This article mainly explains Python Data separation of test cases in automated testing , Better manage test cases and code in automated testing , In addition, there is a portal for a series of articles below , It's still being updated , Interested partners can also go to check , Don't talk much , Let's have a look ~

Series articles :
Series articles 1:【Python automated testing 1】 meet Python The beauty of the
Series articles 2:【Python automated testing 2】Python Installation configuration and PyCharm Basic use
Series articles 3:【Python automated testing 3】 First knowledge of data types and basic syntax
Series articles 4:【Python automated testing 4】 Summary of string knowledge
Series articles 5:【Python automated testing 5】 List and tuple knowledge summary
Series articles 6:【Python automated testing 6】 Dictionary and collective knowledge summary
Series articles 7:【Python automated testing 7】 Data operator knowledge collection
Series articles 8:【Python automated testing 8】 Explanation of process control statement
Series articles 9:【Python automated testing 9】 Function knowledge collection
Series articles 10:【Python automated testing 10】 File basic operation
Series articles 11:【Python automated testing 11】 modular 、 Package and path knowledge collection
Series articles 12:【Python automated testing 12】 Knowledge collection of exception handling mechanism
Series articles 13:【Python automated testing 13】 class 、 object 、 Collection of attribute and method knowledge
Series articles 14:【Python automated testing 14】Python Basic and advanced exercises of automatic test
Series articles 15:【Python automated testing 15】unittest The core concept and function of test framework
As shown in the following code , When testing a function, we need to write test cases and assert , Test through the framework and related methods , This creates a problem , For a huge piece of software 、 In terms of the game , There may be tens of thousands of test cases , If there is a binding relationship between data and code , Obviously, there will be many disadvantages , For example, query 、 Change test data, etc , This means that the code and test data will be maintained together , The maintenance cost will increase with time and quantity , And interdependent .
So we need to distinguish data from code , Then separate the process and result , We call it data separation , Manage separately . Then the data separation of test cases , It means to distinguish use case data from code . If the test data needs to be modified or added , Then we only need to maintain the test data , The test case does not need to be changed .
""" It's all about 4 Knowledge content : 1、setUp Execute before test case 2、teardown Execute after test case 3、setUpClass Execute before testing class 4、teardownClass After testing the class, execute """
import unittest
def login(username=None, password=None):
if username is None or password is None:
return {
"code": 400, "msg": " The user name or password is empty " }
if username == " Meng Xiaotian " and password == 123456:
return {
"code": 200, "msg": " Login successful " }
return {
"code": 300, "msg": " Wrong user name or password " }
class TestLogin(unittest.TestCase):
def setUp(self) -> None:
""" Code that will be executed before each test case """
print(" Preparation before each test case ")
print(" Pretend to be connecting to the database ...")
def tearDown(self) -> None:
""" Code that will be executed after each test case , Whether the test case passes or not ,tearDown Will carry out """
print(" What needs to be done after each test case is executed ")
print(" Pretend to be disconnecting the database ")
@classmethod
def setUpClass(cls) -> None:
""" Each test class will be executed before """
print(" Each test class is executed only once before ")
@classmethod
def tearDownClass(cls) -> None:
""" After each class executes """
print(" Each test class is then executed once ")
def test_login_success(self):
username = " Meng Xiaotian "
password = 123456
expected = {
"code": 200, "msg": " Login successful "}
actual = login(username,password)
self.assertEqual(expected, actual) # Assert whether the expected result is equal to the actual result
def test_login_error(self):
username = " Meng Xiaotian "
password = 1234567
expected = {
"code": 1100, "msg": " Wrong user name or password " }
actual = login(username,password)
self.assertEqual(expected, actual)
The core of data separation is to separate data from code , Combined with what we learned before , We can store some test data in the form of list nested Dictionary , The converted code is :
""" TODO: Please note that , The following code is not the best way to optimize , Just to explain the knowledge content of data separation TODO: It will be gradually optimized in the future , Adopt a better strategy , Subsequent articles will explain """
import unittest
login_data = [
{
"username": " Meng Xiaotian ", "password": 123456, "expected": {
"code": 200, "msg": " Login successful "}},
{
"username": " Meng Xiaotian ", "password": 1234567, "expected": {
"code": 1100, "msg": " Wrong user name or password "}}
]
def login(username=None, password=None):
if username is None or password is None:
return {
"code": 400, "msg": " The user name or password is empty " }
if username == " Meng Xiaotian " and password == 123456:
return {
"code": 200, "msg": " Login successful " }
return {
"code": 300, "msg": " Wrong user name or password " }
class TestLogin(unittest.TestCase):
def setUp(self) -> None:
""" Code that will be executed before each test case """
print(" Preparation before each test case ")
print(" Pretend to be connecting to the database ...")
def tearDown(self) -> None:
""" Code that will be executed after each test case , Whether the test case passes or not ,tearDown Will carry out """
print(" What needs to be done after each test case is executed ")
print(" Pretend to be disconnecting the database ")
@classmethod
def setUpClass(cls) -> None:
""" Each test class will be executed before """
print(" Each test class is executed only once before ")
@classmethod
def tearDownClass(cls) -> None:
""" After each class executes """
print(" Each test class is then executed once ")
def test_login_success(self):
data = login_data[0]
username = data["username"]
password = data["password"]
expected = data["expected"]
actual = login(username,password)
self.assertEqual(expected, actual)
def test_login_error(self):
data = login_data[1]
username = data["username"]
password = data["password"]
expected = data["expected"]
actual = login(username,password)
self.assertEqual(expected, actual)
As shown in the above code , At present, the test data and code are separated , In this way, when we want to maintain test data or code, it will be more convenient , Although this way is not the most effective , But the main purpose is to let everyone first understand the concept of data separation , Will continue to optimize in subsequent articles .
Normally, we need module management , That is, the code belongs to a module (py file ), The data belongs to a module , So we actually data The data is not placed in the code module , It should be a new data.py Module files for , Call by importing , This is also true in real projects , The above code is convenient for novices to understand :
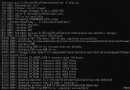
E:\TestingSoftware\Python3.10.1(64x)\python.exe "E:\TestingSoftware\PyCharm\PyCharm Community Edition 2021.3\plugins\python-ce\helpers\pycharm\_jb_unittest_runner.py" --target test_login.TestLogin.test_login_error
Testing started at 10:49 ...
Launching unittests with arguments python -m unittest test_login.TestLogin.test_login_error in E:\TestingSoftware\Python3.10.1(64x)\PythonProject\CSDN Automated test series _ Section 1 _Python Basic grammar 1
Each test class is executed only once before
Preparation before each test case
Pretend to be connecting to the database ...
What needs to be done after each test case is executed
Pretend to be disconnecting the database
{
'code': 300, 'msg': ' Wrong user name or password '} != {
'code': 1100, 'msg': ' Wrong user name or password '}
Expected :{
'code': 1100, 'msg': ' Wrong user name or password '}
Actual :{
'code': 300, 'msg': ' Wrong user name or password '}
<Click to see difference>
Traceback (most recent call last):
File "E:\TestingSoftware\Python3.10.1(64x)\PythonProject\CSDN Automated test series _ Section 1 _Python Basic grammar 1\test_login.py", line 55, in test_login_error
self.assertEqual(expected, actual)
AssertionError: {
'code': 1100, 'msg': ' Wrong user name or password '} != {
'code': 300, 'msg': ' Wrong user name or password '}
- {
'code': 1100, 'msg': ' Wrong user name or password '}
? ^^
+ {
'code': 300, 'msg': ' Wrong user name or password '}
? ^
Each test class is then executed once
Ran 1 test in 0.005s
FAILED (failures=1)
Process finished with exit code 1
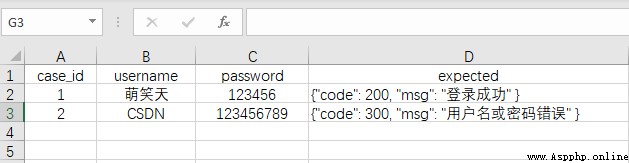
""" The process of data separation : 1、excel Write test cases 2、 adopt Python Read excel( The format of the dictionary read out is the nested list : [{}, {}, {}] 3、 Import test case functions I know from the above : I need one for now excel Version of the test case , And pass Python Just read it """
Create a... Under the path case.xlsx, Store test case data
openpyxl Belongs to the third party library , Therefore, we need to install , It has been installed and will be updated directly 
As shown in the following code : We use functions to encapsulate , Use openpyxl Conduct excel Data reading
""" Python operation excel The idea of : 1、 To open the first excel file 2、 Select the corresponding table tab 3、 Read the corresponding cell data 4、 Realize certain operations through data 5、 close excel file """
import openpyxl # Used exclusively to deal with excel The library of forms ,openpyxl Have pandas Characteristics of , And belongs to lightweight Library , Don't like pandas The same is more complicated , More advantage
from openpyxl.worksheet.worksheet import Worksheet
def read_excel(file_path, sheet_name ):
""" Read excel Function of """
workbook_data = openpyxl.load_workbook(file_path) # Open name as case.xlsx Of excel file
sheet: Worksheet = workbook_data[sheet_name] # The signature of the page is login, Locate the login Tab , To specify sheet The type is Worksheet
# """ If we want to get the data of a cell , You can use this method , But often there is a huge amount of data in a table , We don't get... In this way """
# cell = sheet.cell(row=1, column=1) # Get cell data ,row For the line ,column Column , The cells represented in the code are the first row and the first column
# print(cell.value) # Get the data of the first row and the first column
""" The more recommended method is to get all the data , Because the data obtained is not of list type , We need further data conversion """
values = list(sheet.values)
workbook_data.close() # Close file
return values
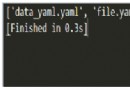
data = read_excel("case.xlsx", "login")
print(data)

Mentioned before , The data of the test case is in the form of list nested dictionary , The printed data is in the form of list nested tuples , Not as expected , So further conversion is needed :
""" Python operation excel The idea of : 1、 To open the first excel file 2、 Select the corresponding table tab 3、 Read the corresponding cell data 4、 Realize certain operations through data 5、 close excel file """
import openpyxl # Used exclusively to deal with excel The library of forms ,openpyxl Have pandas Characteristics of , And belongs to lightweight Library , Don't like pandas The same is more complicated , More advantage
from openpyxl.worksheet.worksheet import Worksheet
def read_excel(file_path, sheet_name ):
""" Read excel Function of """
workbook_data = openpyxl.load_workbook(file_path) # Open name as case.xlsx Of excel file
sheet: Worksheet = workbook_data[sheet_name] # The signature of the page is login, Locate the login Tab , To specify sheet The type is Worksheet
# """ If we want to get the data of a cell , You can use this method , But often there is a huge amount of data in a table , We don't get... In this way """
# cell = sheet.cell(row=1, column=1) # Get cell data ,row For the line ,column Column , The cells represented in the code are the first row and the first column
# print(cell.value) # Get the data of the first row and the first column
""" The more recommended method is to get all the data , Because the data obtained is not of list type , We need further data conversion """
values = list(sheet.values)
workbook_data.close() # Close file
title = values[0]
rows = values[1:]
new_rows = [dict(zip(title, row)) for row in rows]
return new_rows
data = read_excel("case.xlsx", "login")
print(data)

All right. ~ The above is all the content shared in this article , Have you learned ? I hope I can help you !