一、單因素分析線性擬合
二、實現地理編碼
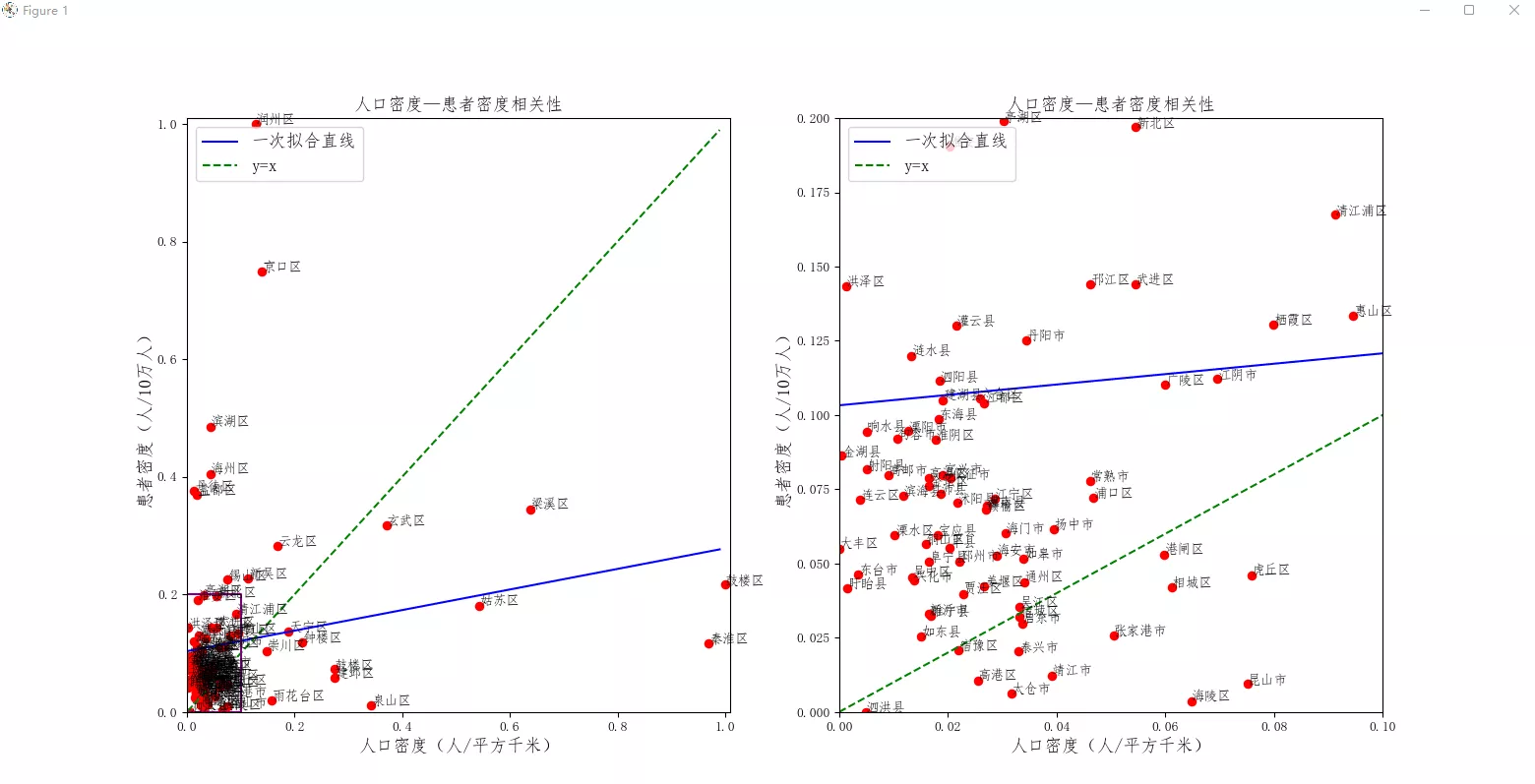
一、單因素分析線性擬合功能:線性擬合,單因素分析,對散點圖進行線性擬合,並放大散點圖的局部位置
輸入:某個xlsx文件,包含'患者密度(人/10萬人)'和'人口密度(人/平方千米)'兩列
輸出:對這兩列數據進行線性擬合,繪制散點
實現代碼:
import pandas as pdfrom pylab import mplfrom scipy import optimizeimport numpy as npimport matplotlib.pyplot as pltdef f_1(x, A, B): return A*x + Bdef draw_cure(file): data1=pd.read_excel(file) data1=pd.DataFrame(data1) hz=list(data1['患者密度(人/10萬人)']) rk=list(data1['人口密度(人/平方千米)']) hz_gy=[] rk_gy=[] for i in hz: hz_gy.append((i-min(hz))/(max(hz)-min(hz))) for i in rk: rk_gy.append((i-min(rk))/(max(rk)-min(rk))) n=['玄武區','秦淮區','建邺區','鼓樓區','浦口區','棲霞區','雨花台區','江寧區','六合區','溧水區','高淳區', '錫山區','惠山區','濱湖區','梁溪區','新吳區','江陰市','宜興市', '鼓樓區','雲龍區','賈汪區','泉山區','銅山區','豐縣','沛縣','睢寧縣','新沂市','邳州市', '天寧區','鐘樓區','新北區','武進區','金壇區','溧陽市', '虎丘區','吳中區','相城區','姑蘇區','吳江區','常熟市','張家港市','昆山市','太倉市', '崇川區','港閘區','通州區','如東縣','啟東市','如皋市','海門市','海安市', '連雲區','海州區','贛榆區','東海縣','灌雲縣','灌南縣', '淮安區','淮陰區','清江浦區','洪澤區','漣水縣','盱眙縣','金湖縣', '亭湖區','鹽都區','大豐區','響水縣','濱海縣','阜寧縣','射陽縣','建湖縣','東台市', '廣陵區','邗江區','江都區','寶應縣','儀征市','高郵市', '京口區','潤州區','丹徒區','丹陽市','揚中市','句容市', '海陵區','高港區','姜堰區','興化市','靖江市','泰興市', '宿城區','宿豫區','沭陽縣','泗陽縣','泗洪縣'] mpl.rcParams['font.sans-serif'] = ['FangSong'] plt.figure(figsize=(16,8),dpi=98) p1 = plt.subplot(121) p2 = plt.subplot(122) p1.scatter(rk_gy,hz_gy,c='r') p2.scatter(rk_gy,hz_gy,c='r') p1.axis([0.0,1.01,0.0,1.01]) p1.set_ylabel("患者密度(人/10萬人)",fontsize=13) p1.set_xlabel("人口密度(人/平方千米)",fontsize=13) p1.set_title("人口密度—患者密度相關性",fontsize=13) for i,txt in enumerate(n): p1.annotate(txt,(rk_gy[i],hz_gy[i])) A1, B1 = optimize.curve_fit(f_1, rk_gy, hz_gy)[0] x1 = np.arange(0, 1, 0.01) y1 = A1*x1 + B1 p1.plot(x1, y1, "blue",label='一次擬合直線') x2 = np.arange(0, 1, 0.01) y2 = x2 p1.plot(x2, y2,'g--',label='y=x') p1.legend(loc='upper left',fontsize=13) # # plot the box tx0 = 0;tx1 = 0.1;ty0 = 0;ty1 = 0.2 sx = [tx0,tx1,tx1,tx0,tx0] sy = [ty0,ty0,ty1,ty1,ty0] p1.plot(sx,sy,"purple") p2.axis([0,0.1,0,0.2]) p2.set_ylabel("患者密度(人/10萬人)",fontsize=13) p2.set_xlabel("人口密度(人/平方千米)",fontsize=13) p2.set_title("人口密度—患者密度相關性",fontsize=13) for i,txt in enumerate(n): p2.annotate(txt,(rk_gy[i],hz_gy[i])) p2.plot(x1, y1, "blue",label='一次擬合直線') p2.plot(x2, y2,'g--',label='y=x') p2.legend(loc='upper left',fontsize=13) plt.show()if __name__ == '__main__': draw_cure("F:\醫學大數據課題\論文終稿修改\scientific report\返修\市區縣相關分析 _2231.xls")實現效果:
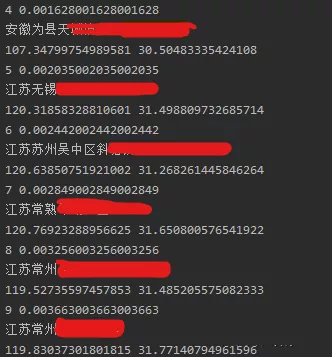
輸入:中文地址信息,例如安徽為縣天城鎮都督村沖裡18號
輸出:經緯度坐標,例如107.34799754989581 30.50483335424108
功能:根據中文地址信息獲取經緯度坐標
實現代碼:
import jsonfrom urllib.request import urlopen,quoteimport xlrddef readXLS(XLS_FILE,sheet0): rb= xlrd.open_workbook(XLS_FILE) rs= rb.sheets()[sheet0] return rsdef getlnglat(adress): url = 'http://api.map.baidu.com/geocoding/v3/?address=' output = 'json' ak = 'fdi11GHN3GYVQdzVnUPuLSScYBVxYDFK' add = quote(adress)#使用quote進行編碼 為了防止中文亂碼 # add=adress url2 = url + add + '&output=' + output + '&ak=' + ak req = urlopen(url2) res = req.read().decode() temp = json.loads(res) return tempdef getlatlon(sd_rs): nrows_sd_rs=sd_rs.nrows for i in range(4,nrows_sd_rs): # for i in range(4, 7): row=sd_rs.row_values(i) print(i,i/nrows_sd_rs) b = (row[11]+row[12]+row[9]).replace('#','號') # 第三列的地址 print(b) try: lng = getlnglat(b)['result']['location']['lng'] # 獲取經度並寫入 lat = getlnglat(b)['result']['location']['lat'] #獲取緯度並寫入 except KeyError as e: lng='' lat='' f_err=open('f_err.txt','a') f_err.write(str(i)+'\t') f_err.close() print(e) print(lng,lat) f_latlon = open('f_latlon.txt', 'a') f_latlon.write(row[0]+'\t'+b+'\t'+str(lng)+'\t'+str(lat)+'\n') f_latlon.close()if __name__=='__main__': # sle_xls_file = 'F:\醫學大數據課題\江蘇省SLE數據庫(兩次隨訪合並).xlsx' sle_xls_file = "F:\醫學大數據課題\數據副本\江蘇省SLE數據庫(兩次隨訪合並) - 副本.xlsx" sle_data_rs = readXLS(sle_xls_file, 1) getlatlon(sle_data_rs)結果展示:
到此這篇關於python數據分析之單因素分析線性擬合及地理編碼的文章就介紹到這了,更多相關python數據分析內容請搜索軟件開發網以前的文章或繼續浏覽下面的相關文章希望大家以後多多支持軟件開發網!