python pandas time series data
ʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞ
꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ
import pandas as pd
Use to_datetime() Method can The data of the string sequence is converted to Index of time series , namely Convert data into time series data .
dates1 = pd.to_datetime(['1/6/2022', '3/6/2022', '2/6/2022'])
print(dates1)

__
With datetime Objects as a sequence Series or DataFrame The index of , Time series data , No additional methods are needed .
dates3 = [datetime(2022, 6, 1), datetime(2022, 6, 3), datetime(2022, 6, 4), datetime(2022, 6, 2), datetime(2022, 6, 5)]
s1 = pd.Series([2, 3, 5, 7, 9], index=dates3)
print(s1)
print("=============================================================")
print(s1.index)
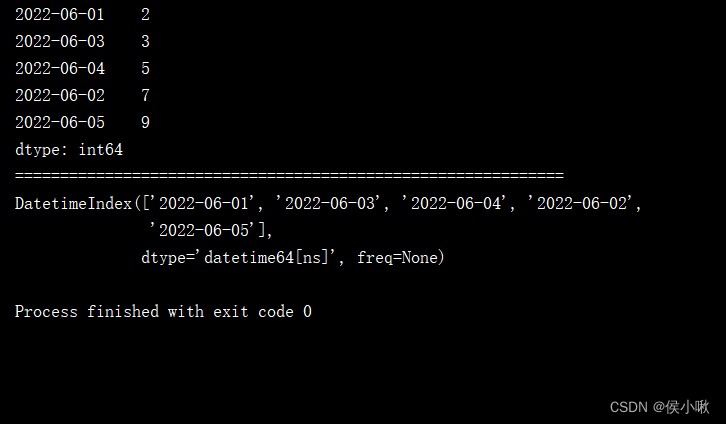
date_range1 = pd.date_range('1/1/2022', periods=1000)
s2 = pd.Series(np.random.randn(1000), index=date_range1)
print(s2)
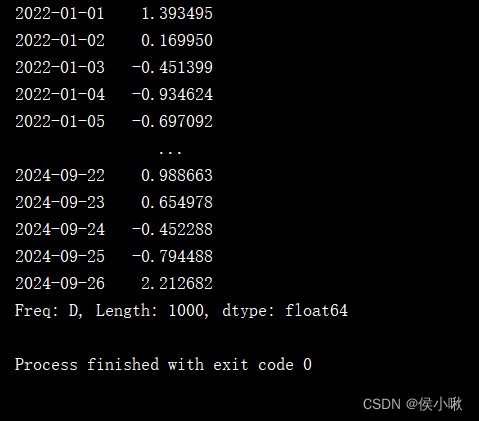
date_range2 = pd.date_range('2022-2-1', '2022-3-1')
s2 = pd.Series(np.random.randn(len(date_range2)), index=date_range2)
print(s2)
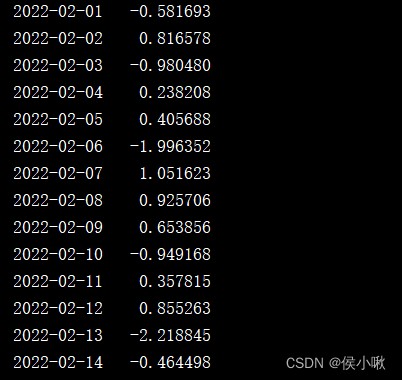
frequently-used freq Yes :
Examples are as follows :
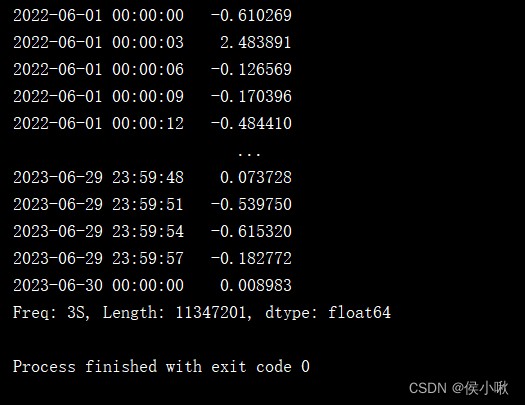
date_range3 = pd.date_range('2022-06-01','2023-06-30',freq='3s')
s2 = pd.Series(np.random.randn(len(date_range3)), index=date_range3)
print(s2)
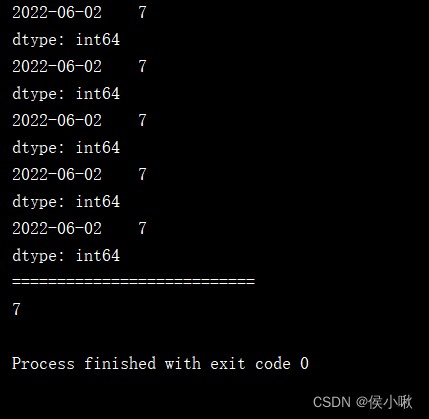
dates = [datetime(2022, 6, 1), datetime(2022, 6, 3), datetime(2022, 6, 4), datetime(2022, 6, 2), datetime(2022, 6, 5)]
s1 = pd.Series([2, 3, 5, 7, 9], index=dates)
print(s1['2022 06 02'])
print(s1['2022-06-02'])
print(s1['2022/06/02'])
print(s1['2022.06.02'])
print(s1['2022, 06, 02'])
print("===========================")
# This method does not get a piece of data , It's a value .
print(s1[datetime(2022, 6, 2)])
Example year index
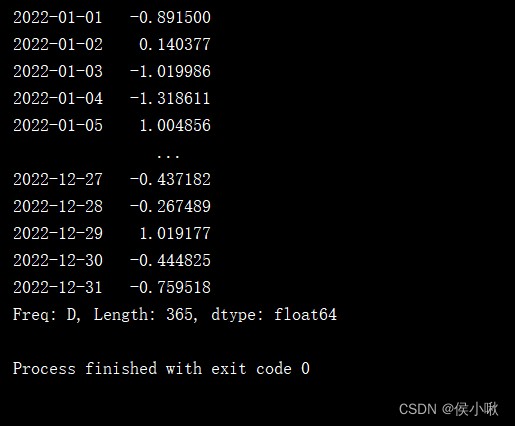
s2 = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2022', periods=1000))
print(s2['2022'])
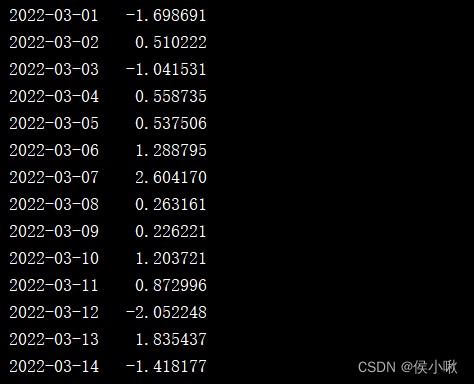
s2 = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2022', periods=1000))
print(s2['2022-03'])
[start:end:step] section print(s1[::2])
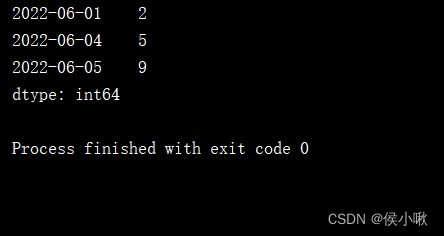
s2 = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2022', periods=1000))
print(s2['2022-03-19':'2022-04-02'])
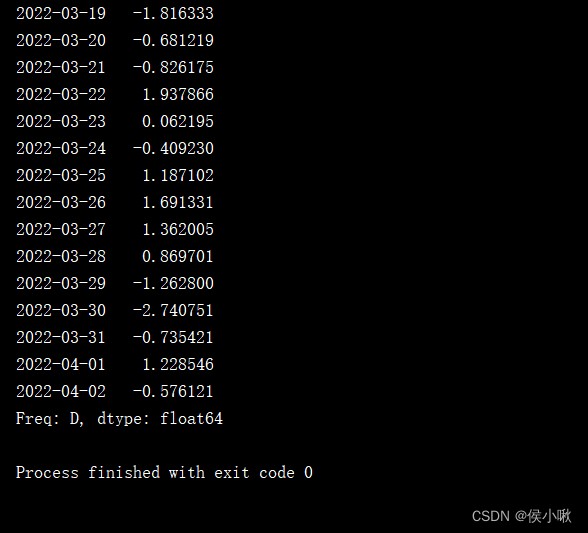
You can modify some data by slicing , The following example shows that the results are slightly .
s2 = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2022', periods=1000))
s2['2022-03-19':'2022-04-02'] = 1
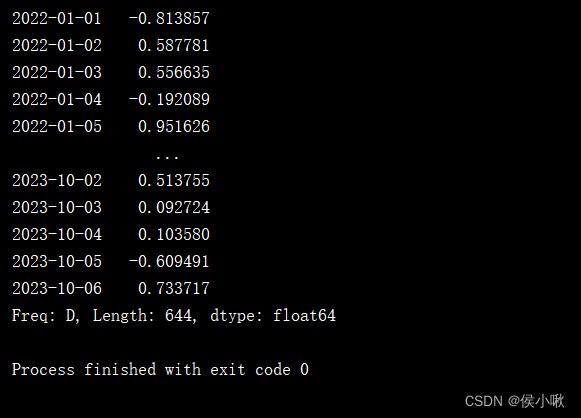
Cut data after a certain date
s2 = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2022', periods=1000))
print(s2.truncate(after='10/6/2023'))
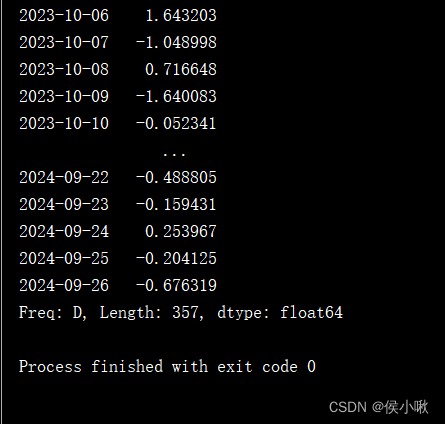
Cut the data before a certain date
s2 = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2022', periods=1000))
print(s2.truncate(before='10/6/2023'))
dates2 = pd.to_datetime(['1/6/2022', '3/6/2022', '2/6/2022', None])
print(dates2)
If there is a null value in the original data None, Here it is transformed into NaT In the form of .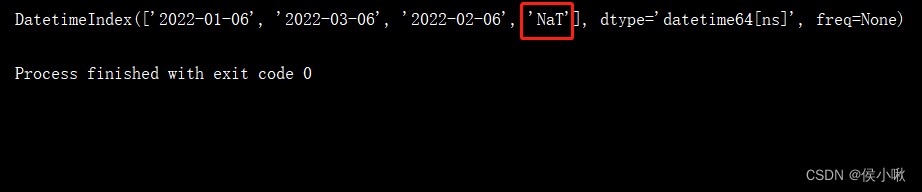
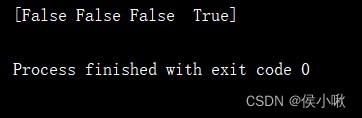
Judge whether it is a null value ,isnull() Method It is available in time series index .
dates2 = pd.to_datetime(['1/6/2022', '3/6/2022', '2/6/2022', None])
print(pd.isnull(dates2))
dates2 = pd.to_datetime(['1/6/2022', '3/6/2022', '2/6/2022', None])
print(dates2.dropna())

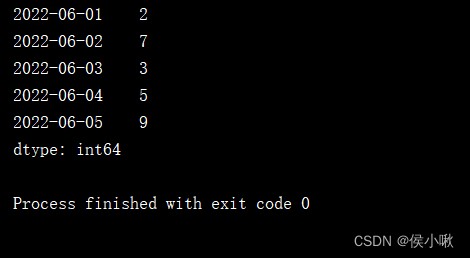
Sort the time
dates3 = [datetime(2022, 6, 1), datetime(2022, 6, 3), datetime(2022, 6, 4), datetime(2022, 6, 2), datetime(2022, 6, 5)]
s1 = pd.Series([2, 3, 5, 7, 9], index=dates3)
print(s1.sort_index())
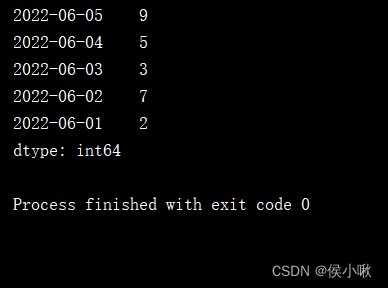
print(s1.sort_index(ascending=False))
dates = pd.DatetimeIndex(['6/1/2022', '6/2/2022', '6/2/2022', '6/3/2022', '6/4/2022'])
s3 = pd.Series(['aaa', 'ccc', 'bbb', 'ddd', 'eee'], index=dates)
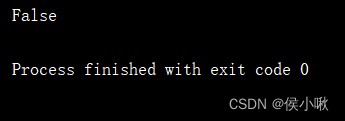
print(s3.index.is_unique)
Print out s3 Of is_unique attribute , The value is Fasle, Indicates that there are duplicate values .
When there are a large number of duplicate indexes , Maybe suitable for polymerization .
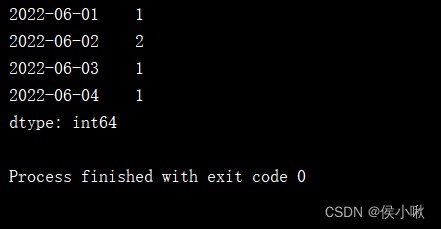
Take the aggregate as an example .
print(s3.groupby(level=0).count())
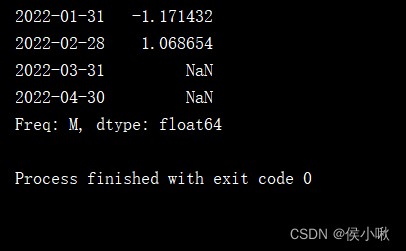
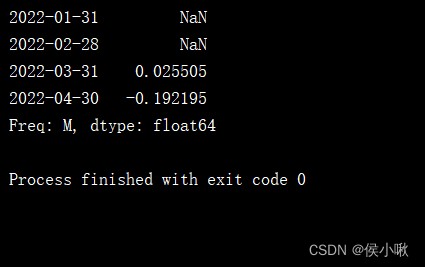
s4 = pd.Series(np.random.randn(4),index=pd.date_range('1/1/2022',periods=4,freq='M'))
print(s4.shift(2))
s4 = pd.Series(np.random.randn(4),index=pd.date_range('1/1/2022',periods=4,freq='M'))
print(s4.shift(-2))