本文章主要會講解selenium中的一些高級定位元素的方式,除此之外下方有系列文章的傳送門,還在持續更新中,感興趣的小伙伴也可以前往查看,話不多說,讓我們一起看看吧~

系列文章:
系列文章1:【Python自動化測試1】遇見Python之美
系列文章2:【Python自動化測試2】Python安裝配置及PyCharm基本使用
系列文章3:【Python自動化測試3】初識數據類型與基礎語法
系列文章4:【Python自動化測試4】字符串知識總結
系列文章5:【Python自動化測試5】列表與元組知識總結
系列文章6:【Python自動化測試6】字典與集合知識總結
系列文章7:【Python自動化測試7】數據運算符知識合集
系列文章8:【Python自動化測試8】流程控制語句講解
系列文章9:【Python自動化測試9】函數知識合集
系列文章10:【Python自動化測試10】文件基礎操作
系列文章11:【Python自動化測試11】模塊、包與路徑知識合集
系列文章12:【Python自動化測試12】異常處理機制知識合集
系列文章13:【Python自動化測試13】類、對象、屬性與方法知識合集
系列文章14:【Python自動化測試14】Python自動化測試基礎與進階練習題
系列文章15:【Python自動化測試15】unittest測試框架的核心概念與作用
系列文章16:【Python自動化測試16】測試用例數據分離
系列文章17:【Python自動化測試17】openpyxl二次封裝與數據驅動
系列文章18:【Python自動化測試18】配置文件解析與實際應用
系列文章19:【Python自動化測試19】日志系統logging講解
系列文章20:【Python自動化測試20】接口自動化測試框架模型搭建
系列文章21:【Python自動化測試21】接口自動化測試實戰一_接口概念、項目簡介及測試流程問答
系列文章22:【Python自動化測試22】接口自動化測試實戰二_接口框架修改及用例優化
系列文章23:【Python自動化測試23】接口自動化測試實戰三_動態參數化與數據偽造
系列文章24:【Python自動化測試24】接口自動化測試實戰四_Python操作數據庫
系列文章25:【Python自動化測試25】接口自動化測試實戰五_數據庫斷言、接口關聯及相關管理優化
系列文章26:【Python自動化測試26】接口自動化測試實戰六_pytest框架+allure講解
系列文章27:【Python自動化測試27】Web自動化測試理論、環境搭建及常見操作
系列文章28:【Python自動化測試28】html基礎語法
在正式進入Xpath元素定位的講解前,大家需要基本的清楚元素定位的三大原則:
""" 元素定位三大原則: 1、無論什麼方式查找元素,確保你的元素是唯一的且非動態元素 2、如果通過元素找到兩個或以上元素: (1)加索引 (2)采用復合條件 name and class_name and xxx 3、無論通過什麼方式查找元素,如果你發現該元素是動態變化元素,不要使用該元素 (1)包含數字的元素,很可能是動態元素, p1、table2、li_3 (2)屬性值中包括一串類似token的字符串 """
Xpath即為XML路徑語言(XML Path Language),它是一種用來確定XML文檔中某部分位置的語言,可以用在html的使用
Xpath可以直接在浏覽器中進行復制,以谷歌文本搜索輸入框為例: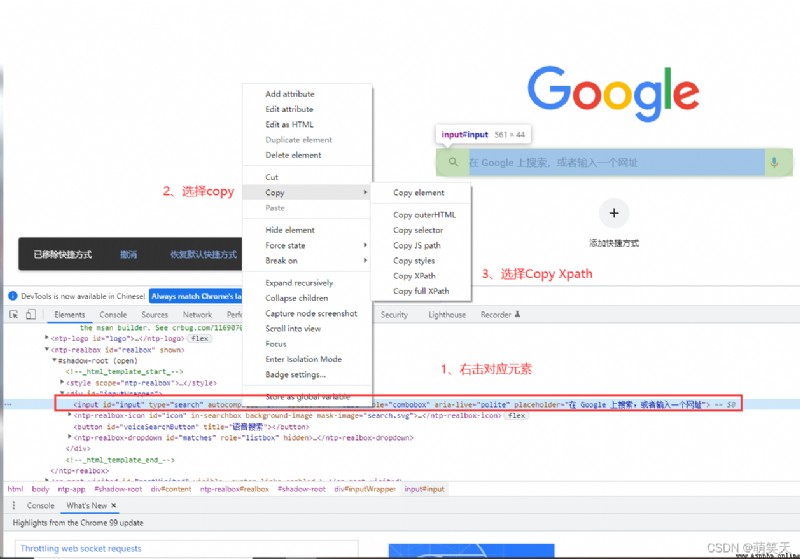
""" copy結果: Xpath -> 相對路徑 //*[@id="input"] "full Xpath" -> 絕對路徑 /html/body/ntp-app//div/ntp-realbox//div/input """
浏覽器支持復制Xpath為何我們還需要去學習,原因很簡單,不能夠支持100%的應用場景,在某些場景使用復制的Xpath會失效,無法定位到元素,最好的方式還是自行手寫,能夠保證精准度的同時,能夠縮小Xpath語句的長短。
F12的狀態下使用快捷鍵ctrl+f,在下方會出現搜索框,可以在搜索框中輸入Xpath語句: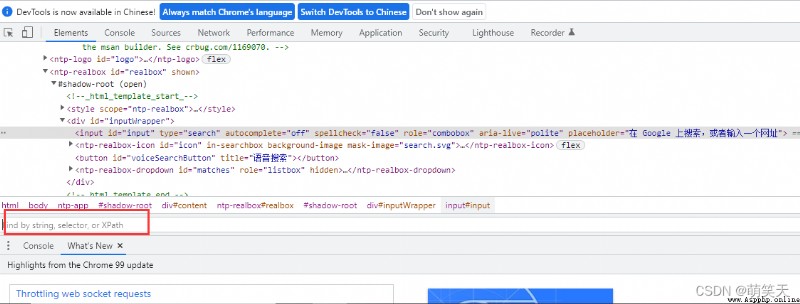
如上圖所示,如果我們想通過Xpath來定位文本輸入框,那麼語句為://input[@id="input"] ,讓我們簡單的進行解析:
""" //input[@id="input"] // -> 代表絕對路徑 input -> 代表找到一個input標簽 [@id="input"] -> 找到屬性為id,值為input 結合起來是:絕對路徑的方式查找input標簽下屬性為id,值為input的元素 """
順帶一提,如果能夠使用相對路徑盡可能不要使用絕對路徑:
""" 為何要使用相對路徑: 1、相對路徑更簡潔,美觀性高於絕對路徑,且手寫方便 2、前端人員修改了數據後,相對路徑可能不需要修改,但絕對路徑99.9%是需要修改的 """
在以百度界面舉例,我們要想定位到文本輸入框可以使用://input[@name="wd"],因為在前端name很常見,假設在這個頁面中有多個name屬性元素,那麼目前是無法精確找到我們想要的元素,這時可以通過and 來進行條件組合,例如://input[@name="wd" and @class="s_ipt" and @id="kw"]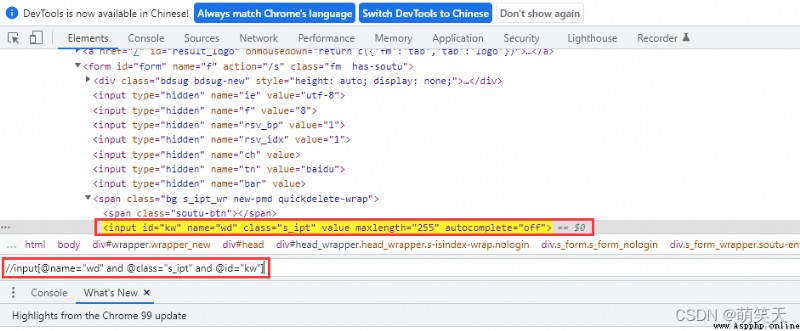
如果你項目的實踐碰巧到了很多個and後還是有重復因素,那麼你可以通過父類方式去定位://span//input[@name="wd" and @class="s_ipt" and @id="kw"]
除此以外,還可以增加組合條件://span[@name=" "]/input[@name=' ']
如果你不確定它的標簽,但清楚它的屬性,那麼可以使用*號通配符來進行查詢://*[@name="wd"]
如果你發現源代碼中幾乎沒有能夠用於可定位的屬性,那也可以通過下級屬性來尋找上級父標簽,兩個點則代表返回上一級://*[@name="wd"]/..
如果有一個下拉列表,要定位到列表內的元素,那麼可以使用索引進行定位,這裡需要注意的是索引是從1開始的(//a[@class="btn btn-sm btn-primary"])[1]
我們還可以通過文本進行定位,如果一個網頁中例如百度界面,有新聞、直播等文本字眼,可以使用text()://div[@id="s-top-left"]/a[text()="視頻"]
有些時候文本比較長,可能還有多個空格,那麼也許會因為這些因素無法成功定位,那麼當文本較長時可以直接使用包含的方式定位,也可以在屬性比較復雜的情況下使用contains()://div[@id="s-top-left"]/a[contains(text(),"視頻")]//div[@id="s-top-left"]/a[contains(@class,"s_ipt")]
軸運算也是在元素不方便定位等時候使用的,具體的語法與Xpath類似,有些許差別,軸運算相對於Xpath就是父親對兒子,基本上完勝,可以說沒有什麼元素不能通過軸運算找到,如果有,那一定是我孤陋寡聞了,讓我們看看基本的例子:
//input[@name="wd"]//parent::span,意思是:通過name屬性和wd元素,尋找父級目錄下的span標簽,類似的還有:
//input[@name="wd"]//ancestor::form
直接上語法://input[@name="wd"]//preceding-sibling::span
直接上語法://input[@name="wd"]//following-sibling::span
隨著時間的推移,大家更喜歡使用Xpath進行定位,在碰到較難定位的情況下,也會選擇使用軸運算進行定位,但CSS選擇器也具有一定的定位優勢,雖然大多數情況下可以使用Xpath以及軸運算完成,但CSS選擇器的方式也需要進行了解,基礎語法如下所示:
(1)#kw – 代表:id=kw
(2).s_ipt – 代表:class=s_ipt
(3)[id=kw]
(4)[class="s_ipt"]
好啦~以上就是本次文章分享的全部內容啦,你學會了嗎?希望能給大家帶來幫助哦!