One 、ajax Request Douban movie page 1
# get request
# Get the first page data of Douban movie and save it
import urllib.request
url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=20'
headers = {
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44'
}
# Request object customization
request =urllib.request.Request(url=url,headers=headers)
# Get the data of the response
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
# print(content)
# Download data to local
# open Method uses... By default gbk code , If you want to save Chinese characters , You need to in open The encoding format specified in the method is utf-8
# fp = open('douban.json','w',encoding='utf-8')
# fp.write(content)
fp = open('douban.json','w',encoding='utf-8')
fp.write(content)
# These two lines are equivalent to
with open('douban1.json','w',encoding='utf-8') as fp:
fp.write(content)
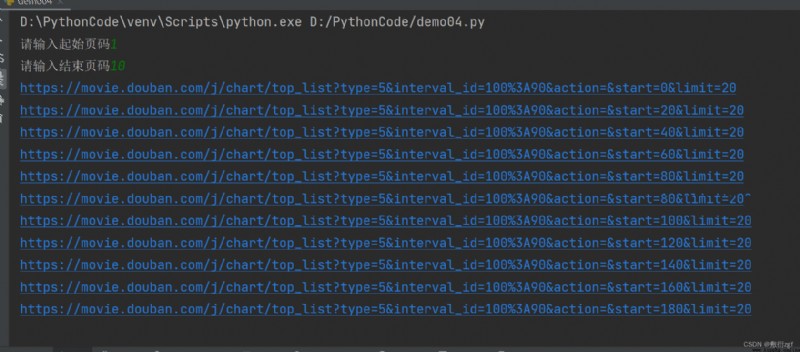
Two 、ajax Request the first ten pages of Douban movie
# The first ten pages of Douban movie
# https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&
# start=0&limit=20
# https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&
# start=20&limit=20
# https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&
# start=40&limit=20
# page 1 2 3 4
# start 0 20 40 60 start = (page - 1) * 20
import urllib.parse
def create_request(page):
base_url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&'
data = {
'start' : (page - 1)*20,
'limit' : 20 ,
}
data = urllib.parse.urlencode(data)
url = base_url + data
print(url)
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44'
}
# 1. Request object customization
# request = urllib.request.Request()
# Program entrance
if __name__ == '__main__':
start_page = int(input(' Please enter the starting page number '))
end_page = int(input(' Please enter the end page number '))
for page in range (start_page , end_page + 1):
# Each page has customization of the request object
create_request(page)
# print(page)
The whole case :
import urllib.parse
import urllib.request
def create_request(page):
base_url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&'
data = {
'start' : (page - 1)*20,
'limit' : 20 ,
}
data = urllib.parse.urlencode(data)
url = base_url + data
print(url)
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44'
}
# 1. Request object customization
request = urllib.request.Request(url = url , headers = headers)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(page,content):
with open('douban_' + str(page)+'.json' ,'w',encoding='utf-8') as fp:
fp.write(content)
# Program entrance
if __name__ == '__main__':
start_page = int(input(' Please enter the starting page number '))
end_page = int(input(' Please enter the end page number '))
for page in range (start_page , end_page + 1):
# Each page has customization of the request object
request = create_request(page)
# 2. Get the data of the response
content = get_content(request)
# 3. Download data
down_load(page,content)
# print(page)
3、 ... and 、ajax Of post Request KFC official website
# first page
# https://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# post
# cname: huangshan
# pid:
# pageIndex: 1
# pageSize: 10
# The second page
# https://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# post
# cname: huangshan
# pid:
# pageIndex: 2
# pageSize: 10
import urllib.request
import urllib.parse
def creat_request(page):
base_url = 'https://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
data = {
'cname': ' huangshan ',
'pid': '',
'pageIndex': page,
'pageSize': '10'
}
data = urllib.parse.urlencode(data).encode('utf-8')
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44'
}
request = urllib.request.Request(url=base_url,headers=headers,data=data)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(page,content):
with open('kfc_'+str(page)+'.json','w',encoding='utf-8') as fp:
fp.write(content)
if __name__ == '__main__':
start_page = int(input(' Please enter the start page '))
end_page = int(input(' Please enter the end page '))
for page in range(start_page,end_page + 1):
# Request object customization
request = creat_request(page)
# Get web source
content = get_content(request)
# download
down_load(page,content)
Four 、urllib abnormal
URLError\HTTPError
import urllib.request
import urllib.error
url = 'https://blog.csdn.net/sulixu/article/details/1198189491'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44'
}
try:
request = urllib.request.Request(url=url ,headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
except urllib.error.HTTPError:
print(' The system is being upgraded ')
except urllib.error.URLError:
print(' The system is still being upgraded ...')
5、 ... and 、 Microblogging cookie Sign in
# The personal information page is utf-8, But the code error is still reported , Because there is no access to the personal information page , The web page is blocked to the login page
# The login page is not utf-8 code
import urllib.request
url = 'https://weibo.com/u/6574284471'
headers = {
# ':authority':' weibo.com',
# ':method':' GET',
# ':path':' /u/6574284471',
# ':scheme':' https',
'accept':' text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
# 'accept-encoding':' gzip, deflate, br',
'accept-language':' zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'cache-control':' max-age=0',
'cookie: XSRF-TOKEN=6ma7fyurg-D7srMvPHSBXnd7; PC_TOKEN=c80929a33d; SUB=_2A25Pt6gfDeRhGeBL7FYT-CrIzD2IHXVsxJ7XrDV8PUNbmtANLU_ikW9NRsq_VXzy15yBjKrXXuLy01cvv2Vl9GaI; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WWh0duRqerzYUFYCVXfeaq95JpX5KzhUgL.FoqfS0BE1hBXS022dJLoIp-LxKqL1K-LBoMLxKnLBK2L12xA9cqt; ALF=1687489486; SSOLoginState=1655953487; _s_tentry=weibo.com; Apache=4088119873839.28.1655954158255; SINAGLOBAL=4088119873839.28.1655954158255; ULV=1655954158291:1:1:1:4088119873839.28.1655954158255':'; WBPSESS=jKyskQ8JC9Xst5B1mV_fu6PgU8yZ2Wz8GqZ7KvsizlaQYIWJEyF7NSFv2ZP4uCpwz4tKG2BL44ACE6phIx2TUnD3W1v9mxLa_MQC4u4f2UaPhXf55kpgp85_A2VrDQjuAtgDgiAhD-DP14cuzq0UDA==',
#referer Judge whether the current path comes in from the previous path , In general , Make anti-theft chains for pictures
'referer: https':'//weibo.com/newlogin?tabtype=weibo&gid=102803&openLoginLayer=0&url=https%3A%2F%2Fweibo.com%2F',
'sec-ch-ua':' " Not A;Brand";v="99", "Chromium";v="102", "Microsoft Edge";v="102"',
'sec-ch-ua-mobile':' ?0',
'sec-ch-ua-platform':' "Windows"',
'sec-fetch-dest':' document',
'sec-fetch-mode':' navigate',
'sec-fetch-site':' same-origin',
'sec-fetch-user':' ?1',
'upgrade-insecure-requests':' 1',
'user-agent':' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44',
}
# Request object customization
request = urllib.request.Request(url=url,headers=headers)
# Simulate the browser to send a request to the server
response = urllib.request.urlopen((request))
# Get the data of the response
content = response.read().decode('utf-8')
# print(content)
# Save the data locally
with open('file/weibo.html','w',encoding='utf-8') as fp:
fp.write(content)
6、 ... and 、Handler Basic use of processor
effect :
urllib.request.urlopen(url)—> Unable to customize request header
request = urllib.request.Request(url=url,headers=headers,data=data)—> Request headers can be customized
Handler—> Customize more advanced request headers ( With the expansion of business logic , The customization of the request object can no longer meet our needs , for example : dynamic Cookie And agents cannot use the customization of the request object i)
# demand : Use handler Visit Baidu to get the web source code
import urllib.request
url = 'http://www.baidu.com'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44'
}
request = urllib.request.Request(url=url,headers=headers)
# handler build_opener open
# (1) obtain handler object
handler = urllib.request.HTTPHandler()
# (2) obtain opener object
opener = urllib.request.build_opener(handler)
# (3) call open Method
response = opener = open(request)
content = response.read().decode('utf-8')
print(content)
7、 ... and 、 proxy server
In fast acting https://free.kuaidaili.com/free/ Get free IP And port number 
import urllib.request
url = 'http://www.baidu.com/s?wd=ip'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44'
}
request = urllib.request.Request(url=url,headers=headers)
# response = urllib.request.urlopen(request)
# handler builder_open open
posix = {
'http': '103.37.141.69:80'
}
handler = urllib.request.ProxyHandler(proxies = posix)
opener = urllib.request.build_opener(handler)
response = opener.open(request)
content = response.read().decode('utf-8')
with open('file/daili.html','w',encoding='utf-8') as fp:
fp.write(content)
8、 ... and 、 Agent pool
import urllib.request
import random
url = 'http://www.baidu.com/s?wd=ip'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44'
}
proxies_pool = [
{
'http': '103.37.141.69:8011' },
{
'http': '103.37.141.69:8022' },
{
'http': '103.37.141.69:8033' }
]
proxies = random.choice(proxies_pool) // Random selection IP Address
# print(proxies)
request = urllib.request.Request(url=url,headers=headers)
handler = urllib.request.ProxyHandler(proxies = proxies)
opener = urllib.request.build_opener(handler)
response = opener.open(request)
content = response.read().decode('utf-8')
with open('file/daili.html','w',encoding='utf-8') as fp:
fp.write(content)
Nine 、xpath plug-in unit
1. install xpath plug-in unit :https://www.aliyundrive.com/s/YCtumb2D2J3 Extraction code : o4t2
2. install lxml library
pip install lxml -i https://pypi.douban.com/simple
3. Case analysis xpath
① Parsing local files etree.parse
## analysis xpath A way to help users get part of the source code of web pages
from lxml import etree
# One 、 Parsing local files etree.parse
tree = etree.parse('file/xpath Parsing local files .html')
# print(tree)
# tree.xpath('xpath route ')
# 1. lookup ul Below li
# //: Find all descendant nodes , Regardless of hierarchy
# /: Find the direct child node
# li_list = tree.xpath('//body/ul/li')
# print(li_list)
# Judge list length
# print(len(li_list))
# 2. Find all that have id Attribute li label
# li_list = tree.xpath('//ul/li[@id]')
# text() You can get the contents of the tag
# li_list = tree.xpath('//ul/li[@id]/text()')
# lookup id by l1 Of li label Note the quotation marks
# li_list = tree.xpath('//ul/li[@id="l1"]/text()')
# Find the id by l1 Of li Labeled class The attribute value
# li_list = tree.xpath('//ul/li[@id="l1"]/@class')
# Fuzzy query id Contained in the l The label of
# li_list = tree.xpath('//ul/li[contains(@id,"l")]/text()')
# Inquire about id From to l At the beginning li label
# li_list = tree.xpath('//ul/li[starts-with(@id,"l")]/text()')
# Inquire about id by l1 and class by c1 Of Logical operations
li_list = tree.xpath('//ul/li[@id="l1" and @class="c1"]/text()')
li_list = tree.xpath('//ul/li[@id="l1"]/text() | //ul/li[@id="l2"]/text() ')
print(len(li_list))
print(li_list)
② Data that the server responds to response.read().decode(‘utf-8’) etree.HTML()
import urllib.request
url = 'http://www.baidu.com/'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44'
}
# Request object customization
request = urllib.request.Request(url=url,headers=headers)
# Simulate browser access to the server
response = urllib.request.urlopen(request)
# Get web source
content = response.read().decode('utf-8')
# Analyze the source code of web page To get the data you want
from lxml import etree
# Parse the server response file
tree = etree.HTML(content)
# Get the data you want xpath The return value of is a list type of data
result = tree.xpath('//input[@id ="su"]/@value')[0]
print(result)