Hzy The blog of
Today, let's talk about the front 5 Turn off , What have you met .
See the picture , Ask us to find out 2 Of 38 Power
print(2**38)# 274877906944
so easy, We copied the results to .html You can go to the next level .
It's also a picture , You can see
Observe the pattern , It seems that they all press 26 Letters , The result of counting two digits forward , Here is another paragraph , Let's translate it with our rules .
## The following text
instr = "abcdefghijklmnopqrstuvwxyz"
outstr = "cdefghijklmnopqrstuvwxyzab"
strans = str.maketrans(instr,outstr)
test = "g fmnc wms bgblr rpylqjyrc gr zw fylb. rfyrq ufyr amknsrcpq ypc dmp. bmgle gr gl zw fylb gq glcddgagclr ylb rfyr'q ufw rfgq rcvr gq qm jmle. sqgle qrpgle.kyicrpylq() gq pcamkkclbcb. lmu ynnjw ml rfc spj."
print(test.translate(strans))
# http://www.pythonchallenge.com/pc/def/map.html
print("map".translate(strans))
# The next link is :http://www.pythonchallenge.com/pc/def/ocr.html
The second level is a book , Let's right click , Open the page source code to view , I found a comment below , Ask us to find in a pile of garbled code
Key letters.
import requests
import re
content = requests.get('http://www.pythonchallenge.com/pc/def/ocr.html').text
anwser = re.sub('\n|\t|\r', '', content) # Remove some spaces
anwser = re.findall("find.*?<!--(.*?)-->", anwser) # Take out the notes
anwser = list(str(anwser)) # Convert to list
key = (s for s in anwser if s.isalpha()) # Find the letters inside
print("".join(key))
# result equality
The first 3 Guan Hedi 2 Close very much , We directly open the page source code .
import re
import requests
content = requests.get('http://www.pythonchallenge.com/pc/def/equality.html').text
notes = re.search('<!--(.*?)-->', re.sub('\n', '', content))
if notes:
ret = re.findall('[a-z]+[A-Z]{3}([a-z])[A-Z]{3}[a-z]+', notes.group())
print(ret)
# answer :linkedlist
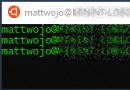
This question , There is also a graph , Then we can click in , Found only a string of characters
Then in the process of writing, you will find the following problems
Yes. Divide by two and keep going. You need to divide the number by 2, Instead of using regular direct matching
There maybe misleading numbers in the text. One example is 82683. Look only for the next nothing and the next nothing is 63579
Regular will match two numbers , You have to decide which number you need .
import requests
import re
url = "http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=77864"
text = requests.get(url).text
for i in range(400):
number_list = re.findall("\d+", text)
if len(number_list) == 1:
url = "http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=" + number_list[0]
elif len(number_list) == 0:
number = url.split('nothing=')[1]
url = "http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=" + str(int(number) / 2)
elif len(number_list) == 2:
url = "http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=" + number_list[0]
content = requests.get(url).text
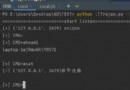
if content.find("You've been misleaded to here.") != -1:
print(" The correct number is {}".format(number_list[1]))
url = "http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=" + number_list[1]
r = requests.get(url)
if r.status_code == 200:
text = r.text
print(str(i) + ": ", text)
# http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=66831 Your next answer :peak.html