一、使用pip管理Python包
1.pip install 安裝指定包
2.pip uninstall 卸載指定包
3.pip list 顯示已經安裝的包
4.pip freeze顯示已經安裝的包以及版本
[注]:修改pip下載源
- 阿裡雲:https://mirrors.aliyun.com/pypi/simple/
- 豆瓣:http://pypi.douban.com/simple/(推薦)
- 清華大學:https://pypi.tuna.tsinghua.edu.cn/simple/
- 中科大:https://pypi.mirrors.ustc.edu.cn/simple/
二、Python文件訪問模式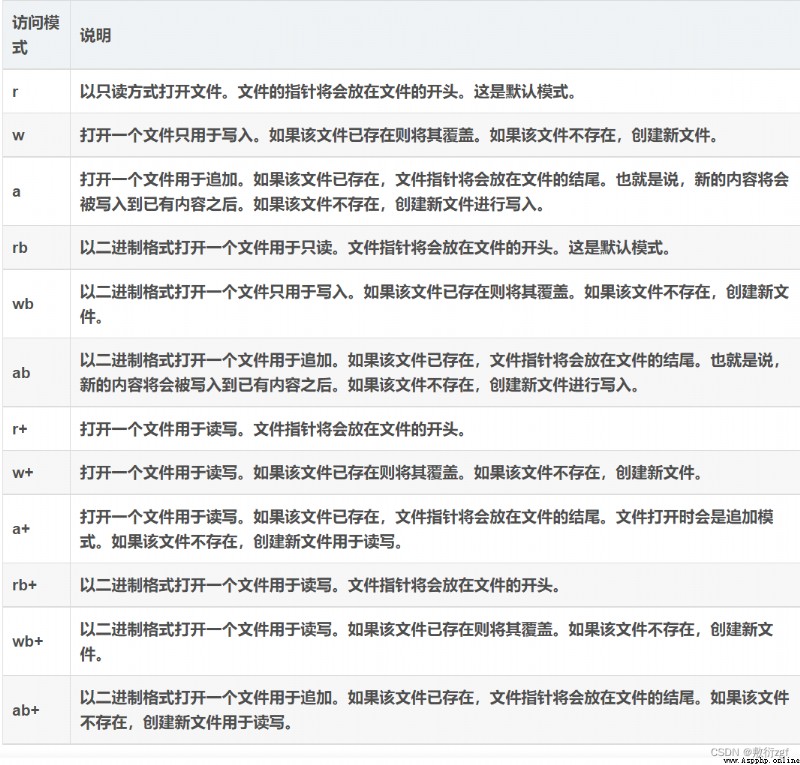
三、文件序列化與反序列化
1.序列化
(1)dumps的使用
import json
fp = open('test.txt','w')
name_list = ['zs','ls']
#序列化
#1.json.dumps()將Python對象變成json的字符序列
names = json.dumps(name_list)
print(type(names))
fp.write(names)
fp.close()
(2)dump的使用
在將對象轉換為字符串的同時,指定一個文件對象將轉換後的字符串寫入到文件中
import json
fp = open('test.txt','w')
name_list = ['zs','ls']
json.dump(name_list,fp)
fp.close()
2.反序列化
(1)loads的使用
## 反序列化
# 將json字符串變成一個Python對象
fp = open('test.txt','r')
content = fp.read()
# print(content)
import json
# 將json字符串變成python對象
resoult = json.loads(content)
print(resoult)
print(type(resoult))
(2)load的使用
fp = open('test.txt','r')
import json
resoult = json.load(fp)
print(resoult)
print(type(resoult))
fp.close()
四、互聯網爬蟲
啥是爬蟲:1.通過一段程序,根據Url進行網頁爬取,獲取有用信息;2.使用程序模擬浏覽器,去向服務器發送請求,獲取響應信息。
五、urllib的基本使用
1.獲取百度網頁的全部源碼
# 使用urllib獲取百度首頁的源碼
import urllib.request
# 1.定義url
url = 'http://www.baidu.com'
# 2.模擬浏覽器向服務器發送請求
response = urllib.request.urlopen(url)
# 3.獲取響應中的頁面源碼
# read()方法 返回的是字節形式的二進制數
# 將二進制數轉換為字符串
# 二進制 ——》字符串 解碼 decode('編碼的格式')
content = response.read().decode('utf-8')
# 4.打印內容
print(content)
2.一種類型和六種方法
import urllib.request
url = 'http://www.baidu.com'
# 模擬浏覽器向服務器發送請求
response = urllib.request.urlopen(url)
# 一個類型和六個方法
# response是HTTPResponse類型
# print(type(response))
# 一、read()方法
# 1.按照一個字節為單位讀取
content = response.read()
print(content)
# 2.只讀X個字節 read(X)
content = response.read(5)
print(content)
# 二、readline()方法 讀取一行
content = response.readline()
print(content)
# 三、readlines()方法 以行為單位讀取,直至讀完
content = response.readlines()
print(content)
# 四、getcode()方法
# 返回狀態碼,若是200則表示邏輯正確
print(response.getcode())
# 五、geturl()方法
# 返回url地址
print(response.geturl())
# 六、getheaders()方法
# 獲取狀態信息
print(response.getheaders())
3.urllib下載資源
import urllib.request
# 1.下載網頁
url_page = 'http://www.baidu.com'
# url代表下載的路徑 filename 代表文件的名字
# 在python中可以寫變量的名字,也可以寫值
urllib.request.urlretrieve(url_page,'baidu.html')
# 2.下載圖片
url_img = 'https://tse1-mm.cn.bing.net/th/id/OIP-C.zgBWxADXwdw-seRK5cLy-wHaMR?w=194&h=321&c=7&r=0&o=5&dpr=1.5&pid=1.7' urllib.request.urlretrieve(url=url_img,filename='img.jpg')
# 3.下載視頻
url_video = 'https://kn-cdn.codemao.cn/creation/lesson/4_kitten_public/lesson01.mp4'
urllib.request.urlretrieve(url_video,'video.mp4')
 [quantitative investment system Python] mplfinance drawing K-line diagram 1
[quantitative investment system Python] mplfinance drawing K-line diagram 1
Images commonly used in quanti
 Python adds an asterisk * before the array of lists, elements, dictionaries, sets and numpy (the return container in the \u make\u layer function in RESNET is marked with an asterisk)
Python adds an asterisk * before the array of lists, elements, dictionaries, sets and numpy (the return container in the \u make\u layer function in RESNET is marked with an asterisk)
python In the list 、 Elements