python pandas 時間序列數據
ʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞ
꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ꧔ꦿ
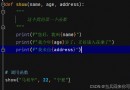
import pandas as pd
使用to_datetime()方法可以將 字符串序列的數據轉化為 時間序列的索引,即 將數據轉化為時間序列數據。
dates1 = pd.to_datetime(['1/6/2022', '3/6/2022', '2/6/2022'])
print(dates1)

__
以datetime對象組成的序列作為Series或DataFrame的索引,則直接就是時間序列數據了,不再需要其他額外方法。
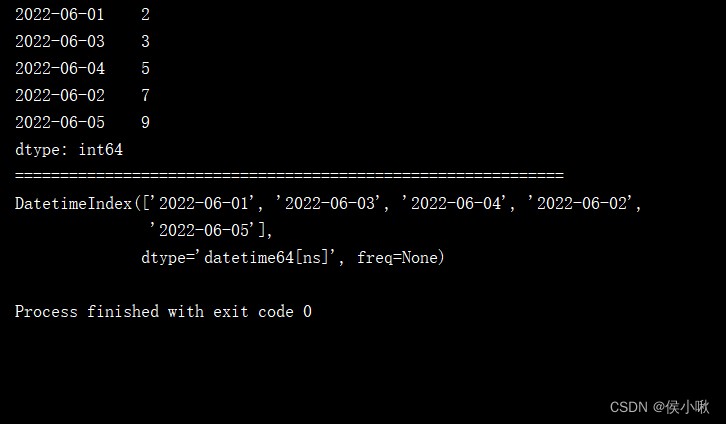
dates3 = [datetime(2022, 6, 1), datetime(2022, 6, 3), datetime(2022, 6, 4), datetime(2022, 6, 2), datetime(2022, 6, 5)]
s1 = pd.Series([2, 3, 5, 7, 9], index=dates3)
print(s1)
print("=============================================================")
print(s1.index)
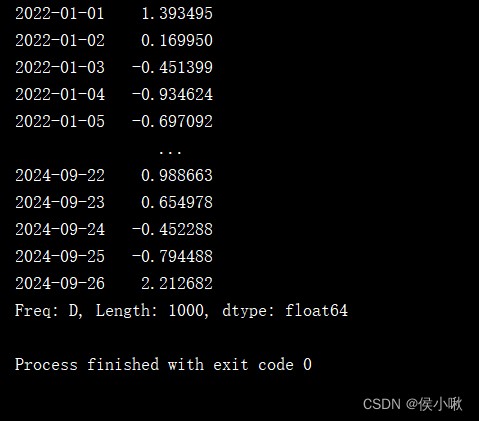
date_range1 = pd.date_range('1/1/2022', periods=1000)
s2 = pd.Series(np.random.randn(1000), index=date_range1)
print(s2)
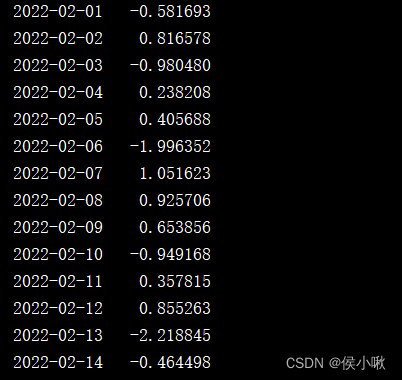
date_range2 = pd.date_range('2022-2-1', '2022-3-1')
s2 = pd.Series(np.random.randn(len(date_range2)), index=date_range2)
print(s2)
常用的freq有:
示例如下:
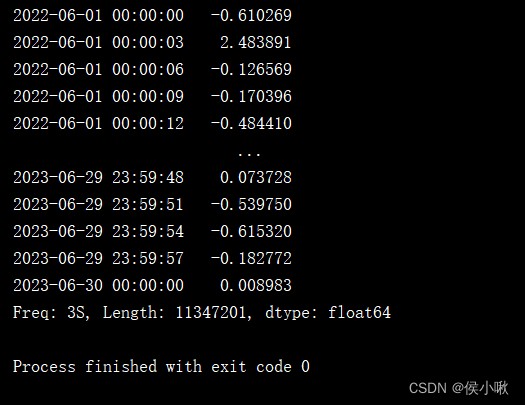
date_range3 = pd.date_range('2022-06-01','2023-06-30',freq='3s')
s2 = pd.Series(np.random.randn(len(date_range3)), index=date_range3)
print(s2)
dates = [datetime(2022, 6, 1), datetime(2022, 6, 3), datetime(2022, 6, 4), datetime(2022, 6, 2), datetime(2022, 6, 5)]
s1 = pd.Series([2, 3, 5, 7, 9], index=dates)
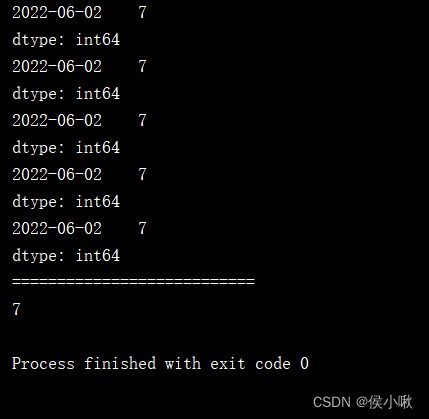
print(s1['2022 06 02'])
print(s1['2022-06-02'])
print(s1['2022/06/02'])
print(s1['2022.06.02'])
print(s1['2022, 06, 02'])
print("===========================")
# 此種寫法取出來的不是一條數據,而是一個值。
print(s1[datetime(2022, 6, 2)])
年份索引示例
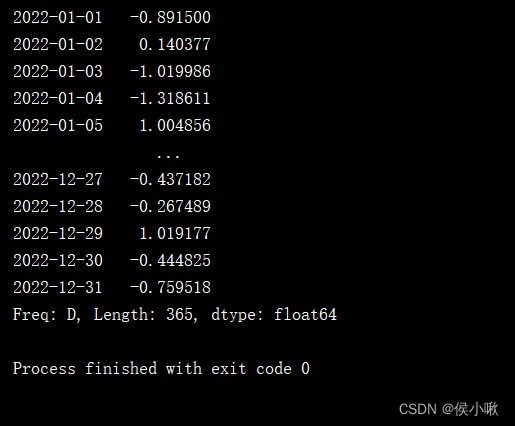
s2 = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2022', periods=1000))
print(s2['2022'])
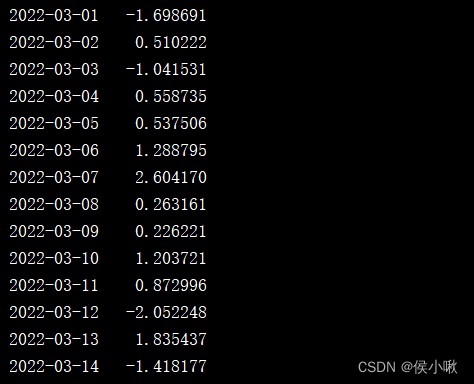
s2 = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2022', periods=1000))
print(s2['2022-03'])
[start:end:step]切片print(s1[::2])
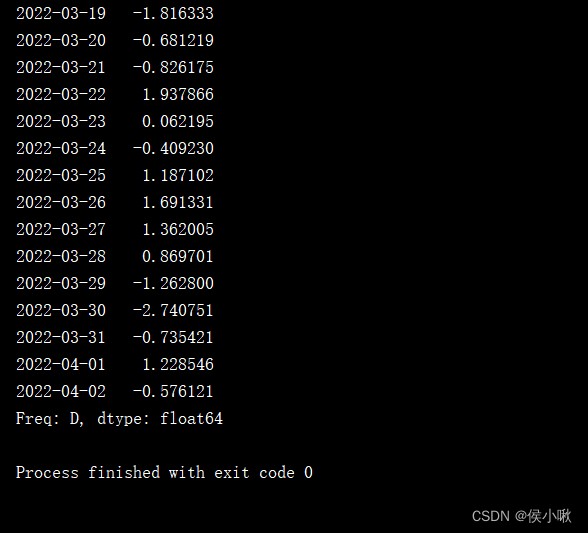
s2 = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2022', periods=1000))
print(s2['2022-03-19':'2022-04-02'])
可以借助切片達到修改部分數據的目的,示例如下結果略。
s2 = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2022', periods=1000))
s2['2022-03-19':'2022-04-02'] = 1
截去某日期後的數據
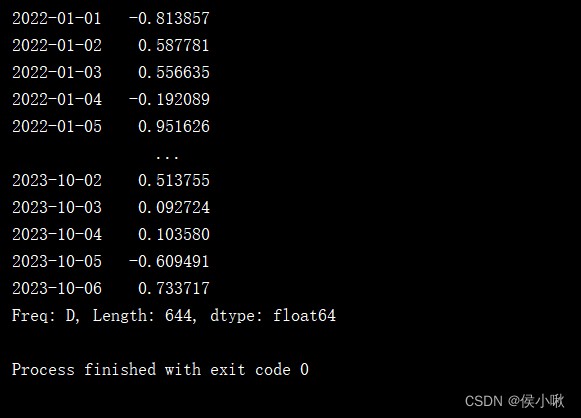
s2 = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2022', periods=1000))
print(s2.truncate(after='10/6/2023'))
截去某日期前的數據
s2 = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2022', periods=1000))
print(s2.truncate(before='10/6/2023'))
dates2 = pd.to_datetime(['1/6/2022', '3/6/2022', '2/6/2022', None])
print(dates2)
如果原數據中存在空值 None,則在這裡被轉化為 NaT 的形式。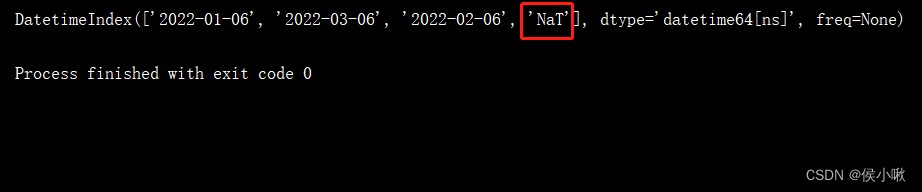
判斷是否為空值,isnull()方法 在時間序列索引中是可用的。
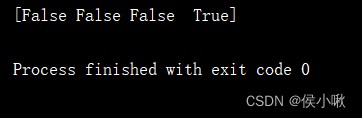
dates2 = pd.to_datetime(['1/6/2022', '3/6/2022', '2/6/2022', None])
print(pd.isnull(dates2))
dates2 = pd.to_datetime(['1/6/2022', '3/6/2022', '2/6/2022', None])
print(dates2.dropna())

給時間排序
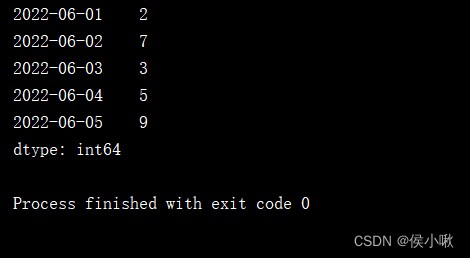
dates3 = [datetime(2022, 6, 1), datetime(2022, 6, 3), datetime(2022, 6, 4), datetime(2022, 6, 2), datetime(2022, 6, 5)]
s1 = pd.Series([2, 3, 5, 7, 9], index=dates3)
print(s1.sort_index())
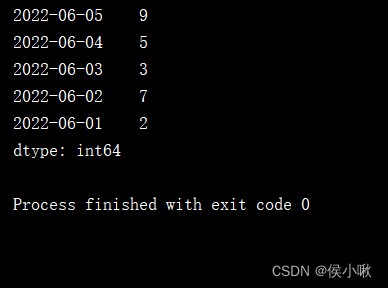
print(s1.sort_index(ascending=False))
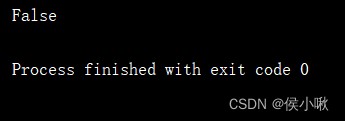
dates = pd.DatetimeIndex(['6/1/2022', '6/2/2022', '6/2/2022', '6/3/2022', '6/4/2022'])
s3 = pd.Series(['aaa', 'ccc', 'bbb', 'ddd', 'eee'], index=dates)
print(s3.index.is_unique)
打印出s3的is_unique屬性,值為Fasle,表明存在重復值。
存在大量重復索引時,也許適合做聚合。
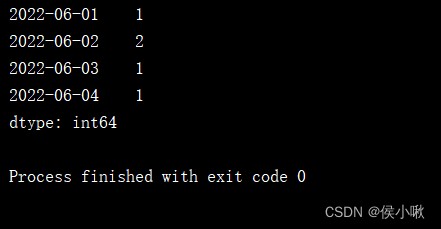
以聚合計數為例。
print(s3.groupby(level=0).count())
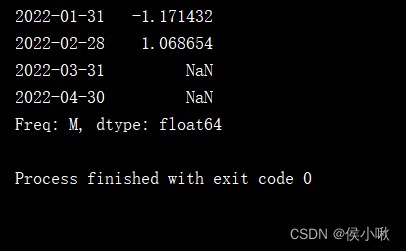
s4 = pd.Series(np.random.randn(4),index=pd.date_range('1/1/2022',periods=4,freq='M'))
print(s4.shift(2))
s4 = pd.Series(np.random.randn(4),index=pd.date_range('1/1/2022',periods=4,freq='M'))
print(s4.shift(-2))