D',65,49,61,86] ], columns = ['name','team','Q1','Q2','Q3','Q4']) # Judge whether all values in the value part are greater than 60 res1 = df.loc[:,'Q1':'Q4'] > 60 # Q1 Greater than 90, Show Q1 And all subsequent columns res2 = df.loc[df['Q1'] > 90,'Q1':] # and Relationship res3 = df.loc[(df.Q1 > 50) & (df.Q2 < 65)] # or Relationship res4 = df.loc[(df.Q1 > 90) | (df.Q3 < 30)] # Q1 be equal to 36 # res5 = df.loc[df.Q1 == 36] res5 = df.loc[df['Q1'] == 36] # Q1 Greater than 90, Display only Q1 res6 = df.loc[df['Q1'] > 90,'Q1']df
res1
res2
res3
res4
res5
res6
Need to pay attention to in progress or (|)、 And (&)、 Not (~) Operation time , Each independent logical expression needs to be enclosed in parentheses
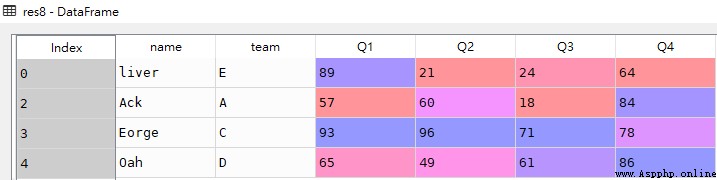
# Q1、Q2 The results are all better than 50 Separate line records res7 = df[(df.loc[:,['Q1','Q2']] > 50).all(1)] # Q1、Q2 At least one of the scores exceeds 50 Separate line records res8 = df[(df.loc[:,['Q1','Q2']] > 50).any(1)]res7
res8
In the above two examples, a two column Boolean sequence is obtained by performing logical calculation on the two columns as a whole , And then use all and any stay Line direction Do logical operations on
all and any You can pass in axis The parameter value is used to specify the judgment direction , Default 0 For column direction ,1 In the direction of the line
.iloc The format is df.iloc[< Row expression >,< List expression >]
And loc[] You can use different names for indexes and columns ,iloc[] Use numeric indexes ( Row and column 0~n Indexes ) Data filtering , signify iloc[] The two expressions only support the numeric slice form , Other aspects and loc[] It's the same
import pandas as pd
df = pd.DataFrame([['liver','E',89,21,24,64],
['Arry','C',36,37,37,57],
['Ack','A',57,60,18,84],
['Eorge','C',93,96,71,78],
['Oah','D',65,49,61,86]
],
columns = ['name','team','Q1','Q2','Q3','Q4'])
# The first three rows ( Left closed right away )
res1 = df.iloc[:3]
# All the data
res2 = df.iloc[:]
# In steps of 2
res3 = df.iloc[0::2]
# return 0~2 That's ok , The first two columns
res4 = df.iloc[:3,[0,1]]
# return 0~2 That's ok , All columns
res5 = df.iloc[:3,:]
# return 0~2 That's ok , All columns left of the third column from right to left
res6 = df.iloc[:3,:-2]
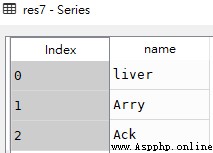
# obtain name Before fields 3 It's worth
res7 = df['name'].iloc[:3]df
res1
res2
res3
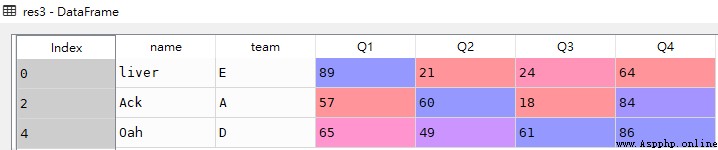
res4
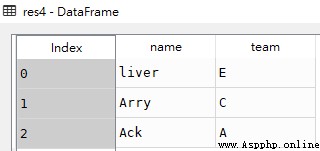
res5
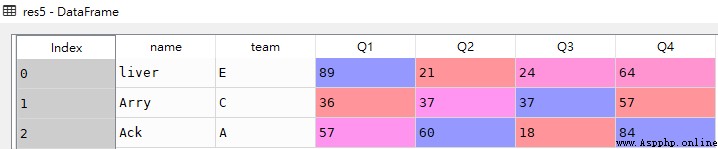
res6
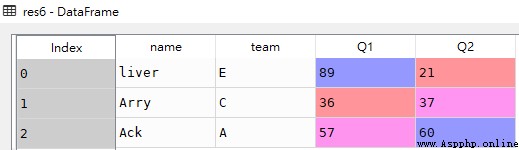
res7
Tips
.iloc The expression in supports conditional expressions , You can query data by criteria , Usage and .loc Is similar to that of , Refer to the above .loc Query data cases by criteria
 [Python basics 011] detailed understanding of all built-in functions (Part 2)
[Python basics 011] detailed understanding of all built-in functions (Part 2)
Catalog Preface One 、exec an
 Python crawler series little red book account authorization automatically publishes note videos
Python crawler series little red book account authorization automatically publishes note videos
Python Crawler series little r