本文章主要講解Python自動化測試中openpyxl的二次封裝,在自動化測試中能夠更好的管理測試用例以及代碼,除此之外下方有系列文章的傳送門,還在持續更新中,感興趣的小伙伴也可以前往查看,話不多說,讓我們一起看看吧~

系列文章:
系列文章1:【Python自動化測試1】遇見Python之美
系列文章2:【Python自動化測試2】Python安裝配置及PyCharm基本使用
系列文章3:【Python自動化測試3】初識數據類型與基礎語法
系列文章4:【Python自動化測試4】字符串知識總結
系列文章5:【Python自動化測試5】列表與元組知識總結
系列文章6:【Python自動化測試6】字典與集合知識總結
系列文章7:【Python自動化測試7】數據運算符知識合集
系列文章8:【Python自動化測試8】流程控制語句講解
系列文章9:【Python自動化測試9】函數知識合集
系列文章10:【Python自動化測試10】文件基礎操作
系列文章11:【Python自動化測試11】模塊、包與路徑知識合集
系列文章12:【Python自動化測試12】異常處理機制知識合集
系列文章13:【Python自動化測試13】類、對象、屬性與方法知識合集
系列文章14:【Python自動化測試14】Python自動化測試基礎與進階練習題
系列文章15:【Python自動化測試15】unittest測試框架的核心概念與作用
系列文章16:【Python自動化測試16】測試用例數據分離
基於上一次16章節的代碼,我們可以繼續對代碼進行優化封裝,封裝後的代碼會更加高效,主要分為三個文件:
(1)test_login.py
# 測試文件
(2)login_function# 存儲被測函數
(3)excel# excel表格讀取
(4)login_case.xlsx# 測試用例數據
優化後的代碼如下所示(如果沒有看過16章的同學,建議先去閱讀16章):
"""被測函數:login_function"""
def login(username=None, password=None):
if username is None or password is None:
return {
"code": 400, "msg": "用戶名或密碼為空"}
if username == "萌笑天" and password == "123456":
return {
"code": 200, "msg": "登錄成功"}
return {
"code": 300, "msg": "用戶名或密碼錯誤"}
"""測試文件:test_login.py"""
import unittest
from excel import read_excel # 導入read_excel的函數,以使用對應的功能
from login_function import login
# 獲取excel數據
login_data = read_excel("login_case.xlsx", "login")
class TestLogin(unittest.TestCase):
def test_login_success(self):
# 通過索引為0,找到第一組測試數據
data_info = login_data[0]
# 取出測試數據當中的data字段
user_info = eval(data_info["data"])
username = user_info["username"]
password = user_info["password"]
expected = eval(data_info["expected"])
actual = login(username, password)
self.assertEqual(expected, actual)
"""表格讀取:excel.py"""
""" Python操作excel的思路: 1、先打開excel文件 2、選擇對應表格頁簽 3、讀取對應單元格數據 4、通過數據實現一定的操作 5、關閉excel文件 """
import openpyxl # 專門用於處理excel表格的庫,openpyxl擁有pandas的特性,並屬於輕量級庫,不會像pandas一樣更加復雜,更具優勢
from openpyxl.worksheet.worksheet import Worksheet
def read_excel(file_path, sheet_name ):
"""讀取excel的函數"""
workbook_data = openpyxl.load_workbook(file_path) # 打開名稱為case.xlsx的excel文檔
sheet: Worksheet = workbook_data[sheet_name] # 頁簽名為login,定位到login頁簽,指明sheet類型為Worksheet
# """如果我們想要獲取某一個單元格的數據,可以使用這個方式,但往往一個表格中有龐大的數據,我們並非通過這樣的方式獲取"""
# cell = sheet.cell(row=1, column=1) # 獲取單元格數據,row為行,column為列,代碼中表示的為第一行第一列的單元格
# print(cell.value) # 獲取第一行第一列的數據
"""更推薦的獲取方法是獲取所有數據,因為獲取的數據並非列表類型,我們還需要進一步進行數據轉換"""
values = list(sheet.values)
workbook_data.close() # 關閉文件
title = values[0]
rows = values[1:]
new_rows = [dict(zip(title, row)) for row in rows]
return new_rows
data = read_excel("login_case.xlsx", "login")
print(data)
測試用例數據如下所示:
執行結果如下所示,測試通過: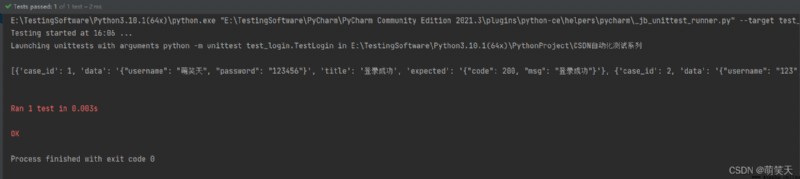
當有過多的測試函數數據時我們需要通過循環去遍歷,也就是for循環遍歷,雖然更加便捷可以省略過多的測試函數編寫,當仍然會出現一些新問題,Python程序從上往下執行,並逐條進行excel的數據讀取,一旦出現報錯,會終止程序運行,如下所示,會告知預期結果與實際結果不符,那麼程序就會終止運行了(代碼中沒有直接使用for循環):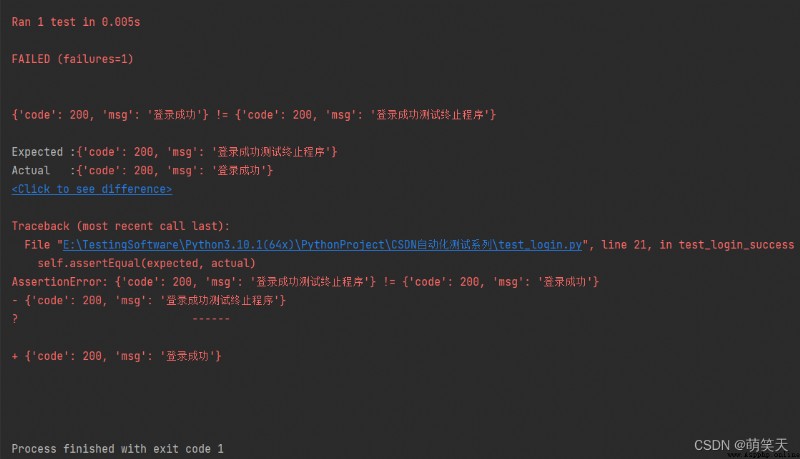
思想:數據驅動(data driven testing)是一種將測試數據(輸入,和期望輸出)從只包含測試邏輯的測試腳本代碼中區別開的方法,簡單點說也就是數據分離,數據驅動也是使用不同的數據達到想要的目的。
實現:通過導入數據驅動(DDT)的方式,進行數據驅動:
注意:特別需要注意的就是,如果在代碼中加了裝飾器實現了數據驅動後,執行代碼需要在空白行執行,否則會出現AttributeError的報錯,需要牢記!
意義:
(1)測試邏輯高,代碼復用率高,可以被多條測試數據復用,同時可以提高編寫效率。
(2)異常排查率較高,測試框架依據測試數據,每條數據生成測試用例,用例執行過程相互隔離,數據驅動可以讓測試用例數據更加獨立,具有獨立性,每一個測試用例相互之間不會影響。
(3)代碼的可維護性高,清晰的測試框架,提高可讀性與可維護性。
import unittest
from excel import read_excel # 導入read_excel的函數,以使用對應的功能
from login_function import login
from unittestreport import ddt, list_data # unittestreport是一個綜合報告輸出、ddt等多個內容的庫
# 獲取excel數據
login_data = read_excel("login_case.xlsx", "login")
# 測試類上使用ddt,以表示使用數據驅動
@ddt
class TestLogin(unittest.TestCase):
# 如果你想在哪個函數上使用數據驅動,那麼就在函數上增加list_data
@list_data(login_data)
def test_login_success(self, data_info):
# 通過索引為0,找到第一組測試數據
data_info = login_data[0]
# 取出測試數據當中的data字段
user_info = eval(data_info["data"])
username = user_info["username"]
password = user_info["password"]
expected = eval(data_info["expected"])
actual = login(username, password)
self.assertEqual(expected, actual)
好啦~以上就是本次文章分享的全部內容啦,你學會了嗎?希望能給大家帶來幫助哦!