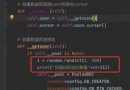
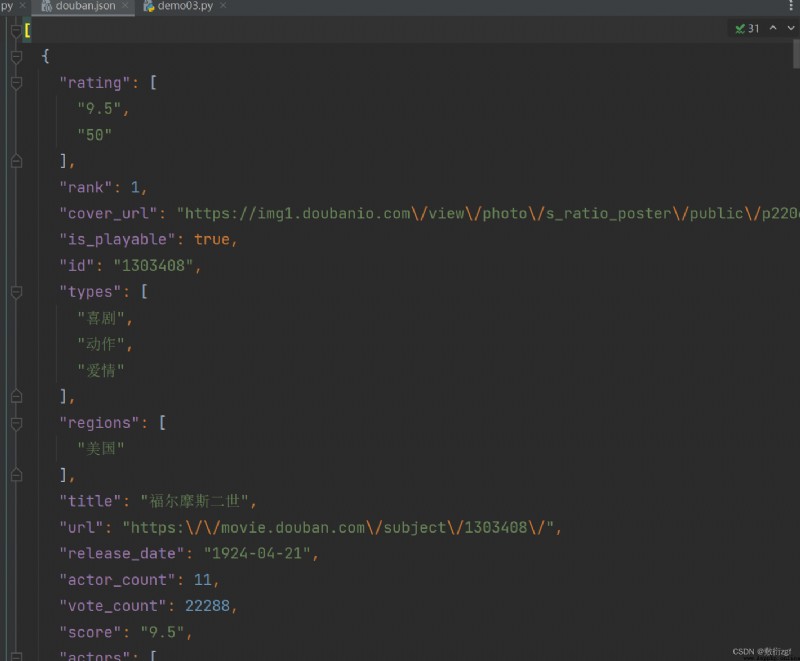
Un.、ajaxDemande la première page du film Bean flap
# getDemande
# Obtenez les données de la première page du film Bean flap et sauvegardez
import urllib.request
url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=20'
headers = {
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44'
}
# Personnalisation de l'objet demandé
request =urllib.request.Request(url=url,headers=headers)
# Obtenir les données de la réponse
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
# print(content)
# Données téléchargées localement
# open Méthode utilisée par défaut gbkCodage, Si vous voulez enregistrer des caractères chinois ,Il est nécessaire deopenLe format d'encodage spécifié dans la méthode estutf-8
# fp = open('douban.json','w',encoding='utf-8')
# fp.write(content)
fp = open('douban.json','w',encoding='utf-8')
fp.write(content)
# Ces deux lignes sont équivalentes à
with open('douban1.json','w',encoding='utf-8') as fp:
fp.write(content)
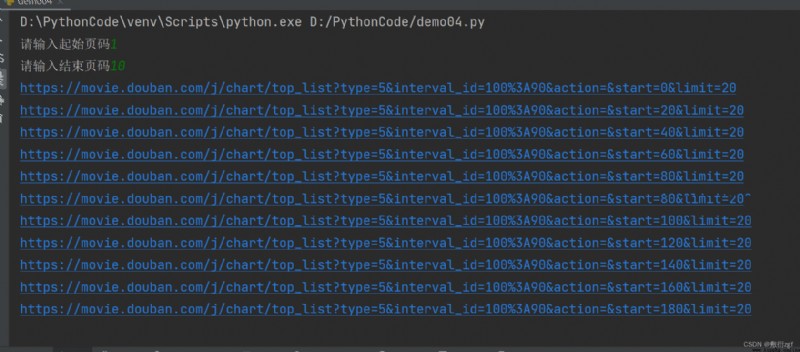
2.、ajaxDemande les dix premières pages du film Bean flap
# Les dix premières pages du film Bean flap
# https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&
# start=0&limit=20
# https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&
# start=20&limit=20
# https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&
# start=40&limit=20
# page 1 2 3 4
# start 0 20 40 60 start = (page - 1) * 20
import urllib.parse
def create_request(page):
base_url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&'
data = {
'start' : (page - 1)*20,
'limit' : 20 ,
}
data = urllib.parse.urlencode(data)
url = base_url + data
print(url)
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44'
}
# 1.Personnalisation de l'objet demandé
# request = urllib.request.Request()
# Entrée du programme
if __name__ == '__main__':
start_page = int(input('Veuillez saisir le numéro de page de départ'))
end_page = int(input('Veuillez entrer le numéro de la page de fin'))
for page in range (start_page , end_page + 1):
# Chaque page a une personnalisation de l'objet demandé
create_request(page)
# print(page)
Cas complet:
import urllib.parse
import urllib.request
def create_request(page):
base_url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&'
data = {
'start' : (page - 1)*20,
'limit' : 20 ,
}
data = urllib.parse.urlencode(data)
url = base_url + data
print(url)
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44'
}
# 1.Personnalisation de l'objet demandé
request = urllib.request.Request(url = url , headers = headers)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(page,content):
with open('douban_' + str(page)+'.json' ,'w',encoding='utf-8') as fp:
fp.write(content)
# Entrée du programme
if __name__ == '__main__':
start_page = int(input('Veuillez saisir le numéro de page de départ'))
end_page = int(input('Veuillez entrer le numéro de la page de fin'))
for page in range (start_page , end_page + 1):
# Chaque page a une personnalisation de l'objet demandé
request = create_request(page)
# 2.Obtenir les données de la réponse
content = get_content(request)
# 3.Télécharger les données
down_load(page,content)
# print(page)
Trois、ajaxDepost Demander le site Web de KFC
# Première page
# https://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# post
# cname: Huangshan
# pid:
# pageIndex: 1
# pageSize: 10
# Page 2
# https://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# post
# cname: Huangshan
# pid:
# pageIndex: 2
# pageSize: 10
import urllib.request
import urllib.parse
def creat_request(page):
base_url = 'https://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
data = {
'cname': 'Huangshan',
'pid': '',
'pageIndex': page,
'pageSize': '10'
}
data = urllib.parse.urlencode(data).encode('utf-8')
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44'
}
request = urllib.request.Request(url=base_url,headers=headers,data=data)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(page,content):
with open('kfc_'+str(page)+'.json','w',encoding='utf-8') as fp:
fp.write(content)
if __name__ == '__main__':
start_page = int(input('Veuillez entrer la page de départ'))
end_page = int(input('Veuillez entrer la page de fin'))
for page in range(start_page,end_page + 1):
# Demande de personnalisation de l'objet
request = creat_request(page)
# Obtenir le code source de la page web
content = get_content(request)
# Télécharger
down_load(page,content)
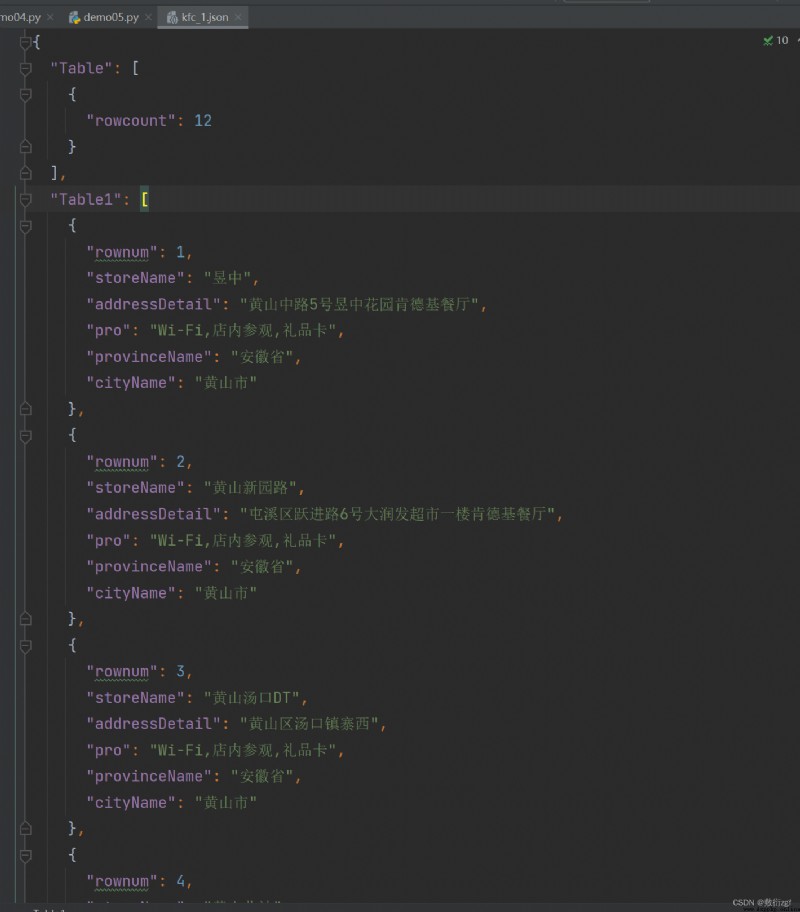
Quatre、urllibAnomalie
URLError\HTTPError
import urllib.request
import urllib.error
url = 'https://blog.csdn.net/sulixu/article/details/1198189491'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44'
}
try:
request = urllib.request.Request(url=url ,headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
except urllib.error.HTTPError:
print('Mise à jour du système')
except urllib.error.URLError:
print(' Le système est en cours de mise à niveau ...')
Cinq、MicrobloggingcookieConnexion
# La page de renseignements personnels est utf-8, Mais une erreur de codage a été signalée , Parce qu'il n'est pas entré dans la page de renseignements personnels , Page bloquée sur la page de connexion
# La page de connexion n'est pas utf-8Codage
import urllib.request
url = 'https://weibo.com/u/6574284471'
headers = {
# ':authority':' weibo.com',
# ':method':' GET',
# ':path':' /u/6574284471',
# ':scheme':' https',
'accept':' text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
# 'accept-encoding':' gzip, deflate, br',
'accept-language':' zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'cache-control':' max-age=0',
'cookie: XSRF-TOKEN=6ma7fyurg-D7srMvPHSBXnd7; PC_TOKEN=c80929a33d; SUB=_2A25Pt6gfDeRhGeBL7FYT-CrIzD2IHXVsxJ7XrDV8PUNbmtANLU_ikW9NRsq_VXzy15yBjKrXXuLy01cvv2Vl9GaI; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WWh0duRqerzYUFYCVXfeaq95JpX5KzhUgL.FoqfS0BE1hBXS022dJLoIp-LxKqL1K-LBoMLxKnLBK2L12xA9cqt; ALF=1687489486; SSOLoginState=1655953487; _s_tentry=weibo.com; Apache=4088119873839.28.1655954158255; SINAGLOBAL=4088119873839.28.1655954158255; ULV=1655954158291:1:1:1:4088119873839.28.1655954158255':'; WBPSESS=jKyskQ8JC9Xst5B1mV_fu6PgU8yZ2Wz8GqZ7KvsizlaQYIWJEyF7NSFv2ZP4uCpwz4tKG2BL44ACE6phIx2TUnD3W1v9mxLa_MQC4u4f2UaPhXf55kpgp85_A2VrDQjuAtgDgiAhD-DP14cuzq0UDA==',
#referer Déterminer si le chemin actuel est entré par le chemin précédent ,En général, Fait pour la chaîne de capture d'images
'referer: https':'//weibo.com/newlogin?tabtype=weibo&gid=102803&openLoginLayer=0&url=https%3A%2F%2Fweibo.com%2F',
'sec-ch-ua':' " Not A;Brand";v="99", "Chromium";v="102", "Microsoft Edge";v="102"',
'sec-ch-ua-mobile':' ?0',
'sec-ch-ua-platform':' "Windows"',
'sec-fetch-dest':' document',
'sec-fetch-mode':' navigate',
'sec-fetch-site':' same-origin',
'sec-fetch-user':' ?1',
'upgrade-insecure-requests':' 1',
'user-agent':' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44',
}
# Personnalisation de l'objet demandé
request = urllib.request.Request(url=url,headers=headers)
# Le navigateur analogique envoie une requête au serveur
response = urllib.request.urlopen((request))
# Obtenir les données de la réponse
content = response.read().decode('utf-8')
# print(content)
# Enregistrer les données localement
with open('file/weibo.html','w',encoding='utf-8') as fp:
fp.write(content)
Six、HandlerUtilisation de base du processeur
Action:
urllib.request.urlopen(url)—> Impossible de personnaliser l'en - tête de la requête
request = urllib.request.Request(url=url,headers=headers,data=data)—>L'en - tête de requête peut être personnalisé
Handler—>Personnaliser l'en - tête de demande plus avancé( Avec l'expansion de la logique d'entreprise ,La personnalisation de l'objet demandé ne répond plus à nos besoins,Par exemple:DynamiqueCookieEt l'agent ne peut pas utiliser la personnalisation de l'objet demandéi)
# Besoins:Utiliserhandler Visitez Baidu pour obtenir le code source de la page Web
import urllib.request
url = 'http://www.baidu.com'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44'
}
request = urllib.request.Request(url=url,headers=headers)
# handler build_opener open
# (1) AccèshandlerObjet
handler = urllib.request.HTTPHandler()
# (2) AccèsopenerObjet
opener = urllib.request.build_opener(handler)
# (3) AppelezopenMéthodes
response = opener = open(request)
content = response.read().decode('utf-8')
print(content)
Sept、Serveur mandataire
Agent rapide https://free.kuaidaili.com/free/ Accès gratuit IPEt le numéro de port
import urllib.request
url = 'http://www.baidu.com/s?wd=ip'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44'
}
request = urllib.request.Request(url=url,headers=headers)
# response = urllib.request.urlopen(request)
# handler builder_open open
posix = {
'http': '103.37.141.69:80'
}
handler = urllib.request.ProxyHandler(proxies = posix)
opener = urllib.request.build_opener(handler)
response = opener.open(request)
content = response.read().decode('utf-8')
with open('file/daili.html','w',encoding='utf-8') as fp:
fp.write(content)
Huit、Pool d'agents
import urllib.request
import random
url = 'http://www.baidu.com/s?wd=ip'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44'
}
proxies_pool = [
{
'http': '103.37.141.69:8011' },
{
'http': '103.37.141.69:8022' },
{
'http': '103.37.141.69:8033' }
]
proxies = random.choice(proxies_pool) //Sélection aléatoireIPAdresse
# print(proxies)
request = urllib.request.Request(url=url,headers=headers)
handler = urllib.request.ProxyHandler(proxies = proxies)
opener = urllib.request.build_opener(handler)
response = opener.open(request)
content = response.read().decode('utf-8')
with open('file/daili.html','w',encoding='utf-8') as fp:
fp.write(content)
Neuf、xpathPlug - in
1.InstallationxpathPlug - in:https://www.aliyundrive.com/s/YCtumb2D2J3 Code d'extraction: o4t2
2.InstallationlxmlBibliothèque
pip install lxml -i https://pypi.douban.com/simple
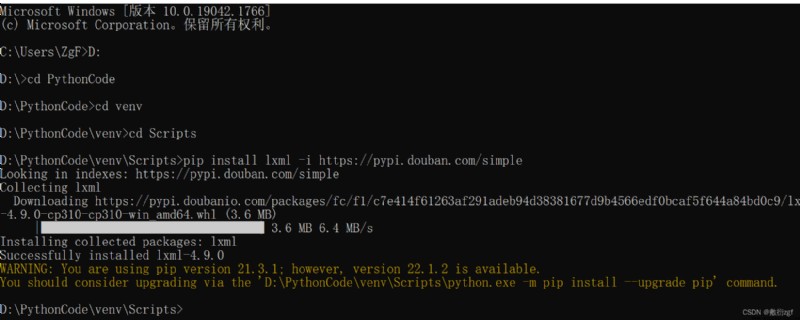
3.Analyse de casxpath
①Résoudre le fichier local etree.parse
## Analysexpath Une façon d'aider les utilisateurs à obtenir une partie du code source d'une page Web
from lxml import etree
# Un.、Résoudre le fichier local etree.parse
tree = etree.parse('file/xpathRésoudre le fichier local.html')
# print(tree)
# tree.xpath('xpathChemin')
# 1.TrouverulEn bas.li
# //:Trouvez tous les noeuds descendants,Sans tenir compte des relations hiérarchiques
# /:Trouver un noeud enfant direct
# li_list = tree.xpath('//body/ul/li')
# print(li_list)
# Longueur de la liste de jugement
# print(len(li_list))
# 2.Trouvez tout ce qui aidPropriétéliÉtiquettes
# li_list = tree.xpath('//ul/li[@id]')
# text() Vous pouvez obtenir le contenu de l'étiquette
# li_list = tree.xpath('//ul/li[@id]/text()')
# TrouveridPourl1DeliÉtiquettes Notez l'ajout de guillemets
# li_list = tree.xpath('//ul/li[@id="l1"]/text()')
# TrouvéidPourl1DeliÉtiquetteclassValeur de l'attribut pour
# li_list = tree.xpath('//ul/li[@id="l1"]/@class')
# Requête floue idInclus danslÉtiquette de
# li_list = tree.xpath('//ul/li[contains(@id,"l")]/text()')
# Requêteid De lAu débutliÉtiquettes
# li_list = tree.xpath('//ul/li[starts-with(@id,"l")]/text()')
# RequêteidPourl1EtclassPourc1De Opérations logiques
li_list = tree.xpath('//ul/li[@id="l1" and @class="c1"]/text()')
li_list = tree.xpath('//ul/li[@id="l1"]/text() | //ul/li[@id="l2"]/text() ')
print(len(li_list))
print(li_list)
②Données de réponse du serveur response.read().decode(‘utf-8’) etree.HTML()
import urllib.request
url = 'http://www.baidu.com/'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44'
}
# Personnalisation de l'objet demandé
request = urllib.request.Request(url=url,headers=headers)
# Serveur d'accès au navigateur analogique
response = urllib.request.urlopen(request)
# Obtenir le code source de la page web
content = response.read().decode('utf-8')
# Analyser le code source de la page web Pour obtenir les données que vous voulez
from lxml import etree
# Résoudre le fichier pour la réponse du serveur
tree = etree.HTML(content)
# Obtenir les données désirées xpathLa valeur de retour pour est un type de liste de données
result = tree.xpath('//input[@id ="su"]/@value')[0]
print(result)