This article mainly explains Python Automated testing openpyxl Secondary packaging of , Better manage test cases and code in automated testing , In addition, there is a portal for a series of articles below , It's still being updated , Interested partners can also go to check , Don't talk much , Let's have a look ~

Series articles :
Series articles 1:【Python automated testing 1】 meet Python The beauty of the
Series articles 2:【Python automated testing 2】Python Installation configuration and PyCharm Basic use
Series articles 3:【Python automated testing 3】 First knowledge of data types and basic syntax
Series articles 4:【Python automated testing 4】 Summary of string knowledge
Series articles 5:【Python automated testing 5】 List and tuple knowledge summary
Series articles 6:【Python automated testing 6】 Dictionary and collective knowledge summary
Series articles 7:【Python automated testing 7】 Data operator knowledge collection
Series articles 8:【Python automated testing 8】 Explanation of process control statement
Series articles 9:【Python automated testing 9】 Function knowledge collection
Series articles 10:【Python automated testing 10】 File basic operation
Series articles 11:【Python automated testing 11】 modular 、 Package and path knowledge collection
Series articles 12:【Python automated testing 12】 Knowledge collection of exception handling mechanism
Series articles 13:【Python automated testing 13】 class 、 object 、 Collection of attribute and method knowledge
Series articles 14:【Python automated testing 14】Python Basic and advanced exercises of automatic test
Series articles 15:【Python automated testing 15】unittest The core concept and function of test framework
Series articles 16:【Python automated testing 16】 Test case data separation
Based on the last 16 Chapter code , We can continue to optimize and encapsulate the code , The encapsulated code will be more efficient , It is mainly divided into three documents :
(1)test_login.py
# The test file
(2)login_function# Store the function under test
(3)excel# excel Table reading
(4)login_case.xlsx# Test case data
The optimized code is as follows ( If you haven't seen 16 Zhang's classmates , It is suggested to read first 16 Chapter ):
""" The function under test :login_function"""
def login(username=None, password=None):
if username is None or password is None:
return {
"code": 400, "msg": " The user name or password is empty "}
if username == " Meng Xiaotian " and password == "123456":
return {
"code": 200, "msg": " Login successful "}
return {
"code": 300, "msg": " Wrong user name or password "}
""" The test file :test_login.py"""
import unittest
from excel import read_excel # Import read_excel Function of , To use the corresponding function
from login_function import login
# obtain excel data
login_data = read_excel("login_case.xlsx", "login")
class TestLogin(unittest.TestCase):
def test_login_success(self):
# By indexing 0, Find the first set of test data
data_info = login_data[0]
# Take out... From the test data data Field
user_info = eval(data_info["data"])
username = user_info["username"]
password = user_info["password"]
expected = eval(data_info["expected"])
actual = login(username, password)
self.assertEqual(expected, actual)
""" Table reading :excel.py"""
""" Python operation excel The idea of : 1、 To open the first excel file 2、 Select the corresponding table tab 3、 Read the corresponding cell data 4、 Realize certain operations through data 5、 close excel file """
import openpyxl # Used exclusively to deal with excel The library of forms ,openpyxl Have pandas Characteristics of , And belongs to lightweight Library , Don't like pandas The same is more complicated , More advantage
from openpyxl.worksheet.worksheet import Worksheet
def read_excel(file_path, sheet_name ):
""" Read excel Function of """
workbook_data = openpyxl.load_workbook(file_path) # Open name as case.xlsx Of excel file
sheet: Worksheet = workbook_data[sheet_name] # The signature of the page is login, Locate the login Tab , To specify sheet The type is Worksheet
# """ If we want to get the data of a cell , You can use this method , But often there is a huge amount of data in a table , We don't get... In this way """
# cell = sheet.cell(row=1, column=1) # Get cell data ,row For the line ,column Column , The cells represented in the code are the first row and the first column
# print(cell.value) # Get the data of the first row and the first column
""" The more recommended method is to get all the data , Because the data obtained is not of list type , We need further data conversion """
values = list(sheet.values)
workbook_data.close() # Close file
title = values[0]
rows = values[1:]
new_rows = [dict(zip(title, row)) for row in rows]
return new_rows
data = read_excel("login_case.xlsx", "login")
print(data)
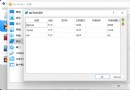
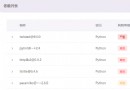
The test case data is as follows :
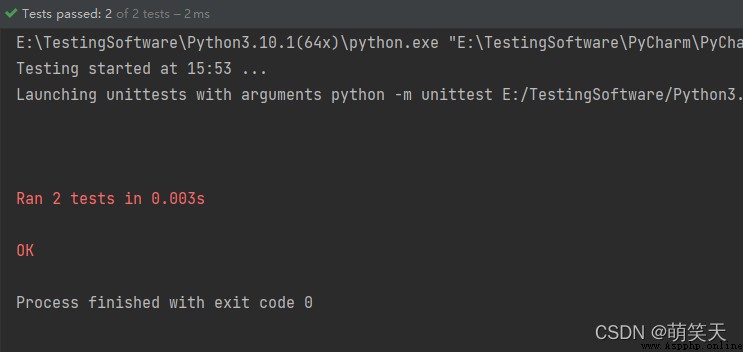
The results are shown below , The test passed :
When there is too much test function data, we need to traverse through the loop , That is to say for Loop traversal , Although it is more convenient, you can omit too many test functions , When there are still some new problems ,Python The program runs from top to bottom , And proceed one by one excel Data read from , Once an error is reported , Will terminate the program , As shown below , Will inform that the expected results are inconsistent with the actual results , Then the program will stop running ( There is no direct use of... In the code for loop ):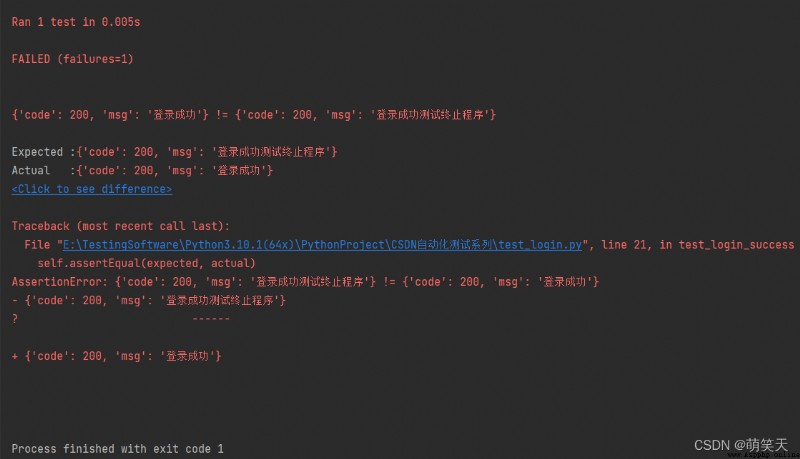
thought : Data driven (data driven testing) Is a way to test data ( Input , And the expected output ) A way to distinguish from test script code that contains only test logic , Simply put, it means data separation , Data driven also uses different data to achieve the desired purpose .
Realization : Data driven by importing (DDT) The way , Data driven :
Be careful : What needs special attention is , If you add a decorator to the code and realize data-driven , The execution code needs to be executed on a blank line , Otherwise, there will be present AttributeError The error of , It needs to be remembered !
significance :
(1) Test logic is high , High code reuse rate , It can be reused by multiple test data , At the same time, it can improve the writing efficiency .
(2) The abnormal troubleshooting rate is high , The test framework is based on test data , Generate test cases for each data , Use case execution processes are isolated from each other , Data driven can make test case data more independent , It is independent , Each test case will not affect each other .
(3) The maintainability of the code is high , Clear test framework , Improve readability and maintainability .
import unittest
from excel import read_excel # Import read_excel Function of , To use the corresponding function
from login_function import login
from unittestreport import ddt, list_data # unittestreport Is a comprehensive report output 、ddt And so on
# obtain excel data
login_data = read_excel("login_case.xlsx", "login")
# Use... On test classes ddt, To indicate the use of data-driven
@ddt
class TestLogin(unittest.TestCase):
# If you want to use data-driven on which function , Then add... To the function list_data
@list_data(login_data)
def test_login_success(self, data_info):
# By indexing 0, Find the first set of test data
data_info = login_data[0]
# Take out... From the test data data Field
user_info = eval(data_info["data"])
username = user_info["username"]
password = user_info["password"]
expected = eval(data_info["expected"])
actual = login(username, password)
self.assertEqual(expected, actual)
All right. ~ The above is all the content shared in this article , Have you learned ? I hope I can help you !